FinMTM
收藏github2026-02-05 更新2026-01-10 收录
下载链接:
https://github.com/HiThink-Research/FinMTM
下载链接
链接失效反馈官方服务:
资源简介:
FinMTM是一个多轮多模态基准,用于金融推理和代理评估,包含客观问题、开放式对话和基于代理的任务,强调多轮对话稳定性、会话级记忆以及代理规划和执行能力。
FinMTM is a multi-turn multimodal benchmark for financial reasoning and agent evaluation. It encompasses objective questions, open-ended dialogues, and agent-based tasks, with a focus on multi-turn dialogue stability, session-level memory, as well as agent planning and execution capabilities.
创建时间:
2026-01-06
原始信息汇总
FinMTM 数据集概述
数据集基本信息
- 数据集名称: FinMTM: A Multi-Turn Multimodal Benchmark for Financial Reasoning and Agent Evaluation
- 主要用途: 用于评估金融视觉语言模型在三种设定下的能力:客观问题、开放式对话以及基于工具使用和多源证据的智能体任务。
- 核心目标: 解决现有基准测试多为单轮对话、未能充分衡量多轮对话稳定性、会话级记忆或智能体规划与执行能力的问题。
数据集构成与特点
- 任务类型:
- 客观问题: 基于金融视觉材料的单选/多选任务。
- 开放式问题: 强调组合推理、多步计算、自我纠正和记忆的多轮对话。
- 金融智能体任务: 包含长程规划与证据支撑答案的工具增强型多源工作流。
- 能力维度:
- 图表/图形理解、数值推理、实体绑定、跨轮次一致性、记忆召回。
- 工具规划、工具调用正确性、基于证据的总结。
- 数据构建方法: 采用多阶段构建流程,从视觉基础的原语,到组合的多步对话,再到工具增强的智能体工作流,确保每个会话与目标认知需求对齐并可追溯至可验证的证据。
评估方法
- 客观问题: 对预测选项进行精确匹配评分;多选题使用集合重叠规则(精确率/召回率/F分数风格)来惩罚缺失或多余的选择。
- 开放式对话(多轮): 采用加权组合评分,包括:
- 轮次级质量(每轮正确性、基础性、推理质量)
- 会话级质量(跨轮次一致性、长上下文稳定性、记忆正确性)
- 金融智能体任务: 评估:
- 规划质量(步骤顺序、工具选择、分解)
- 工具执行(工具名称与核心参数正确性;证据充分性)
- 最终结果(答案正确性 + 基于证据的总结)
数据获取与使用
- 访问地址: HuggingFace (
HF_DATASET_URL) - 许可证: Apache-2.0
- 使用说明: 请查阅数据集卡片和论文附录。若部分数据源有再分发限制,数据集将提供处理后的元数据和评估划分,以及在适用情况下提供基于脚本的重新创建说明。
基准测试结果
- 对一系列领先的视觉语言模型进行了基准测试。
- 最终得分是客观问题、开放式问题和金融智能体任务得分的平均值。
- 关键观察:
- 智能体设定比纯推理设定暴露出更大的性能差距。
- 实体去标识化/模糊化增加了不确定性,并强调了基于证据的推理。
- 模型规模扩大有帮助,但稳健的工具规划与执行对于开源模型仍是主要瓶颈。
更新与发布计划
- 2026-01: 基准测试论文和评估协议初始发布。
- 待定: 数据集和评估脚本发布。
- 待定: 在线排行榜开放提交。
引用与许可
- 许可证: Apache-2.0
- 引用: 请参考相关论文(
PAPER_URL或ARXIV_URL)。
搜集汇总
数据集介绍
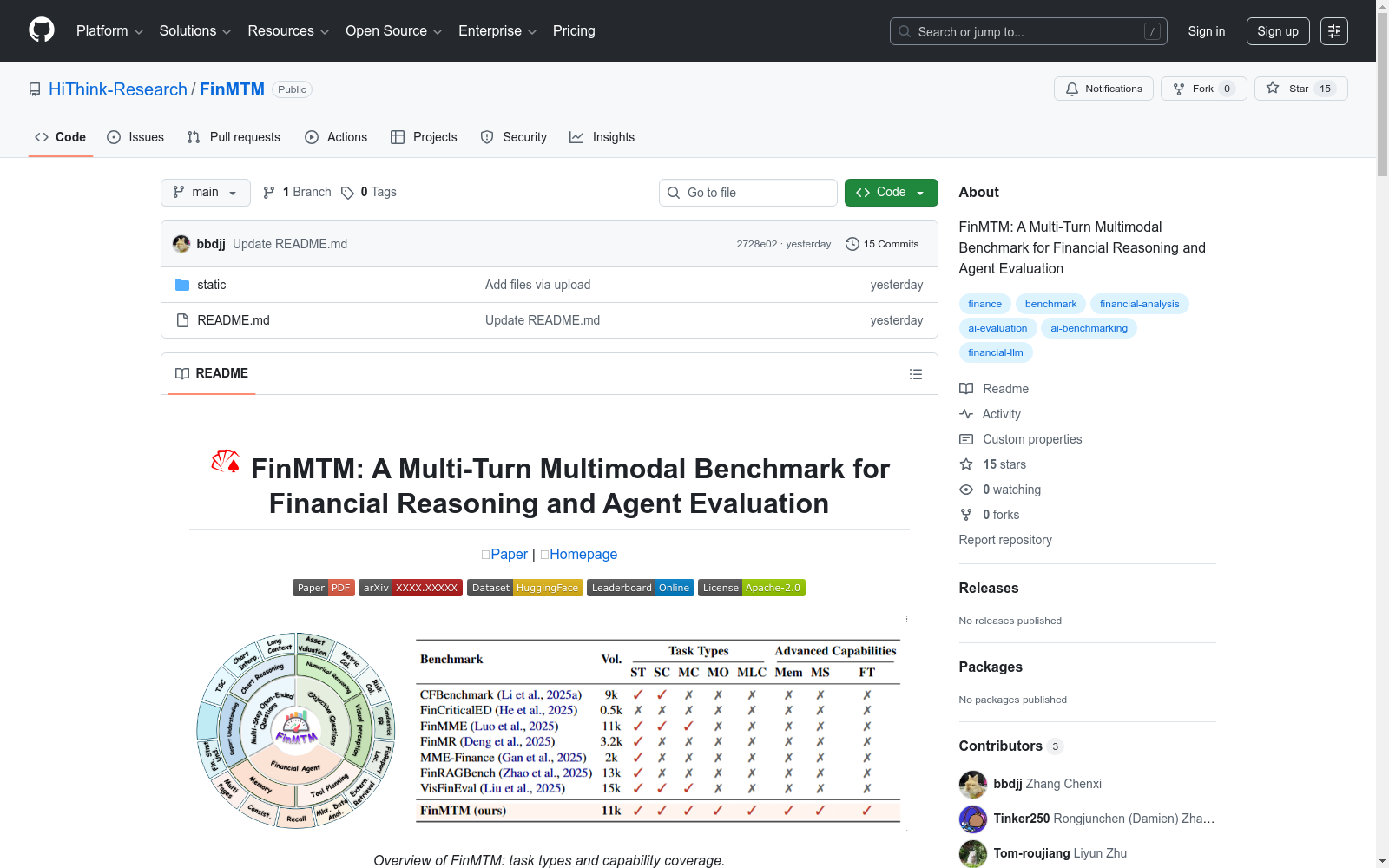
构建方式
在金融视觉语言模型评估领域,构建能够全面衡量多轮对话稳定性和智能体规划能力的数据集至关重要。FinMTM采用了一种创新的多阶段数据构建流程,从视觉基础的原型问题出发,逐步组合成强调复合推理与多步计算的多轮开放式对话,最终扩展至包含工具调用与多源证据的智能体工作流。这一流程确保了每个会话都精准对齐特定的认知需求,并保持与可验证证据的可追溯性,从而系统性地扩展了金融多轮会话的规模与复杂性。
特点
该数据集的核心特点在于其多任务、多模态的综合性评估框架。它不仅涵盖了基于金融图表的客观选择题,还设计了强调组合推理、自我纠正和记忆保持的多轮开放式对话,以及需要长程规划和证据支撑的金融智能体任务。这些任务共同覆盖了图表理解、数值推理、实体绑定、跨轮次一致性、记忆召回以及工具规划与执行等多个能力维度,为深入评估模型在专业金融场景下的稳健性与智能体性能提供了多维度的衡量标准。
使用方法
研究人员可通过HuggingFace平台获取数据集,并遵循其评估协议对模型进行综合测试。评估体系针对三类任务分别设计:客观问题采用精确匹配或集合重叠规则评分;开放式对话通过结合轮次质量与会话质量的加权组合进行衡量;金融智能体任务则从规划质量、工具执行准确性和最终答案的证据支撑度等多个层面进行评判。用户可按照提供的快速入门指南配置环境,运行评估脚本,并将模型输出提交至在线排行榜,以参与模型性能的横向比较。
背景与挑战
背景概述
在金融科技与人工智能交叉领域,视觉语言模型(VLMs)的推理能力评估面临严峻考验,源于金融数据特有的图表格式、密集的专业知识、长程依赖关系以及基于证据的工具使用需求。现有基准测试大多局限于单轮交互,难以全面衡量模型在多轮对话稳定性、会话级记忆以及智能体规划与执行等方面的综合表现。为此,FinMTM基准应运而生,由相关研究团队于2026年1月首次发布,旨在填补这一空白。该数据集通过设计客观问题、开放式多轮对话及金融智能体任务三大场景,系统评估模型在金融视觉理解、数值推理、实体绑定、跨轮次一致性及工具规划等多维能力,为推进金融领域多模态智能体的发展提供了关键的评价框架。
当前挑战
FinMTM所针对的核心领域问题在于提升视觉语言模型在复杂金融环境中的多轮多模态推理与智能体操作能力,其挑战主要体现在两方面。首先,在领域问题层面,金融数据具有高度专业化与动态性,模型需准确解析各类图表、处理长程依赖关系、进行证据驱动的工具调用与规划,并维持跨轮次对话的逻辑一致性与记忆准确性,这对模型的领域知识融合与复杂任务分解能力提出了极高要求。其次,在数据集构建过程中,研究团队面临多阶段数据构造的复杂性,需从视觉基础单元逐步组合成多轮对话,进而扩展至工具增强的智能体工作流,确保每个会话均符合预设的认知需求并与可验证证据保持可追溯性,同时还需处理实体脱敏等操作带来的不确定性,以保障数据质量与评估的严谨性。
常用场景
经典使用场景
在金融视觉语言模型评估领域,FinMTM数据集被广泛用于多轮多模态推理任务的基准测试。该数据集通过整合客观问题、开放式对话和金融代理任务,模拟了真实金融分析中的复杂交互场景。研究人员利用其多轮会话结构,系统评估模型在图表理解、数值计算和跨轮次一致性等方面的表现,为模型在动态金融环境中的稳定性提供了标准化度量。
衍生相关工作
围绕FinMTM数据集,学术界衍生出多项聚焦于金融代理能力优化的经典研究。这些工作深入探索了工具增强型工作流中的规划质量评估方法、多源证据融合机制,以及实体模糊化处理对模型推理鲁棒性的影响。部分研究进一步扩展了数据集的评估维度,开发了针对长程记忆一致性与会话层级认知要求的细粒度分析框架。
数据集最近研究
最新研究方向
在金融视觉语言模型领域,FinMTM作为多轮多模态基准测试,正推动研究向复杂交互与智能体能力评估深化。该数据集通过整合客观问答、开放式对话及工具增强的金融代理任务,精准聚焦于模型在长程依赖、会话级记忆以及证据驱动的规划执行等前沿挑战。当前研究热点紧密围绕多阶段数据构建流程,旨在系统化生成具备可追溯证据的金融会话,以评测模型在实体消歧、跨轮次一致性和工具调用正确性等方面的表现。其影响在于为金融AI代理的稳健性设定了新标准,促进了领域内从静态分析向动态、多源决策支持的范式转变。
以上内容由遇见数据集搜集并总结生成


