GeoVistaBench
收藏GeoVistaBench数据集概述
数据集简介
GeoVistaBench是首个评估代理模型通用地理定位能力的基准数据集。该数据集包含带有丰富元数据的真实世界照片,用于评估地理定位模型。
数据结构
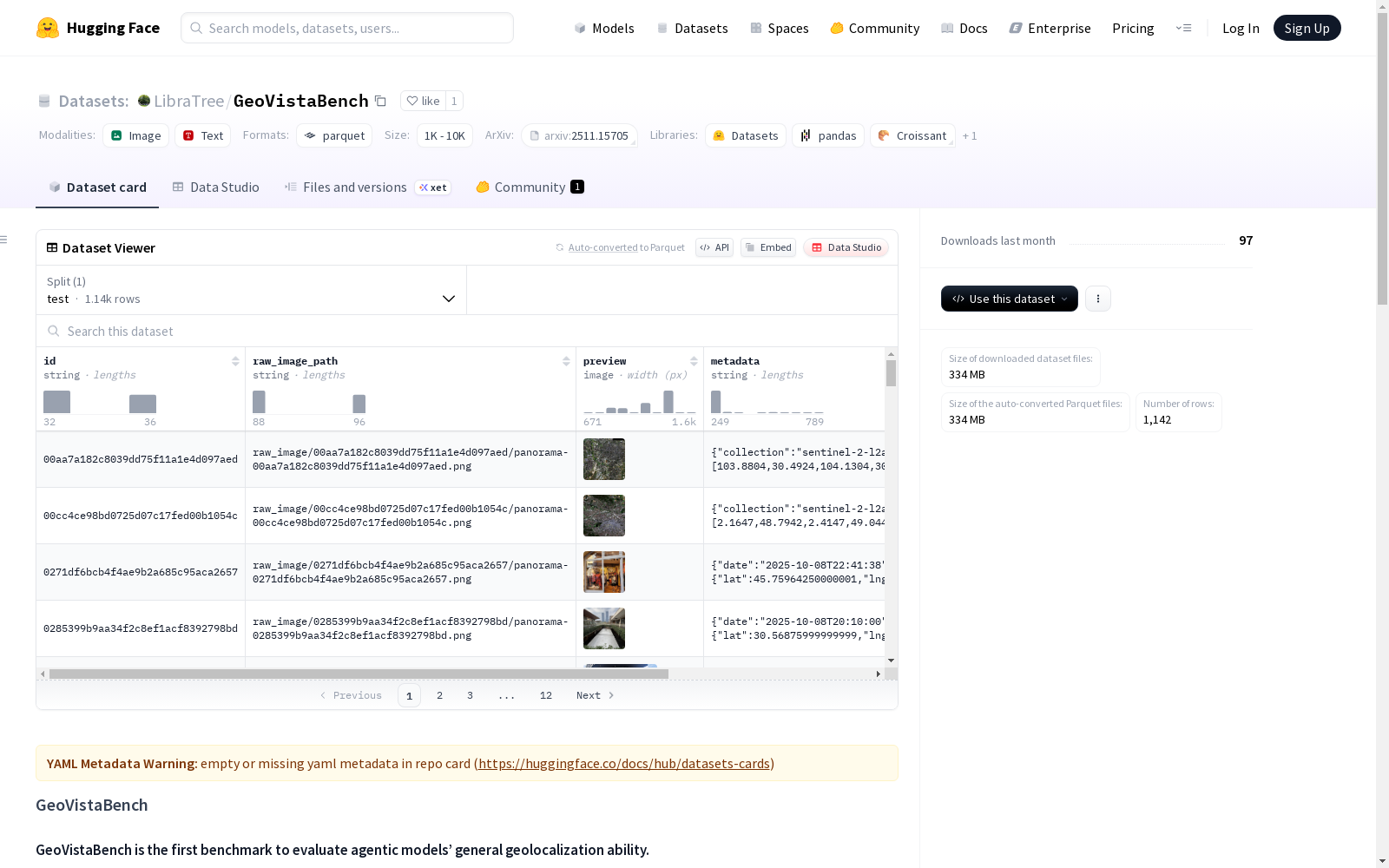
- id: 唯一标识符(与原始数据中的
uid相同) - raw_image_path: 源全景图像在仓库内的相对路径,位于
raw_image/<uid>/目录下 - preview: 压缩的JPEG预览图像(≤100万像素),位于
preview_image/<uid>/目录下,供HF数据集查看器使用 - metadata: JSON对象,存储拍摄时间戳、位置、pano_id、城市和其他属性,可解析获取经纬度、城市名称、多级位置标签等信息
- data_type: 描述图像类型的字符串,如果元数据中缺失则默认为
panorama
数据存储
所有样本存储在Hugging Face兼容的parquet文件中,路径为data/<split>/data-00000-of-00001.parquet,附加元数据存储在dataset_info.json中。
使用方法
-
克隆/下载此文件夹(或通过
huggingface_hub拉取) -
使用Python加载parquet文件: python from datasets import load_dataset ds = load_dataset(path/to/this/folder, split=test) sample = ds[0]
sample["raw_image_path"]指向用于推理的高质量文件sample["preview"]直接加载为压缩的PIL图像
-
使用元数据驱动评估逻辑,如计算城市级准确率、按
data_type过滤或检查特定区域
技术说明
- 原始全景图保留原始文件名以保持来源可追溯性
- 预览图像经过调整大小以降低存储成本,同时保持场景代表性
- 使用衍生作品时需遵守数据集的许可证(
dataset_info.json)
相关资源
- GeoVista模型:https://huggingface.co/papers/2511.15705
- GeoVista-Bench(可预览变体):https://huggingface.co/datasets/LibraTree/GeoVistaBench
- 论文页面:https://huggingface.co/papers/2511.15705
引用信息
bibtex @misc{wang2025geovistawebaugmentedagenticvisual, title = {GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization}, author = {Yikun Wang and Zuyan Liu and Ziyi Wang and Pengfei Liu and Han Hu and Yongming Rao}, year = {2025}, eprint = {2511.15705}, archivePrefix= {arXiv}, primaryClass = {cs.CV}, url = {https://arxiv.org/abs/2511.15705}, }