harshal3099/apex-food-rd-chatml-v2-expanded
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/harshal3099/apex-food-rd-chatml-v2-expanded
下载链接
链接失效反馈官方服务:
资源简介:
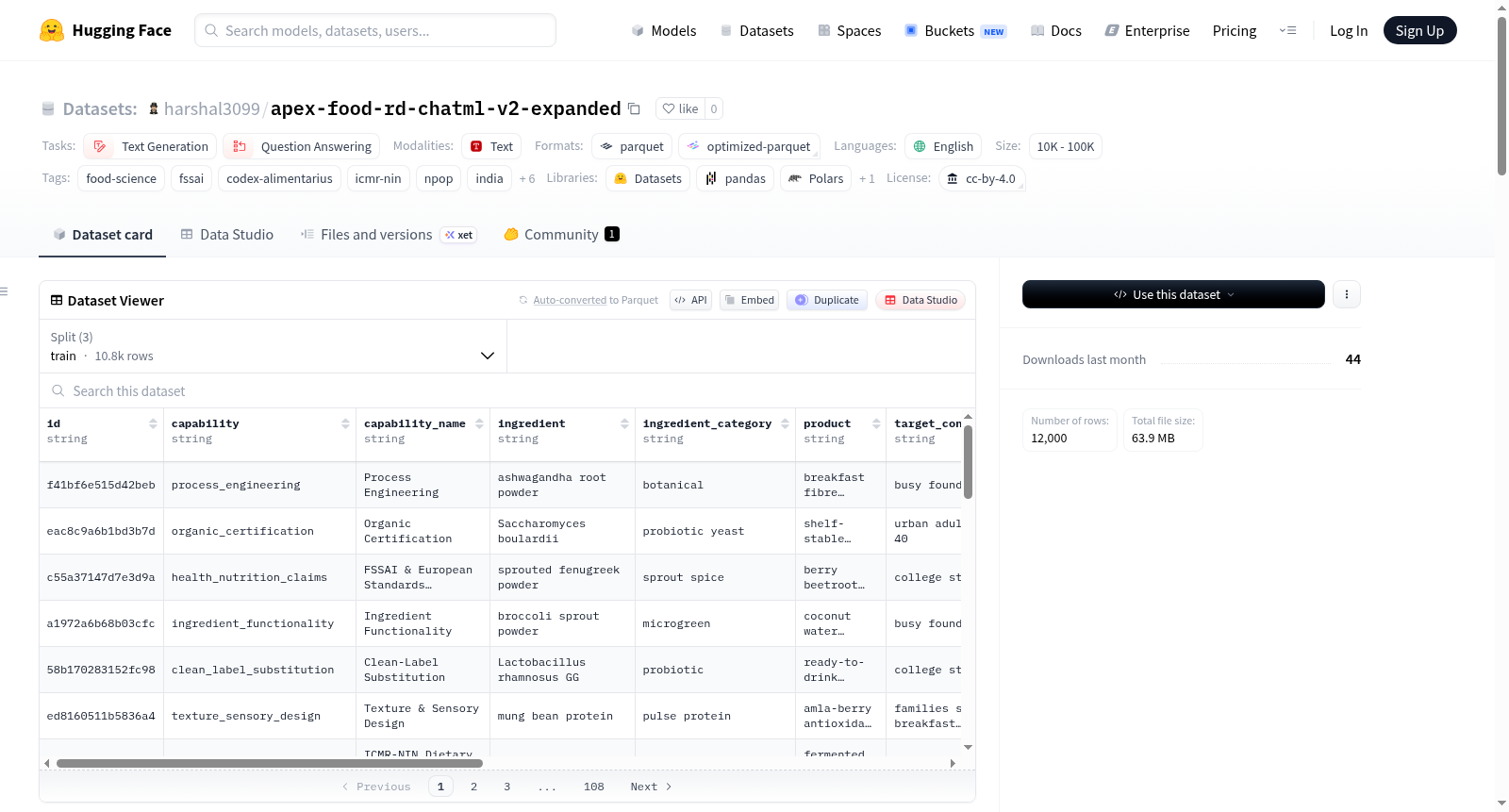
这是一个关于食品研发的聊天模型数据集,特别针对印度相关的功能性/天然/有机成分。数据集扩展了成分列表,包含了137种印度相关的成分,如小米、豆类、种子、香料、草药、印度水果等。数据集旨在用于食品配方研发助手,涵盖了多种能力,如成分功能、监管许可、保存系统设计等。数据集的大小为12,000个例子,分为训练、验证和测试集。此外,数据集还引用了多种监管和来源依据,如FSS Act, 2006、Codex GSFA CXS 192-1995等。最后,README还指出了数据集的重要限制,即它是一个合成数据集,不适合直接用于法律/监管验证。
This is an expanded v2 dataset for building a food formulation R&D assistant, specifically targeting India-relevant functional/natural/organic ingredients. The dataset expands the ingredient list to include 137 India-relevant ingredients such as millets, pulses, seeds, spices, herbs, Indian fruits, etc. It is designed for a food formulation R&D assistant and covers various capabilities like ingredient functionality, regulatory permissibility, preservation system design, etc. The dataset size is 12,000 examples, divided into training, validation, and test sets. Additionally, the dataset cites various regulatory and source references such as FSS Act, 2006, Codex GSFA CXS 192-1995, etc. Finally, the README also notes an important limitation: it is a synthetic dataset and not a substitute for direct legal/regulatory verification.
提供机构:
harshal3099
搜集汇总
数据集介绍
构建方式
本数据集基于Apex Nutrition在食品研发领域的实际需求,从初版仅包含20种原料的狭窄种子集出发,扩展至涵盖137种与印度功能性、天然及有机食品领域高度相关的原料体系。构建过程中,系统整合了包括印度传统谷物、豆类、种子、香料、草药、果蔬、发酵物、益生菌及功能性甜味剂在内的多元化成分库。每条数据均以ChatML格式组织为`messages`字段,融合了食品配方推理与法规引证能力,并引用FSSAI、Codex Alimentarius、ICMR-NIN等权威监管与营养指南作为知识支撑。数据集共计12,000条示例,按10,800/600/600的比例划分为训练集、验证集与测试集,适用于因果语言模型的监督微调。
使用方法
推荐以Qwen3-4B作为基座模型进行LoRA微调,随后可导出为GGUF格式部署。使用时,用户可通过构建符合ChatML格式的`messages`对话记录,输入特定的成分、产品与场景上下文,驱动模型输出包含成分功能解释、法规合规性判断或清洁标签替代方案的回应。数据集设计初衷是辅助食品配方研发助理的构建,因此典型应用包括:分析某种新原料在产品中的适用性、评估特定添加剂的FSSAI合规状态,或设计符合印度有机认证标准的配方。最终产出应结合官方最新通知进行二次验证以确保准确性。
背景与挑战
背景概述
在全球食品科学与营养强化领域,功能性配料与清洁标签产品的研发已成为应对消费者健康需求与法规合规性的核心议题。Apex Food R&D ChatML v2 Expanded印度功能性配料数据集于2025年创建,由Apex Nutrition研究团队主导开发,旨在解决食品配方研发助手构建中合成数据资源匮乏的问题。该数据集以137种印度本土功能性、天然及有机配料为核心,涵盖小米、豆类、香料、益生菌等多元类别,并深度融合FSSAI、Codex Alimentarius、ICMR-NIN等权威监管框架与膳食指南。其发布显著推动了食品配方推理与法规引证能力的提升,为中小型语言模型(如Qwen3-4B)在专业垂直领域的微调提供了坚实的数据基础,对印度乃至全球功能性食品的数字化研发具有里程碑式的影响。
当前挑战
该数据集所应对的领域挑战在于,传统食品配方研发依赖专家经验与纸质文档,缺乏可规模化训练AI辅助系统的结构化数据,导致创新效率低下且法规合规风险高。构建过程中,团队面临三重核心挑战:首先,需从零构建涵盖137种配料的完整功能与法规知识图谱,协调FSSAI、Codex、ICMR-NIN等多来源标准的版本差异;其次,合成数据需兼具科学的推理链条与真实的监管引证,避免产生误导性结论;最后,验证数据集对法规更新的实时反映能力,尽管基于静态知识库,但力求在稳定性与时效性间取得平衡,同时明确声明其非替代官方验证的固有局限性。
常用场景
经典使用场景
在食品科学与研发领域,该数据集最经典的使用场景是构建面向功能性食品配方与法规合规的智能问答与文本生成模型。具体而言,研究者可利用其12,000条以ChatML格式组织的样本,训练大语言模型在137种印度本土功能性原料(如小米、豆类、香料、草药、发酵物及益生菌)的背景下,精准回答有关原料功能、监管许可、清洁标签替代、保质期预测及感官设计等11项核心能力的问题。数据集中每条样本均包含详细的上下文信息,如原料类别、目标产品、消费者群体和包装形式,从而为模型提供丰富的领域知识支撑,使其能够生成具有科学依据和法规参考的配方建议。
解决学术问题
该数据集系统性地解决了食品科学中多个长期存在的学术研究难题。其一,它填补了印度本土功能性原料在标准化、法规互认和健康声称判定方面的数据空白,通过引用FSSAI、Codex Alimentarius、ICMR-NIN等权威标准,为跨体系法规对齐研究提供了基准。其二,它攻克了清洁标签替代和非热处理工艺优化的知识建模困境,使学者能够从数据驱动角度探索天然防腐体系与传统化学成分的等效性。其三,针对膳食营养缺口分析,数据集将ICMR-NIN膳食指南与具体原料的推荐摄入量动态关联,推动了精准营养与公共健康政策的交叉研究。这些贡献不仅提升了食品研发的自动化水平,还促进了本土传统原料的现代化科学评估。
实际应用
在实际产业应用中,该数据集驱动了食品研发辅助系统的落地。食品企业可利用基于此数据集微调的模型,快速生成符合FSSAI及欧盟标准的新产品配方草案,例如开发添加辣木、苋菜或奇亚籽的功能性零食,系统会自动评估成分的法规允许性并建议健康声称。初创公司与制造商还能借助其清洁标签替换模块,将人工添加剂替换为咖喱叶、姜黄或菊粉等天然原料,同时通过保质期预测功能优化生产流程。此外,有机认证场景中,模型可依据NPOP/APEDA标准指导原料溯源与标签设计,大幅缩短产品从实验室到市场的合规审查周期,尤其适用于印度本土及出口欧美的功能性食品开发。
数据集最近研究
最新研究方向
该数据集聚焦于印度功能性食品原料的全链条研发与监管适配,涵盖137种地方特色原料(如小米、豆类、香料、益生菌等)的法规合规性、清洁标签替代、工艺工程及感官设计等11项核心能力。前沿方向包括FSSAI与欧盟标准交叉验证下的健康声称标注、ICMR-NIN膳食缺口分析驱动的配方优化,以及合成数据驱动的食品配方推理模型(如Qwen3-4B微调)。其意义在于弥合传统食品科学与监管科技之间的鸿沟,为印度新兴功能性食品产业提供可溯源的、知识增强的SFT数据基座,且与全球清洁标签、有机认证及精准发酵趋势相呼应,推动利基原料的工业化与合规化进程。
以上内容由遇见数据集搜集并总结生成


