UltraEditBench
收藏Hugging Face2025-05-25 更新2025-05-26 收录
下载链接:
https://huggingface.co/datasets/XiaojieGu/UltraEditBench
下载链接
链接失效反馈官方服务:
资源简介:
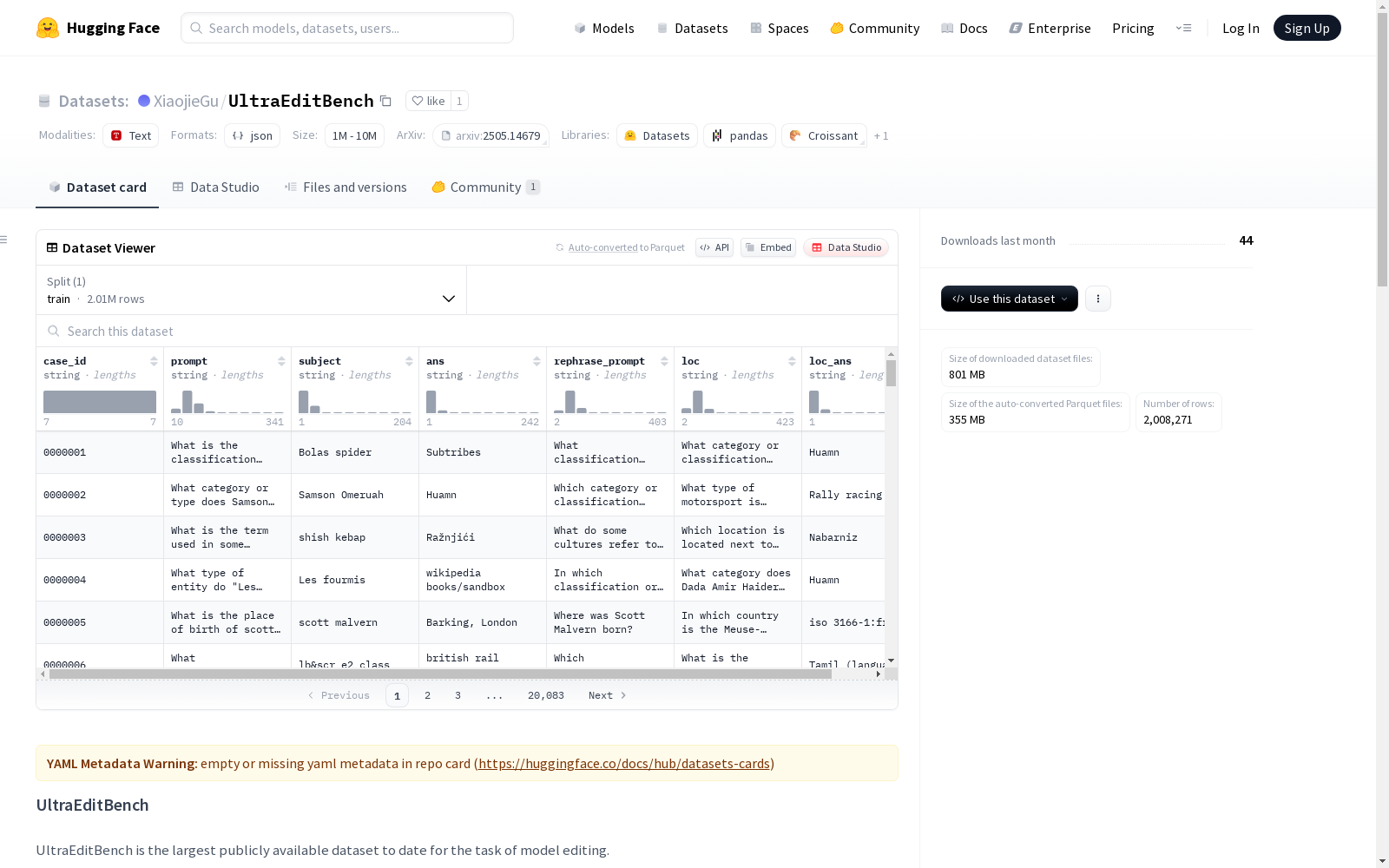
UltraEditBench是迄今为止公开可用的最大的模型编辑任务数据集。该数据集包含三种核心实例:编辑实例、等价实例和无关实例,用于评估模型在效力、泛化能力和特异性三个指标上的表现。每个样本包括三个问题-答案对和相关的元数据。
创建时间:
2025-05-12
原始信息汇总
UltraEditBench 数据集概述
📌 数据集简介
- UltraEditBench 是目前公开可用的最大模型编辑任务数据集。
- 相关论文:ULTRAEDIT: Training-, Subject-, and Memory-Free Lifelong Editing in Large Language Models
📊 数据集构成
评估指标
| 指标名称 | 描述 |
|---|---|
| Efficacy | 模型是否正确反映了更新后的事实。 |
| Generalization | 编辑是否适用于语义相似的问题。 |
| Specificity | 无关知识是否保持不受影响。 |
核心实例
| 组件名称 | 描述 | 数量 |
|---|---|---|
| Editing Instance | 涉及目标实体的事实性问答对,用于测试Efficacy。 | 2,008,326 |
| Equivalent Instance | 编辑实例的改写版本,用于测试Generalization。 | 2,008,326 |
| Unrelated Instance | 无关的问答对,用于测试Specificity。 | 2,008,326 |
🔍 关键字段说明
| 字段名 | 描述 |
|---|---|
case_id |
样本唯一标识符(如"00001")。 |
prompt |
Editing Instance的问题部分——针对特定知识更新的实际问题。 |
ans |
Editing Instance的答案部分——编辑后模型的期望输出。 |
subject |
编辑问题中提到的实体(用于兼容基于主题的方法)。 |
rephrase_prompt |
Equivalent Instance的问题部分——prompt的改写版本。 |
loc |
Unrelated Instance的问题部分——与编辑事实无关的问题。 |
loc_ans |
Unrelated Instance的答案部分——编辑后应保持不变。 |
📜 引用信息
bibtex @article{gu2025ultraedit, title={UltraEdit: Training-, Subject-, and Memory-Free Lifelong Editing in Large Language Models}, author={Gu, Xiaojie and Chen, Guangxu and Li, Jungang and Gu, Jia-Chen and Hu, Xuming and Zhang, Kai}, journal={arXiv preprint arXiv:2505.14679}, year={2025} }
📩 联系方式
- 邮箱: peettherapynoys@gmail.com
- GitHub Issues: github.com/XiaojieGu/UltraEdit/issues
搜集汇总
数据集介绍
构建方式
UltraEditBench作为当前最大规模的公开模型编辑任务数据集,其构建过程体现了严谨的学术设计。研究团队通过系统化采集200余万组三元实例,每个样本包含编辑实例、等效实例和不相关实例,形成完整的评估体系。编辑实例采用事实性问答对形式,针对特定实体知识更新需求;等效实例通过语义改写生成,用于检验编辑泛化能力;不相关实例则严格筛选与目标无关的问答对,确保评估特异性。这种三位一体的构建方法为模型编辑研究提供了多维度的评估基准。
特点
该数据集最显著的特点是构建了完整的评估指标体系,涵盖编辑效果、泛化能力和特异性三大维度。200余万样本规模远超同类数据集,每个样本包含三种严格配对的问答实例,确保评估的全面性。数据采用统一结构化格式存储,包含案例ID、问题提示、答案文本等标准化字段,并保留原始实体信息以兼容不同编辑方法。特别设计的元数据结构支持灵活调用,既能满足基础编辑任务验证,也可支撑复杂的终身学习场景研究。
使用方法
使用该数据集时,研究者可通过标准接口加载三元实例组进行模型编辑实验。编辑实例用于直接测试知识更新效果,等效实例需在编辑后验证语义泛化性能,不相关实例则作为负样本检测模型稳定性。评估阶段建议同步计算三大核心指标:通过编辑实例准确率衡量效能,等效实例匹配度评估泛化性,不相关实例保持率检验特异性。数据集提供的标准化案例ID和结构化字段,支持快速构建自动化评估流程,便于不同编辑方法的横向对比研究。
背景与挑战
背景概述
UltraEditBench作为当前公开可用的最大规模模型编辑任务数据集,由Xiaojie Gu等学者在2025年提出的ULTRAEDIT研究框架中首次引入。该数据集诞生于大型语言模型终身编辑技术快速发展的背景下,旨在解决传统模型更新过程中面临的再训练成本高、主体依赖性强等核心问题。其创新性地构建了包含200余万条样本的三元评估体系,通过编辑实例、等效实例和非相关实例的协同设计,为模型编辑技术的效能、泛化性和特异性提供了标准化度量基准,显著推动了可解释人工智能领域的发展。
当前挑战
该数据集主要应对模型编辑领域的两大核心挑战:在领域问题层面,传统方法难以平衡知识更新的精确性与原始知识的保持性,编辑过程易引发灾难性遗忘或过度泛化现象;在构建过程中,需克服超大规模样本的语义对齐难题,确保等效实例能准确反映原始问题的语义变体,同时非相关实例必须严格规避潜在的知识关联。数据标注环节涉及复杂的知识图谱验证与语言学改写,对标注一致性和逻辑完备性提出极高要求。
常用场景
经典使用场景
在大型语言模型持续学习的研究中,UltraEditBench作为当前最大规模的公开模型编辑数据集,为评估模型知识更新能力提供了标准化测试平台。其独特的三元组结构(编辑实例、等效实例、无关实例)能够系统性地验证模型在接收新知识后的精确性、泛化能力和知识隔离性,成为衡量模型编辑算法性能的黄金基准。
衍生相关工作
基于UltraEditBench的评估框架,已衍生出MEMIT、ROME等经典模型编辑方法的研究。这些工作通过该数据集验证了参数局部修改策略的有效性,开创了知识神经元定位的新研究方向。后续研究如MQUAKE等进一步扩展了该数据集在多模态编辑场景的应用深度。
数据集最近研究
最新研究方向
在大型语言模型持续编辑领域,UltraEditBench数据集的推出为研究社区提供了前所未有的规模与多维评估标准。该数据集通过编辑实例、等效实例和非相关实例的三元结构设计,支持模型编辑效果、泛化能力和特异性的系统化验证。当前研究热点集中在训练无关、主体无关且无需记忆的终身编辑方法开发,旨在解决传统编辑技术中的灾难性遗忘和知识冲突问题。其海量样本覆盖的复杂语义场景,正推动基于参数隔离和知识蒸馏的新型编辑框架探索,为构建可持续更新的可信AI系统提供关键基准。
以上内容由遇见数据集搜集并总结生成


