PODS (Personal Object Discrimination Suite)
收藏arXiv2024-12-21 更新2024-12-24 收录
下载链接:
https://personalized-rep.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
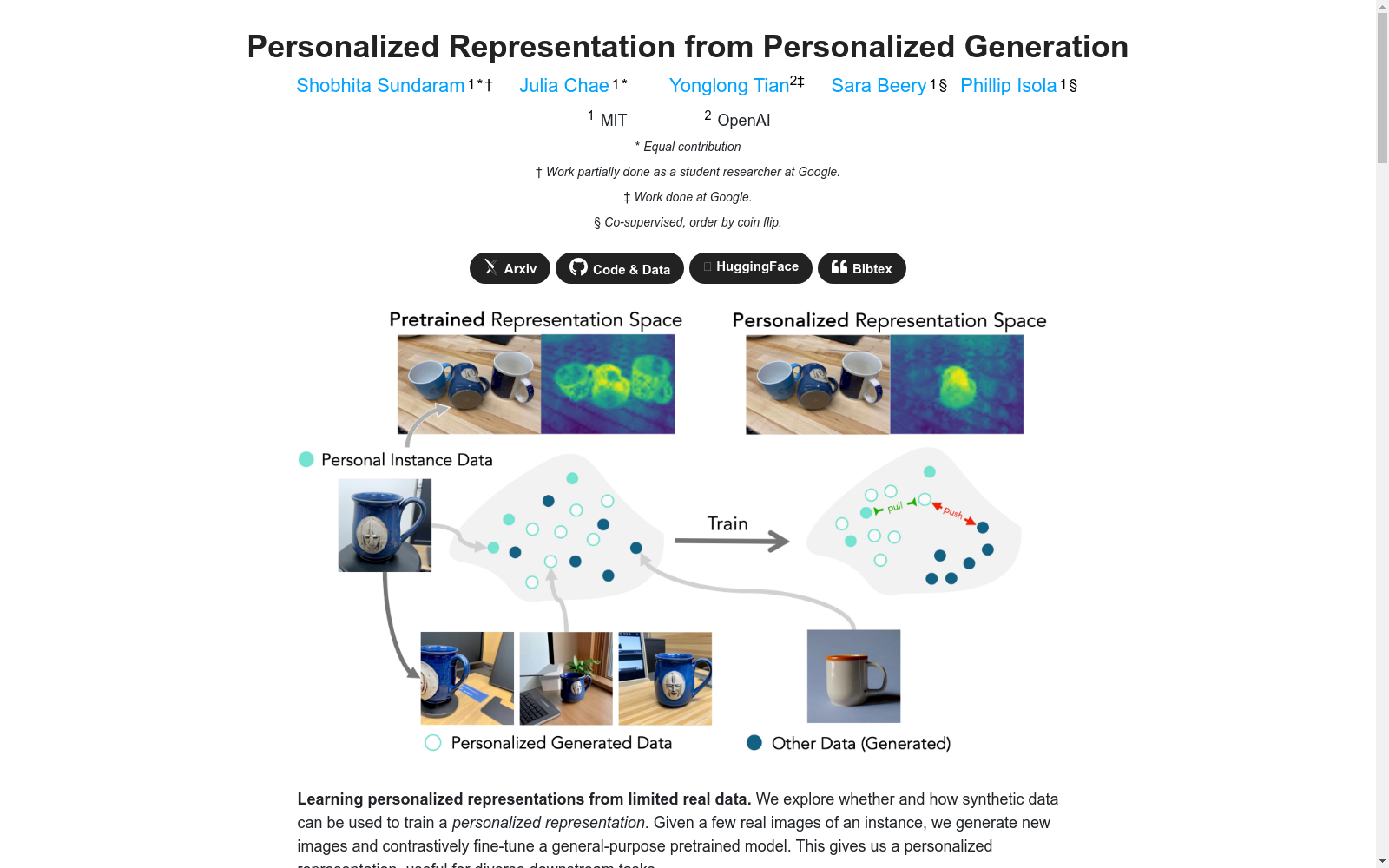
PODS(Personal Object Discrimination Suite)是一个专门为个性化对象识别任务设计的数据集,由麻省理工学院和OpenAI的研究团队创建。该数据集包含100个常见的个人和家庭对象,旨在支持实例级别的分类、检索、检测和分割任务。数据集的创建过程利用了生成模型和对比学习方法,通过少量真实图像生成合成数据,从而在数据稀缺的情况下训练个性化表示。PODS的应用领域主要集中在个性化视觉任务,旨在解决数据稀缺和细粒度识别的问题,特别是在用户特定对象的检测和分割任务中表现出色。
PODS (Personal Object Discrimination Suite) is a dataset specifically designed for personalized object recognition tasks, developed by research teams from the Massachusetts Institute of Technology (MIT) and OpenAI. This dataset includes 100 common personal and household objects, and is intended to support instance-level classification, retrieval, detection and segmentation tasks. The construction of PODS leverages generative models and contrastive learning methods, generating synthetic data from a small number of real images to train personalized visual representations in data-scarce scenarios. The main application areas of PODS focus on personalized vision tasks, aiming to address the challenges of data scarcity and fine-grained recognition, and it delivers outstanding performance particularly in user-specific object detection and segmentation tasks.
提供机构:
麻省理工学院,OpenAI
创建时间:
2024-12-21
搜集汇总
数据集介绍
构建方式
PODS数据集通过结合真实图像和生成图像构建,旨在解决个性化视觉任务中的数据稀缺问题。该数据集包含100个日常物品,分为5个类别,每个物品有3张真实图像用于训练,其余图像通过生成模型(如DreamBooth)生成。生成过程中,使用了文本到图像(T2I)扩散模型,通过对比学习方法对预训练模型进行微调,以学习个性化的表示空间。
使用方法
PODS数据集可用于多种下游任务,包括分类、检索、检测和分割。用户可以通过对比学习方法对预训练模型进行微调,利用生成数据和真实数据进行个性化表示学习。数据集的多样性和细粒度特性使其适用于需要高精度识别的个性化视觉任务,如宠物识别或日常物品的细粒度分类。
背景与挑战
背景概述
PODS(Personal Object Discrimination Suite)数据集由麻省理工学院(MIT)和OpenAI的研究人员共同开发,旨在解决个性化视觉任务中的细粒度和数据稀缺问题。该数据集的核心研究问题是如何利用合成数据从有限的实际图像中学习个性化的视觉表示,以便在多样化的下游任务中灵活应用。PODS数据集的构建基于T2I扩散模型,通过生成个性化的图像数据来增强模型的表示能力。该数据集的引入不仅为个性化视觉生成提供了新的评估基准,还为个性化表示学习领域带来了重要的研究价值。
当前挑战
PODS数据集面临的主要挑战包括:1) 数据稀缺性,用户通常只能提供少量实际图像,这使得模型训练变得困难;2) 细粒度识别,例如识别特定个体而非类别,这对模型的表示能力提出了更高的要求。此外,构建过程中还面临合成数据的质量控制问题,如何生成既多样又忠实于目标对象的图像是一个关键挑战。最后,不同生成模型引入的偏差和局限性也会影响最终的表示效果,如何平衡生成数据的多样性和保真度是另一个亟待解决的问题。
常用场景
经典使用场景
PODS数据集的经典使用场景主要集中在个性化视觉任务中,特别是在数据稀缺且任务细粒度的情况下。该数据集通过结合生成模型生成的合成数据,能够有效训练个性化表示,适用于从识别到分割等多种下游任务。例如,用户可以仅提供少量真实图像,利用PODS数据集中的合成数据进行对比微调,从而学习到针对特定对象的个性化表示。
解决学术问题
PODS数据集解决了在数据稀缺和细粒度任务中的个性化视觉表示学习问题。传统的视觉模型在处理细粒度任务时往往表现不佳,尤其是在标注数据有限的情况下。PODS通过引入个性化生成数据,使得模型能够在仅使用少量真实数据的情况下,学习到针对特定对象的表示,从而显著提升了在分类、检索、检测和分割等任务中的表现。
实际应用
PODS数据集在实际应用中具有广泛的潜力,特别是在需要个性化视觉模型的场景中。例如,在智能家居系统中,用户可以通过提供少量个人物品的图像,系统能够自动识别和区分这些物品;在医疗领域,个性化模型可以帮助医生快速识别和分类特定的医疗设备或样本。此外,PODS还可以应用于隐私保护场景,用户可以在不共享数据的情况下,训练个性化的识别模型。
数据集最近研究
最新研究方向
PODS数据集的最新研究方向集中在个性化视觉表示学习,特别是在数据稀缺和细粒度识别任务中。研究者们探索了如何利用生成模型生成的合成数据来训练个性化表示,以应对现实世界中数据不足的问题。通过对比学习方法,研究展示了在分类、检索、检测和分割等下游任务中,个性化表示的显著性能提升。此外,研究还分析了生成数据的质量对表示学习的影响,并提出了新的评估机制,如PODS数据集,以支持个性化视觉任务的研究。
相关研究论文
- 1Personalized Representation from Personalized Generation麻省理工学院,OpenAI · 2024年
以上内容由遇见数据集搜集并总结生成


