en-translations
收藏Hugging Face2024-12-14 更新2024-12-15 收录
下载链接:
https://huggingface.co/datasets/agentlans/en-translations
下载链接
链接失效反馈官方服务:
资源简介:
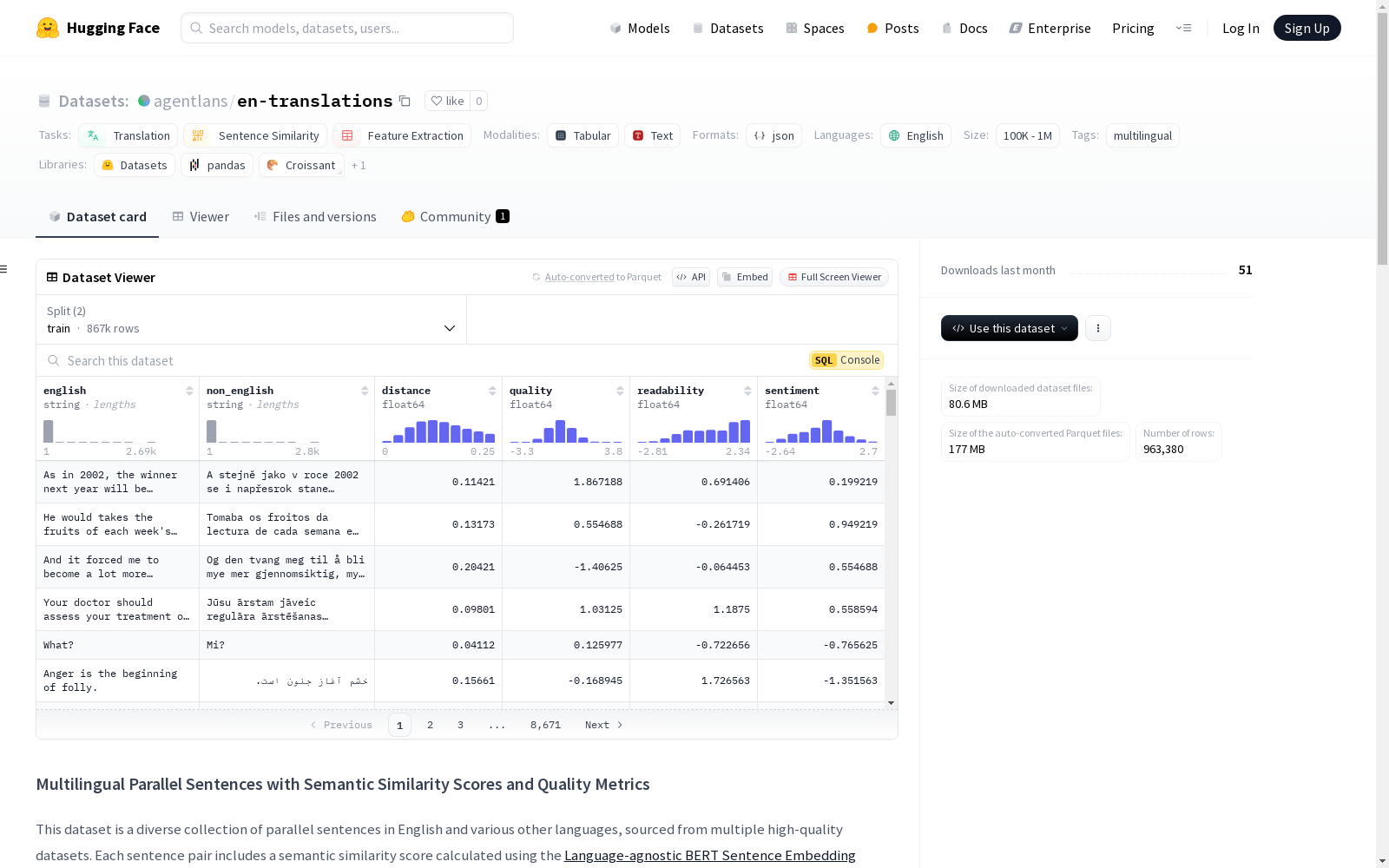
这是一个多语言平行句子的数据集,包含英语和多种其他语言的句子对。每个句子对都附有语义相似度分数和质量指标。数据集支持机器翻译、跨语言语义相似度、多语言自然语言理解和翻译质量评估等任务。数据集中的句子对来自多个高质量数据集,如JW300、Europarl、TED Talks等。每个数据实例包含英语句子、对应的其他语言句子、语义相似度分数、内容质量分数、可读性分数和情感分数。数据集被分为训练集和验证集,分别占90%和10%。
创建时间:
2024-12-06
原始信息汇总
Multilingual Parallel Sentences with Semantic Similarity Scores and Quality Metrics
数据集概述
该数据集是一个多语言平行句子的集合,包含英语与其他多种语言的句子对。每个句子对都包含语义相似度分数和额外的质量指标。
支持的任务
- 机器翻译
- 跨语言语义相似度
- 多语言自然语言理解
- 翻译质量评估
语言
数据集包含英语与多种语言的句子对,来源包括JW300、Europarl、TED Talks、OPUS-100、Tatoeba、Global Voices和News Commentary。
数据集结构
数据实例
每个实例包含以下字段:
english: 英语句子(字符串)non_english: 对应的其他语言句子(字符串)distance: 句子间的语义相似度分数(余弦距离)(浮点数)quality: 内容质量分数(浮点数)readability: 可读性分数(浮点数)sentiment: 情感分数(浮点数)
示例: json { "english": "If we start to think exponentially, we can see how this is starting to affect all the technologies around us.", "non_english": "Če začnemo misliti eksponentno, vidimo, kako to začenja vplivati na vse tehnologije okoli nas.", "distance": 0.05299, "quality": 0.3359375, "readability": 0.103515625, "sentiment": 0.45703125 }
数据划分
数据集划分为:
- 训练集:867,042行(90%)
- 验证集:96,338行(10%)
- 总计:963,380行(100%)
数据集创建
句子从不同数据集的不同划分和配置中下载,确保了语言表达的多样性。为了保证高质量,数据集进行了去重处理,并且只包含语义相似度分数(distance)低于0.25的句子对。每个数据集的每个划分下载了5,000个句子,最终形成了90%的训练集和10%的验证集。
标注
语义相似度分数使用LaBSE模型生成,通过计算嵌入之间的余弦距离。其他指标使用以下模型进行标注:
- 质量:quality
- 可读性:readability
- 情感:sentiment
使用数据的注意事项
社会影响
该数据集可以通过提供高质量的平行句子以及语义相似度和质量指标,增强跨语言NLP模型和应用。
已知限制
- 语义相似度(
distance)和质量分数可能无法捕捉跨语言相似性或翻译质量的所有细微差别。 - 覆盖范围仅限于源数据集中存在的语言。
- 基于
distance < 0.25的过滤可能会排除一些有效但相似度较低的翻译。
搜集汇总
数据集介绍
构建方式
该数据集通过整合多个高质量数据源,如JW300、Europarl、TED Talks等,构建了一个包含英语与多种其他语言平行句子的多样化集合。为确保数据质量,数据集进行了去重处理,并仅保留了语义相似度得分(`distance`)低于0.25的句子对。此外,每个句子对还附带了由LaBSE模型计算的语义相似度得分,以及通过特定模型生成的质量、可读性和情感得分。最终,数据集被划分为90%的训练集和10%的验证集,以支持不同任务的训练与评估。
使用方法
该数据集可广泛应用于机器翻译、跨语言语义相似度评估以及多语言自然语言理解等任务。用户可以通过访问数据集的训练集和验证集,利用其中的平行句子对进行模型训练和性能评估。具体使用时,可以提取句子对的语义相似度得分、质量评分等指标,辅助模型优化和任务实现。此外,数据集的结构清晰,便于直接导入各类自然语言处理框架进行进一步分析和应用。
背景与挑战
背景概述
en-translations数据集是一个多语言平行句子的集合,旨在支持机器翻译、跨语言语义相似性分析以及多语言自然语言理解等任务。该数据集由多个高质量数据源整合而成,包括JW300、Europarl、TED Talks等,涵盖了英语与多种其他语言的句子对。每个句子对不仅包含语义相似性评分,还附带了质量、可读性和情感等多维度指标,这些指标通过LaBSE模型及其他专用模型计算得出。该数据集的构建旨在为跨语言NLP模型提供高质量的训练数据,从而推动多语言应用的发展。
当前挑战
en-translations数据集在构建过程中面临多项挑战。首先,确保语义相似性评分的准确性是一个关键问题,尽管LaBSE模型提供了强大的嵌入能力,但仍可能遗漏某些跨语言的细微差异。其次,数据集的覆盖范围受限于源数据集的语言种类,这可能限制了其在某些语言上的应用。此外,过滤机制(如`distance < 0.25`)虽然提高了数据质量,但也可能导致一些有效但相似度较低的翻译被排除。最后,多维度指标的标注过程复杂,需依赖多种模型,这增加了数据集构建的难度和成本。
常用场景
经典使用场景
在多语言自然语言处理领域,en-translations数据集以其丰富的平行句对和语义相似度评分,成为机器翻译和跨语言语义相似度计算的经典工具。该数据集通过整合来自多个高质量数据源的平行句对,提供了英语与其他多种语言之间的精确翻译样本,并附带语义相似度、质量、可读性和情感等多维度评分,为研究者和开发者提供了深入分析和优化翻译模型的基础数据。
解决学术问题
en-translations数据集通过提供多语言平行句对及其语义相似度评分,有效解决了机器翻译中的质量评估难题。传统的翻译质量评估依赖于人工标注,耗时且成本高昂,而该数据集通过自动化生成的语义相似度评分,为翻译质量的自动评估提供了新的研究方向。此外,该数据集还为跨语言语义相似度和多语言自然语言理解的研究提供了丰富的实验数据,推动了相关领域的技术进步。
实际应用
在实际应用中,en-translations数据集广泛应用于多语言翻译系统、跨语言检索和多语言内容生成等领域。例如,在跨国企业的多语言客户服务系统中,该数据集可用于训练和优化自动翻译模型,提升客户服务的响应速度和准确性。此外,在新闻媒体和出版行业,该数据集也可用于生成高质量的多语言内容,满足全球读者的阅读需求,促进文化交流和信息传播。
数据集最近研究
最新研究方向
在多语言自然语言处理领域,en-translations数据集的最新研究方向主要集中在跨语言语义相似性和机器翻译质量评估的精细化上。该数据集通过引入LaBSE模型计算的语义相似度分数,以及质量、可读性和情感等多维度指标,为跨语言应用提供了更为丰富的特征。研究者们正致力于利用这些多维度的质量评估指标,提升机器翻译系统的准确性和鲁棒性,尤其是在处理低资源语言和复杂语境下的翻译任务时。此外,该数据集的广泛语言覆盖和高质量的平行句对,也为多语言自然语言理解模型的训练提供了宝贵的资源,推动了跨语言信息检索和语义分析等前沿应用的发展。
以上内容由遇见数据集搜集并总结生成


