ShadenA/MathNet
收藏Hugging Face2026-04-27 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/ShadenA/MathNet
下载链接
链接失效反馈官方服务:
资源简介:
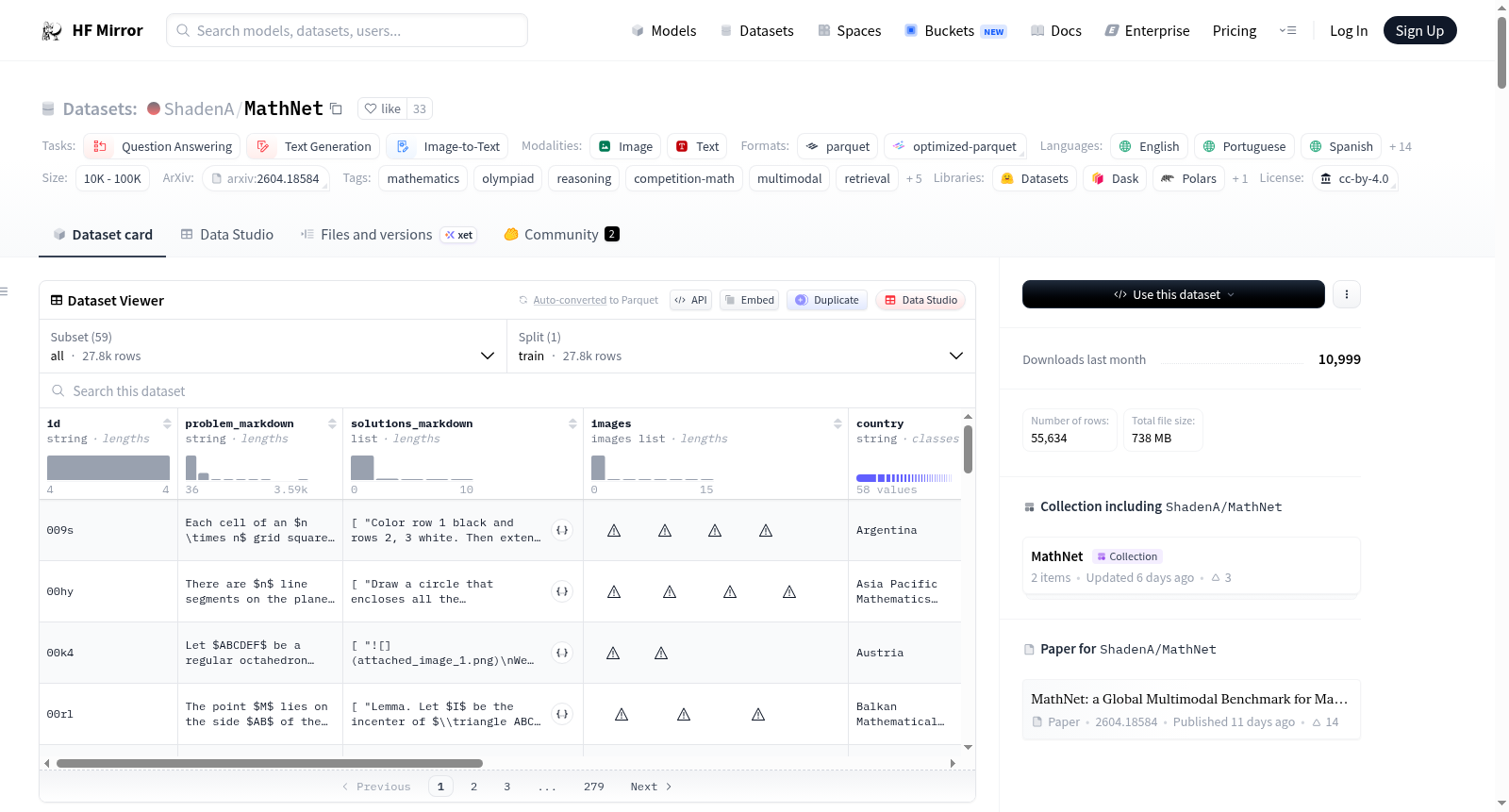
MathNet v0 是一个高质量、大规模、多模态、多语言的奥林匹克数学问题数据集,包含来自47个国家和17种语言的30,676个专家编写的问题及其解答。数据集覆盖了20年的竞赛题目,支持问题解答、数学感知检索和检索增强问题解答等多种任务。每个问题都附有详细的元数据、主题分类和来源信息。数据集旨在评估生成模型和基于嵌入的系统在数学推理方面的能力。
MathNet v0 is a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems, comprising 30,676 expert-authored problems with solutions from 47 countries and 17 languages. The dataset spans two decades of competitions and supports various tasks including problem solving, math-aware retrieval, and retrieval-augmented problem solving. Each problem comes with detailed metadata, a topic taxonomy, and provenance information. The dataset is designed for evaluating mathematical reasoning in generative models and embedding-based systems.
提供机构:
ShadenA
搜集汇总
数据集介绍
构建方式
数学推理研究长期受限于基准数据集的规模、语言覆盖与任务多样性不足。MathNet应运而生,它从47个国家的官方竞赛手册中系统性地收集了1985至2025年间累计1,595卷PDF文档,经多模态OCR解析后,借助多阶段LLM流水线完成结构与内容的提取:首先由Gemini模型定位问题与解答的边界,再由GPT-4.1提取完整的LaTeX格式文本,最后通过规则相似性校验、GPT-4.1视觉评判及人工专家审核三重机制确保数据质量,形成了一套覆盖17种语言的奥林匹克级别数学问题-答案对集合。
使用方法
研究者可通过HuggingFace Datasets库加载MathNet:使用默认的'all'配置获取全部训练数据,或按国家名称(如'Argentina')加载特定子集。每条数据包含问题陈述、多解答版本、主题路径、语言标签及嵌入图形。基于此可开展多项评估:使用MathNet-Solve任务评测模型的原生推理性能,利用MathNet-Retrieve检验嵌入模型对数学等价问题的检索能力,或借助MathNet-RAG探究检索质量对推理提升的影响。该数据集亦适用于强化学习训练,专家编写的解答可作为密集奖励信号用于可验证答案问题。
背景与挑战
背景概述
MathNet由MIT研究团队主导构建,于2025年发布,旨在弥补现有数学推理基准在规模、语言多样性与任务广度上的显著不足。该数据集汇聚了来自47个国家、横跨1985至2025年的国际数学奥林匹克及国家级竞赛真题,包含30,676对专家撰写的问题与解答,覆盖几何、代数、数论、组合数学等核心领域,并支持17种语言与多模态输入。作为首个大规模、多语言、专家级奥林匹克数学推理与检索基准,MathNet为评估生成模型的数学推理能力与嵌入系统的数学检索能力提供了全新视角,在ICLR 2026上发表后迅速成为该领域的重要参考资源。
当前挑战
MathNet针对的核心领域挑战在于,现有的数学推理基准如GSM8K与MATH规模有限且语言单一,难以衡量模型在真实竞赛情境下的复杂推理与跨语言泛化能力。构建过程中,团队面临数万页异构PDF文档的自动对齐问题:不同国家、年份的官方手册在问题与解答的排版、编号及命名规范上差异巨大,传统正则方法难以处理。为此,团队设计了多阶段LLM流水线,结合OCR解析与大语言模型的智能分割与校验,并通过规则相似度、GPT-4.1评判及人工专家审核的三重验证机制,确保数据质量。此外,多维度元数据(如层次化主题标签、图文对应关系)的准确提取与存储亦是显著挑战。
常用场景
经典使用场景
MathNet作为一项大规模、多模态、多语言的高质量奥林匹克数学数据集,其最经典的使用场景聚焦于评估和提升大型语言模型与多模态模型的数学推理能力。研究者通常利用其涵盖47个国家、17种语言、超过3万道专家级问题的庞大规模,对生成式模型进行零样本或少样本的奥林匹克级别数学问题求解测试。该数据集通过三道基准任务——问题求解、数学感知检索与检索增强型问题求解——全面衡量模型的逻辑推导、多步证明和跨语言数学理解能力。其丰富的图像图表与长篇幅解答尤其适合检验模型在复杂几何、代数与数论场景中的视觉-语言联合推理表现,已成为评估前沿推理模型的核心基准之一。
解决学术问题
该数据集的核心贡献在于解决了数学推理领域长期存在的基准局限性,包括规模不足、语言覆盖单一和任务维度匮乏等关键问题。通过构建跨越二十年、涵盖几何、代数、数论与组合数学等完备知识体系的推理测试集,MathNet为学术界提供了首个支持多语言、多模态、检索与生成联合评估的奥林匹克数学标准平台。其引入的数学等价问题检索任务,更是开辟了评估嵌入模型对深层数学结构理解能力的新方向。该数据集的发布推动了推理模型与检索模型在数学领域的协同发展,为验证模型是否具备真正的结构化数学思维而非表面模式匹配提供了可靠评测工具。
实际应用
在实际应用中,MathNet为智能教育系统和自动化竞赛训练平台提供了坚实的数据基础。教育科技公司可基于该数据集开发能自动批改奥林匹克级别数学解答的智能辅导工具,帮助学习者获得即时、细致的解题反馈。其多语言特性使得构建跨地区、跨语种的数学竞赛题库成为可能,服务于全球数学爱好者的自适应学习与能力评估。此外,检索增强生成任务中的发现可直接应用于学术搜索引擎与知识库系统,提升数学领域的信息检索精度,为研究人员快速定位结构相似的经典问题与对应解法提供技术支撑。
数据集最近研究
最新研究方向
面向数学奥林匹克推理与检索的多模态基准研究,聚焦于利用大规模、多语言专家级数据评估生成式模型的问题求解能力与嵌入模型的数学结构检索能力,并探索检索增强生成(RAG)对推理性能的提升。当前前沿方向包括:构建包含47个国家、17种语言、超过3万道题目及专家级解答的MathNet数据集;设立问题求解、数学感知检索与检索增强求解三项基准任务;揭示当前最优模型(如Gemini-3.1-Pro、GPT-5)在奥林匹克难度题目上仍存在显著挑战,而嵌入模型在数学等价检索任务中召回率极低(Recall@1低于5%);同时,高质量检索可大幅提升模型推理表现(如DeepSeek-V3.2-Speciale在专家检索支持下达到97.3%)。该工作为评估高级数学推理与检索系统提供了更严格、多元的测试平台,对推动AI在教育、竞赛及科学发现中的可信应用具有深远意义。
以上内容由遇见数据集搜集并总结生成


