reasoning-mix
收藏官方服务:
资源简介:
该数据集是一个混合并打乱的数据集,包含高质量的网络文本、数学推理数据以及数学、编码、科学和谜题数据的推理轨迹。这些数据来源于多个不同的数据集,旨在用于高级推理模型(如SAEs和transcoders)的解缠。数据集包含文本和来源两个特征,并且只有一个训练分割。
提供机构:
EleutherAI创建时间:
2025-01-24
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: reasoning-mix
- 数据集地址: https://huggingface.co/datasets/EleutherAI/reasoning-mix
- 特征:
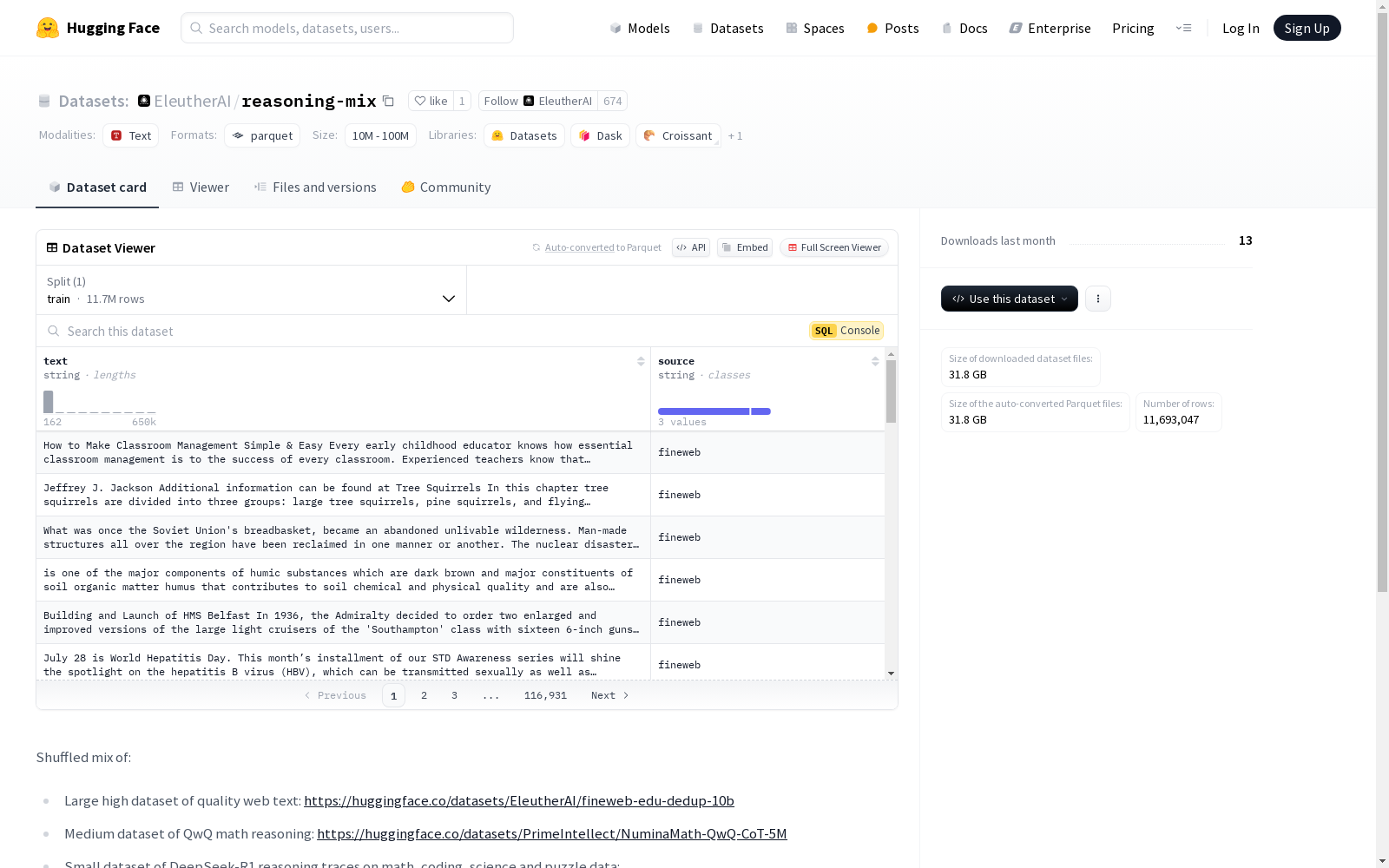
text: 字符串类型source: 字符串类型
- 数据集大小: 55,679,878,575 字节
- 下载大小: 31,815,823,888 字节
- 训练集:
- 样本数量: 11,693,047
- 大小: 55,679,878,575 字节
数据集组成
- Large high dataset of quality web text: 来自 EleutherAI/fineweb-edu-dedup-10b
- Medium dataset of QwQ math reasoning: 来自 PrimeIntellect/NuminaMath-QwQ-CoT-5M
- Small dataset of DeepSeek-R1 reasoning traces on math, coding, science and puzzle data: 来自 bespokelabs/Bespoke-Stratos-17k
数据集用途
- 目的: 用于高级推理模型(如SAEs、transcoders)的解耦研究。
其他信息
- 生成代码: luciaquirke/7dedea2a450ede2637c6785334efa3fa
- 替代数据集: lmsys/lmsys-chat-1m 用于qresearch的推理SAEs。
- 状态: 开发中(WIP)。
搜集汇总
数据集介绍
构建方式
reasoning-mix数据集的构建采用了多源数据融合的策略,整合了来自不同领域的高质量文本数据。具体而言,该数据集结合了EleutherAI提供的fineweb-edu-dedup-10b大规模网络文本数据、PrimeIntellect的NuminaMath-QwQ-CoT-5M数学推理数据,以及Bespoke-Stratos-17k的DeepSeek-R1推理轨迹数据。通过将这些数据集进行随机混合,形成了一个涵盖广泛推理任务的多模态数据集。
特点
reasoning-mix数据集的特点在于其多样性和高质量。它不仅包含了大量的网络文本数据,还融合了数学推理、编程、科学和谜题等多领域的推理任务。这种多源数据的结合使得该数据集能够支持复杂的推理模型训练,尤其是在解耦高级推理模型(如SAEs和transcoders)方面表现出色。此外,数据集的规模庞大,训练集包含超过1100万条样本,确保了模型的泛化能力。
使用方法
reasoning-mix数据集主要用于训练和评估高级推理模型,特别是那些需要处理多模态推理任务的模型。用户可以通过HuggingFace平台直接下载数据集,并利用提供的生成代码进行数据预处理和模型训练。该数据集特别适合用于研究解耦推理模型(如SAEs和transcoders)的性能,帮助开发者在数学、编程和科学等领域构建更强大的推理系统。
背景与挑战
背景概述
reasoning-mix数据集是一个专门为高级推理模型(如SAEs和transcoders)设计的混合数据集,旨在通过整合多种来源的数据来提升模型的推理能力。该数据集由多个高质量数据集组成,包括EleutherAI的fineweb-edu-dedup-10b、PrimeIntellect的NuminaMath-QwQ-CoT-5M以及Bespoke-Stratos-17k。这些数据集涵盖了广泛的领域,如数学推理、编程、科学和谜题等。reasoning-mix的创建标志着在复杂推理任务中,多源数据融合的重要性日益凸显,为研究者提供了丰富的实验材料。
当前挑战
reasoning-mix数据集在构建和应用过程中面临多重挑战。首先,数据来源的多样性和异质性要求研究者具备强大的数据处理能力,以确保数据的质量和一致性。其次,如何有效地将不同领域的数据进行融合,以提升模型的泛化能力,是一个亟待解决的问题。此外,由于数据集规模庞大,计算资源的消耗和模型训练的效率也成为不可忽视的挑战。最后,如何在保证数据隐私和安全的前提下,充分利用这些数据,也是研究者需要深入探讨的问题。
常用场景
经典使用场景
reasoning-mix数据集广泛应用于高级推理模型的训练与评估,特别是在解耦复杂推理任务中表现出色。该数据集通过整合高质量的网络文本、数学推理数据以及多领域推理轨迹,为研究者提供了一个丰富且多样化的训练环境,使得模型能够在数学、编程、科学和谜题等多个领域进行深度推理。
衍生相关工作
reasoning-mix数据集衍生了一系列经典研究工作,特别是在自编码器(SAEs)和转码器(transcoders)领域。许多研究团队利用该数据集进行模型训练和评估,推动了高级推理模型的发展。此外,该数据集还为其他相关数据集(如lmsys-chat-1m)的研究提供了重要参考。
数据集最近研究
最新研究方向
在人工智能领域,推理能力的提升一直是研究的核心议题之一。reasoning-mix数据集通过整合高质量的网络文本、数学推理数据以及多领域推理轨迹,为高级推理模型(如自注意力编码器和转码器)的解耦研究提供了丰富资源。该数据集的应用不仅推动了模型在数学、编程、科学等复杂任务中的表现,还为理解模型内部推理机制提供了新的视角。随着多模态推理和跨领域知识融合成为研究热点,reasoning-mix数据集在模型泛化能力和可解释性方面的潜力备受关注,为未来智能系统的设计提供了重要支持。
以上内容由遇见数据集搜集并总结生成


