hyperdemocracy/usc-unified
收藏Hugging Face2025-10-11 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/hyperdemocracy/usc-unified
下载链接
链接失效反馈官方服务:
资源简介:
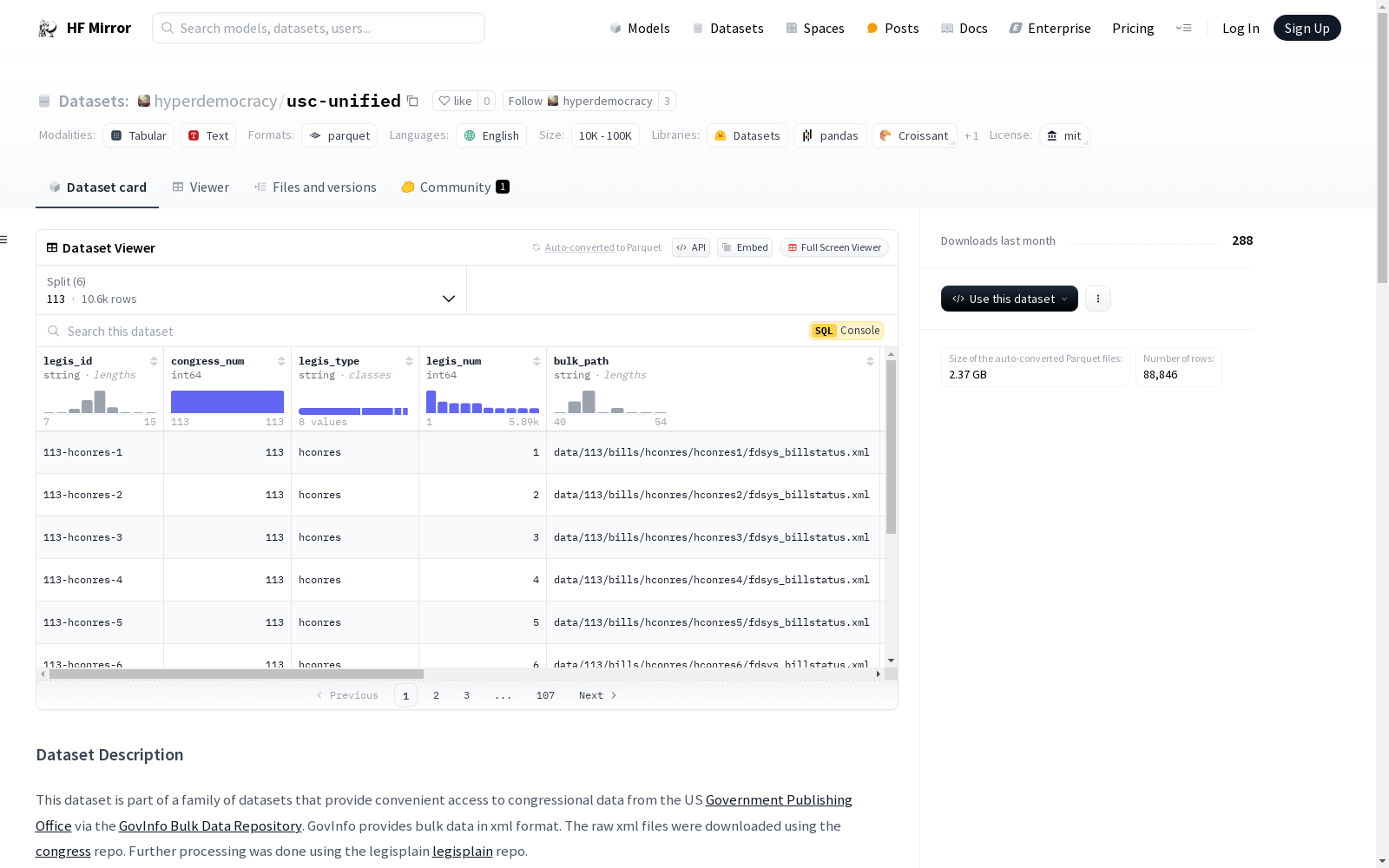
该数据集是一系列数据集的一部分,提供了对美国国会数据的便捷访问,数据来源于美国政府出版办公室的GovInfo批量数据仓库。原始数据为XML格式,通过congress和legisplain仓库进行下载和进一步处理。数据集包含美国国会第113至118届的法案元数据和文本版本,提供了每个法案的唯一ID、国会编号、法案类型、法案编号、XML文件路径、最后修改日期、XML文件内容、解析后的JSON以及每个法案的所有文本版本。数据集按国会编号分为不同的部分,并提供了加载数据集的Python代码示例。此外,还提供了国会编号与年份的映射关系。
该数据集是一系列数据集的一部分,提供了对美国国会数据的便捷访问,数据来源于美国政府出版办公室的GovInfo批量数据仓库。原始数据为XML格式,通过congress和legisplain仓库进行下载和进一步处理。数据集包含美国国会第113至118届的法案元数据和文本版本,提供了每个法案的唯一ID、国会编号、法案类型、法案编号、XML文件路径、最后修改日期、XML文件内容、解析后的JSON以及每个法案的所有文本版本。数据集按国会编号分为不同的部分,并提供了加载数据集的Python代码示例。此外,还提供了国会编号与年份的映射关系。
提供机构:
hyperdemocracy
原始信息汇总
数据集概述
数据集描述
该数据集是提供美国国会数据的系列数据集之一,涵盖了第113至118届国会的统一元数据和文本版本。数据来源于美国政府出版办公室(GPO)的GovInfo批量数据存储库,原始数据为XML格式。
数据集组成
数据集分为多个部分,每个部分对应一个国会届数,具体包括:
- 第113届国会
- 第114届国会
- 第115届国会
- 第116届国会
- 第117届国会
- 第118届国会
数据文件
每个国会届数的数据文件存储在对应的Parquet文件中,路径如下:
- 第113届国会:
data/usc-113-unified.parquet - 第114届国会:
data/usc-114-unified.parquet - 第115届国会:
data/usc-115-unified.parquet - 第116届国会:
data/usc-116-unified.parquet - 第117届国会:
data/usc-117-unified.parquet - 第118届国会:
data/usc-118-unified.parquet
列描述
数据集包含以下列:
legis_id:每个法案的唯一ID,格式为{congress_num}-{legis_type}-{legis_num}congress_num:法案所属的国会届数legis_type:法案类型,包括hr,hres,hconres,hjres,s,sres,sconres,sjreslegis_num:每个国会和类型的法案的递增编号bulk_path:批量下载时的XML文件路径lastmod:批量下载时的最后修改日期bs_xml:billstatus XML文件的内容bs_json:billstatus XML解析为JSON的内容tvs:该法案的所有文本版本
示例
数据集按国会届数分为多个部分,可以使用以下代码加载: python from datasets import load_dataset
加载每个国会届数的数据到DatasetDict中
dsd = load_dataset(path="hyperdemocracy/usc-unified")
加载单个国会届数的数据到Dataset中
ds = load_dataset(path="hyperdemocracy/usc-unified", split=117)
加载所有国会届数的数据到单个Dataset中
ds = load_dataset(path="hyperdemocracy/usc-unified", split="all")
国会届数与时间映射
| 国会届数 | 年份 | 元数据 | 文本 |
|---|---|---|---|
| 118 | 2023-2024 | True | True |
| 117 | 2021-2022 | True | True |
| 116 | 2019-2020 | True | True |
| 115 | 2017-2018 | True | True |
| 114 | 2015-2016 | True | True |
| 113 | 2013-2014 | True | True |
搜集汇总
数据集介绍
构建方式
该数据集 hyperdemocracy/usc-unified 依托于美国政府的公开数据资源,通过从 Government Publishing Office 的 GovInfo Bulk Data Repository 下载原始 xml 格式的国会数据,并利用 congress 和 legisplain 两个开源项目进行进一步的数据处理与整合,形成了包含 metadata 和 text version xml 的统一格式数据集。
特点
数据集整合了美国第 113 到第 118 届国会的立法信息,每一条记录都包含唯一的立法标识、国会编号、立法类型、立法序号等字段,以及对应的 billstatus XML 文件内容和解析后的 JSON 格式数据。其 metadata 和 text version 的结合,为研究美国立法过程提供了全面且结构化的数据资源。
使用方法
用户可以通过 HuggingFace 的 datasets 库加载数据集。数据集支持按国会编号进行分割加载,也可以一次性加载所有国会数据。例如,使用 load_dataset 函数,指定 split 参数为特定的国会编号或 'all' 以加载全部数据,进而方便地进行数据分析和模型训练。
背景与挑战
背景概述
hyperdemocracy/usc-unified数据集,作为美国国会数据的一种便捷获取方式,其创建旨在为研究人员提供从美国政府部门通过GovInfo Bulk Data Repository获取的国会数据。该数据集由一系列数据集组成,其中包括usc-billstatus、usc-textversion以及usc-unified,后者将元数据和文本版本XML相结合,覆盖了第113届至第118届国会的数据。该数据集的创建归功于多个机构和研究人员的共同努力,特别是利用了congress和legisplain这两个repo对原始的XML文件进行下载和进一步处理。其对于理解美国立法过程、法案状态跟踪以及文本版本分析等领域的研究具有重要的参考价值。
当前挑战
该数据集在构建过程中面临的主要挑战包括:1)如何高效地从美国政府出版办公室获取大量的XML格式数据;2)如何将这些原始数据进行清洗、整合,并转换成便于研究的格式;3)数据集在覆盖范围、时效性和准确性方面的挑战,尤其是在保持与政府数据更新同步上。此外,数据集在解决领域问题,如法案状态的跟踪和文本版本的分析时,还需克服如何确保数据的一致性和完整性的挑战。
常用场景
经典使用场景
在深入探索美国国会立法活动的领域,该数据集提供了一个统一的视角,将法案的元数据和文本版本相结合。其经典的使用场景在于,研究人员可以便捷地检索和分析特定法案的完整生命周期,包括法案的提出、修改、投票和最终结果,从而为立法过程的研究提供了全面的数据支撑。
实际应用
在实际应用中,该数据集可被用于构建立法跟踪系统,支持政府机构、非政府组织和研究机构实时监控和分析法案动态。此外,它还可用于教育和培训,帮助学生和专业人士更好地理解立法过程和法案的构成。
衍生相关工作
基于该数据集,已衍生出一系列相关工作,如法案文本分析、立法效率评估、以及政策影响研究等。这些工作不仅丰富了立法研究领域的方法论,也为政策制定者和分析师提供了实证研究的工具,以促进更有效的决策过程。
以上内容由遇见数据集搜集并总结生成


