【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
VishnuPJ/Malayalam_CultureX_IndicCorp_SMC
收藏Hugging Face2024-08-12 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/VishnuPJ/Malayalam_CultureX_IndicCorp_SMC
下载链接
链接失效反馈官方服务:
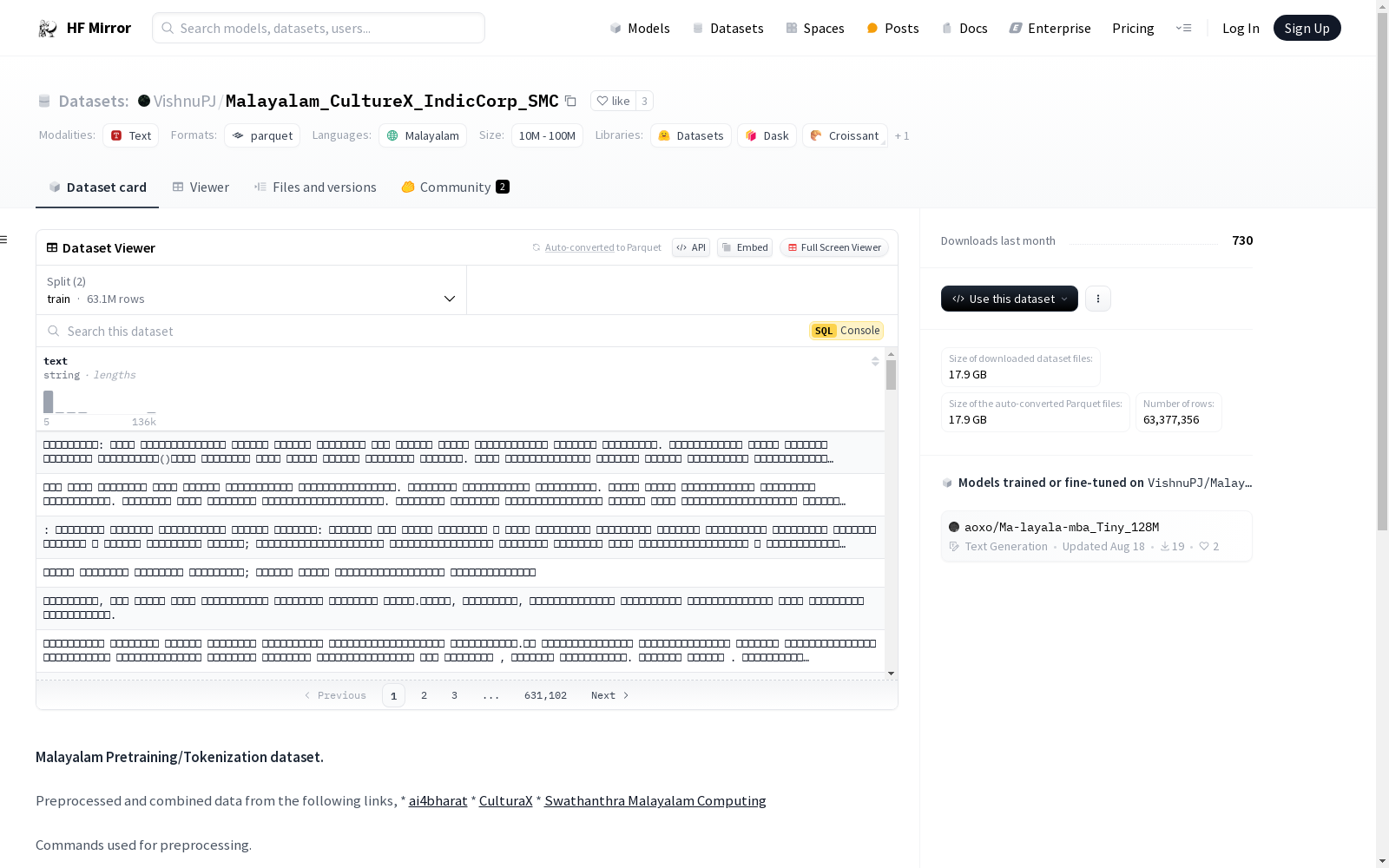
资源简介:
这是一个用于预训练和分词的马拉雅拉姆语数据集,数据来源于ai4bharat、CulturaX和Swathanthra Malayalam Computing等多个来源。数据集经过预处理,移除了非马拉雅拉姆语字符,合并了文本文件,并移除了字符数少于5的行。数据集包含train和test两个分割,分别有63110105和267251个样本,总大小为46864218447字节。
This is a Malayalam dataset intended for pre-training and tokenization. It is sourced from multiple providers including ai4bharat, CulturaX, and Swathanthra Malayalam Computing. The dataset has been preprocessed: non-Malayalam characters have been removed, text files have been merged, and lines with fewer than 5 characters have been filtered out. The dataset contains two splits, train and test, with 63110105 and 267251 samples respectively, and has a total size of 46864218447 bytes.
提供机构:
VishnuPJ
原始信息汇总
数据集概述
数据来源
- ai4bharat: ai4bharat
- CulturaX: CulturaX
- Swathanthra Malayalam Computing: Swathanthra Malayalam Computing
预处理步骤
-
移除非马拉雅拉姆语字符 bash sed -i s/[^ം-ൿ.,;:@$%+&?!() ]//g test.txt
-
合并特定目录下的所有文本文件 bash find SMC -type f -name *.txt -exec cat {} ; >> combined_SMC.txt
-
移除少于5个字符的行 bash grep -P [x{0D00}-x{0D7F}] data/ml.txt | awk length($0) >= 5 > preprocessed/ml.txt
数据集信息
-
特征
- 名称: text
- 数据类型: string
-
分割
- 训练集
- 字节数: 46611476142
- 样本数: 63110105
- 测试集
- 字节数: 252742305
- 样本数: 267251
- 训练集
-
下载大小: 17881832073
-
数据集大小: 46864218447
配置
- 默认配置
- 训练集路径: data/train-*
- 测试集路径: data/test-*
搜集汇总
数据集介绍
构建方式
该数据集通过整合来自多个来源的预处理文本构建而成,包括ai4bharat、CulturaX以及Swathanthra Malayalam Computing。首先,通过正则表达式移除所有非马拉雅拉姆语字符,确保数据纯净。随后,合并特定目录下的所有文本文件,形成统一的数据集。最后,过滤掉字符数少于五行的文本,以提高数据质量。
特点
此数据集显著特点在于其广泛的语言覆盖和高质量的预处理。它不仅包含了丰富的马拉雅拉姆语文本,还通过严格的预处理步骤确保了数据的纯净性和可用性。此外,数据集的规模庞大,包含超过六千万条训练样本和二十多万条测试样本,为语言模型训练提供了充足的数据支持。
使用方法
该数据集适用于马拉雅拉姆语的预训练和分词任务。用户可以通过HuggingFace的datasets库轻松加载和使用该数据集,具体方法包括指定数据集名称和配置文件。数据集提供了训练和测试两个分割,用户可以根据需要选择合适的分割进行模型训练和评估。
背景与挑战
背景概述
马来语(Malayalam)作为印度南部喀拉拉邦的主要语言,拥有丰富的文化与历史背景。VishnuPJ/Malayalam_CultureX_IndicCorp_SMC数据集的创建旨在为马来语的自然语言处理(NLP)研究提供高质量的预训练和分词数据。该数据集汇集了来自多个来源的文本数据,包括ai4bharat、CulturaX和Swathanthra Malayalam Computing(SMC),这些数据经过精心预处理,去除了非马来语字符,并合并了多个文本文件。数据集的构建时间未明确提及,但其主要研究人员或机构可能包括印度的人工智能研究机构和语言技术实验室。该数据集的核心研究问题是如何有效利用大规模文本数据进行马来语的预训练和分词,从而提升NLP模型在该语言上的表现。这一研究对推动马来语在人工智能领域的应用具有重要意义。
当前挑战
VishnuPJ/Malayalam_CultureX_IndicCorp_SMC数据集在构建过程中面临多项挑战。首先,数据来源的多样性要求对不同格式的文本进行统一预处理,这包括去除非马来语字符和合并多个文本文件。其次,数据集的规模庞大,包含超过6300万条训练样本和26万条测试样本,这增加了数据处理的复杂性和计算资源的消耗。此外,确保数据的质量和一致性也是一个重要挑战,特别是在处理来自不同文化背景和语言习惯的文本时。最后,如何有效地利用这些数据进行预训练和分词,以提升NLP模型在马来语上的性能,是该数据集面临的核心研究问题。
常用场景
经典使用场景
在自然语言处理领域,VishnuPJ/Malayalam_CultureX_IndicCorp_SMC数据集被广泛用于马拉雅拉姆语的预训练和分词任务。该数据集通过整合来自ai4bharat、CulturaX和Swathanthra Malayalam Computing的文本资源,提供了丰富的马拉雅拉姆语文本数据,为模型训练提供了坚实的基础。其经典使用场景包括但不限于语言模型预训练、文本分类、命名实体识别等任务,为提升马拉雅拉姆语处理模型的性能提供了宝贵的资源。
实际应用
在实际应用中,VishnuPJ/Malayalam_CultureX_IndicCorp_SMC数据集被用于开发和优化马拉雅拉姆语的智能助手、机器翻译系统、语音识别和生成技术等。这些应用不仅提升了马拉雅拉姆语用户的信息获取和交流效率,也为马拉雅拉姆语社区的文化传播和技术普及提供了支持。通过这些实际应用,数据集在促进马拉雅拉姆语的数字化和智能化进程中发挥了重要作用。
衍生相关工作
基于VishnuPJ/Malayalam_CultureX_IndicCorp_SMC数据集,研究者们开展了多项相关工作,包括但不限于开发新的预训练语言模型、改进分词算法、以及探索低资源语言的迁移学习策略。这些工作不仅提升了马拉雅拉姆语处理技术的水平,也为其他低资源语言的处理提供了借鉴和参考。此外,该数据集还激发了跨语言研究的热潮,促进了不同语言处理技术之间的交流与合作。
以上内容由遇见数据集搜集并总结生成


