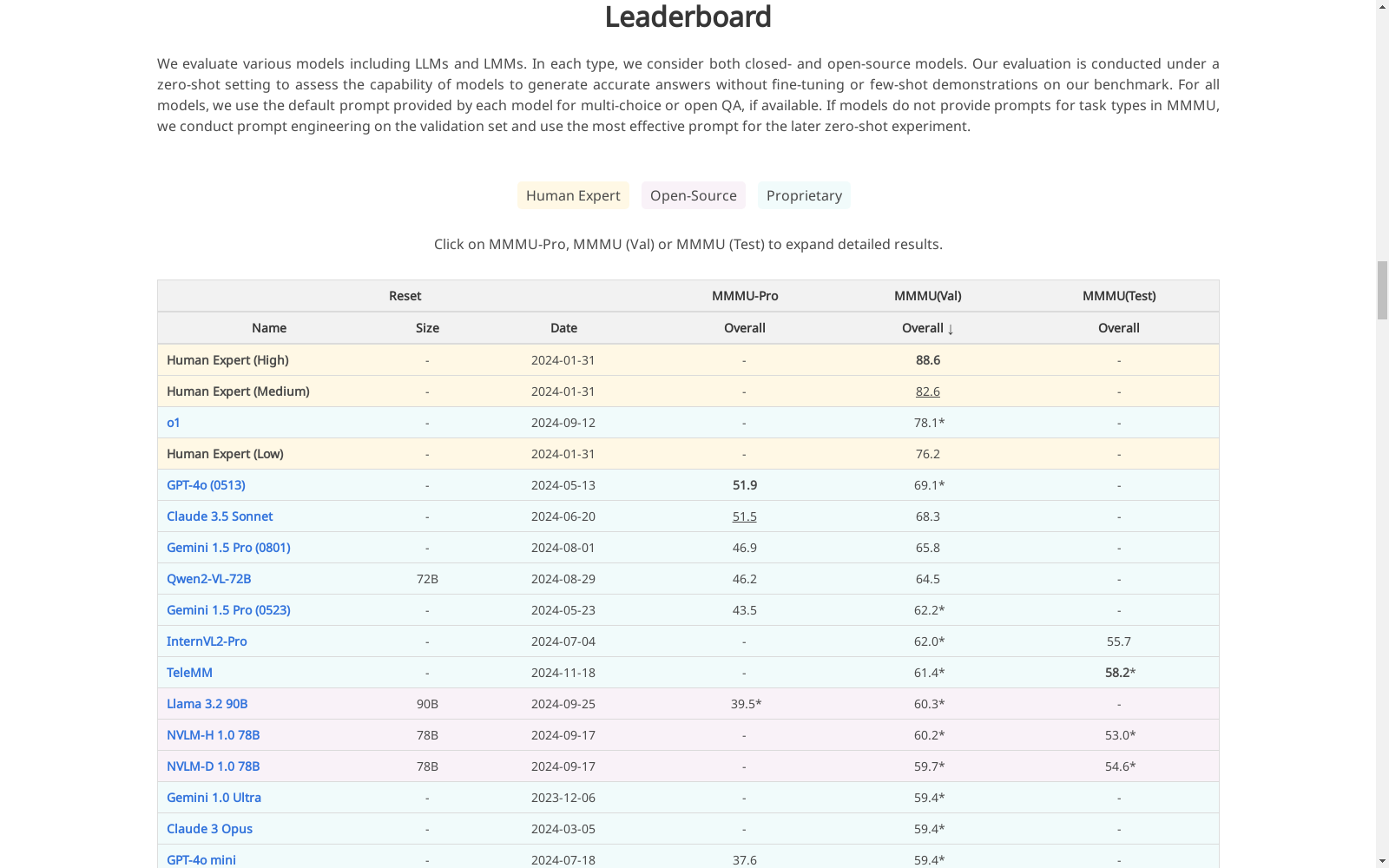
MMMU-Pro
收藏arXiv2024-09-04 更新2024-09-07 收录
下载链接:
https://mmmu-benchmark.github.io/#leaderboard
下载链接
链接失效反馈官方服务:
资源简介:
MMMU-Pro是由MMMU团队创建的多学科多模态理解与推理基准数据集,包含3460个精心策划的多模态问题,涵盖六个核心学科。数据集通过过滤可由纯文本模型回答的问题、增加候选选项和引入仅视觉输入设置,严格评估模型的多模态理解和推理能力。创建过程中,数据集通过人工验证和多样化的视觉输入设置,确保问题的高质量和挑战性。MMMU-Pro主要应用于评估和提升多模态AI模型的理解和推理能力,旨在解决当前模型在多模态任务中的局限性。
MMMU-Pro is a multidisciplinary multimodal understanding and reasoning benchmark dataset developed by the MMMU team, which comprises 3,460 carefully curated multimodal questions spanning six core disciplines. To strictly evaluate the multimodal understanding and reasoning capabilities of AI models, this dataset filters out questions that can be answered solely by plain text models, supplements additional candidate options, and introduces visual-only input settings. During the construction process, manual verification and diverse visual input configurations are employed to guarantee the high quality and challenging nature of all questions. MMMU-Pro is primarily utilized to evaluate and enhance the understanding and reasoning abilities of multimodal AI models, with the objective of addressing the current limitations faced by such models in multimodal tasks.
提供机构:
MMMU团队
创建时间:
2024-09-04
搜集汇总
数据集介绍
构建方式
MMMU-Pro数据集的构建过程经过精心设计,以确保其能够严格评估多模态模型的真正理解和推理能力。首先,通过过滤掉那些仅依赖文本信息即可回答的问题,确保了问题的多模态依赖性。其次,候选选项的数量从四个增加到十个,以减少模型通过猜测正确答案的可能性。最后,引入了一种仅依赖视觉输入的设置,其中问题嵌入在图像中,这要求模型同时‘看’和‘读’,从而测试其无缝整合视觉和文本信息的能力。
特点
MMMU-Pro数据集的主要特点在于其对多模态理解能力的严格评估。通过增加候选选项的数量和引入视觉输入设置,该数据集显著提高了对模型多模态推理能力的挑战。实验结果表明,与MMMU基准相比,模型在MMMU-Pro上的表现显著下降,这表明当前最先进的模型在真正的多模态理解和推理方面仍存在局限性。
使用方法
使用MMMU-Pro数据集时,研究人员和开发者可以通过提供嵌入在图像中的问题来测试其模型的多模态理解能力。数据集包括标准设置和视觉输入设置,分别测试模型在不同条件下的表现。通过对比模型在不同设置下的性能,可以更全面地评估其在实际应用中的多模态处理能力,并为未来的研究提供有价值的方向。
背景与挑战
背景概述
MMMU-Pro数据集是Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU)基准的增强版本,由Xiang Yue等研究人员于2024年提出。该数据集旨在通过严格的评估流程,更准确地评估多模态模型在理解和推理方面的真实能力。MMMU-Pro的核心研究问题是如何确保模型在处理视觉和文本信息时能够进行深入且多方面的理解,而非依赖于表面的统计模式。这一研究对多模态AI的发展具有重要影响,因为它推动了模型在实际应用中处理复杂任务的能力。
当前挑战
MMMU-Pro数据集在构建过程中面临多个挑战。首先,如何过滤掉仅依赖文本即可回答的问题,确保评估的公平性和准确性。其次,增加候选选项的数量,以减少模型通过猜测正确答案的可能性。最后,引入仅依赖视觉输入的设置,测试模型在真实世界中处理视觉和文本信息的能力。这些挑战不仅要求模型具备强大的视觉和文本整合能力,还需要在复杂的多模态任务中展现出高级的推理技巧。
常用场景
经典使用场景
MMMU-Pro数据集的经典使用场景在于评估多模态模型的真正理解和推理能力。通过过滤掉仅依赖文本即可回答的问题,增加候选选项,并引入仅视觉输入的设置,MMMU-Pro挑战模型在图像中嵌入文本的情况下进行无缝的视觉和文本信息整合,从而更真实地模拟人类认知技能。
衍生相关工作
MMMU-Pro的推出激发了大量相关研究,包括改进多模态模型的视觉文本整合能力、开发更复杂的推理技术以应对数据集的挑战,以及探索如何在不同设置下保持模型性能的一致性。此外,MMMU-Pro还促进了新一代多模态基准的开发,如LAMM、LVLM-eHub等,这些基准进一步推动了多模态AI领域的发展。
数据集最近研究
最新研究方向
在多模态理解和推理领域,MMMU-Pro数据集的最新研究方向主要集中在提升模型的多模态综合能力上。通过引入视觉输入设置,研究者们旨在挑战模型在真实世界场景中无缝整合视觉和文本信息的能力。这一方向不仅推动了模型在处理复杂视觉任务中的表现,还为未来多模态AI的发展提供了宝贵的研究方向。
相关研究论文
- 1MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding BenchmarkMMMU团队 · 2024年
以上内容由遇见数据集搜集并总结生成


