Hussam-q/MedHAM
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Hussam-q/MedHAM
下载链接
链接失效反馈官方服务:
资源简介:
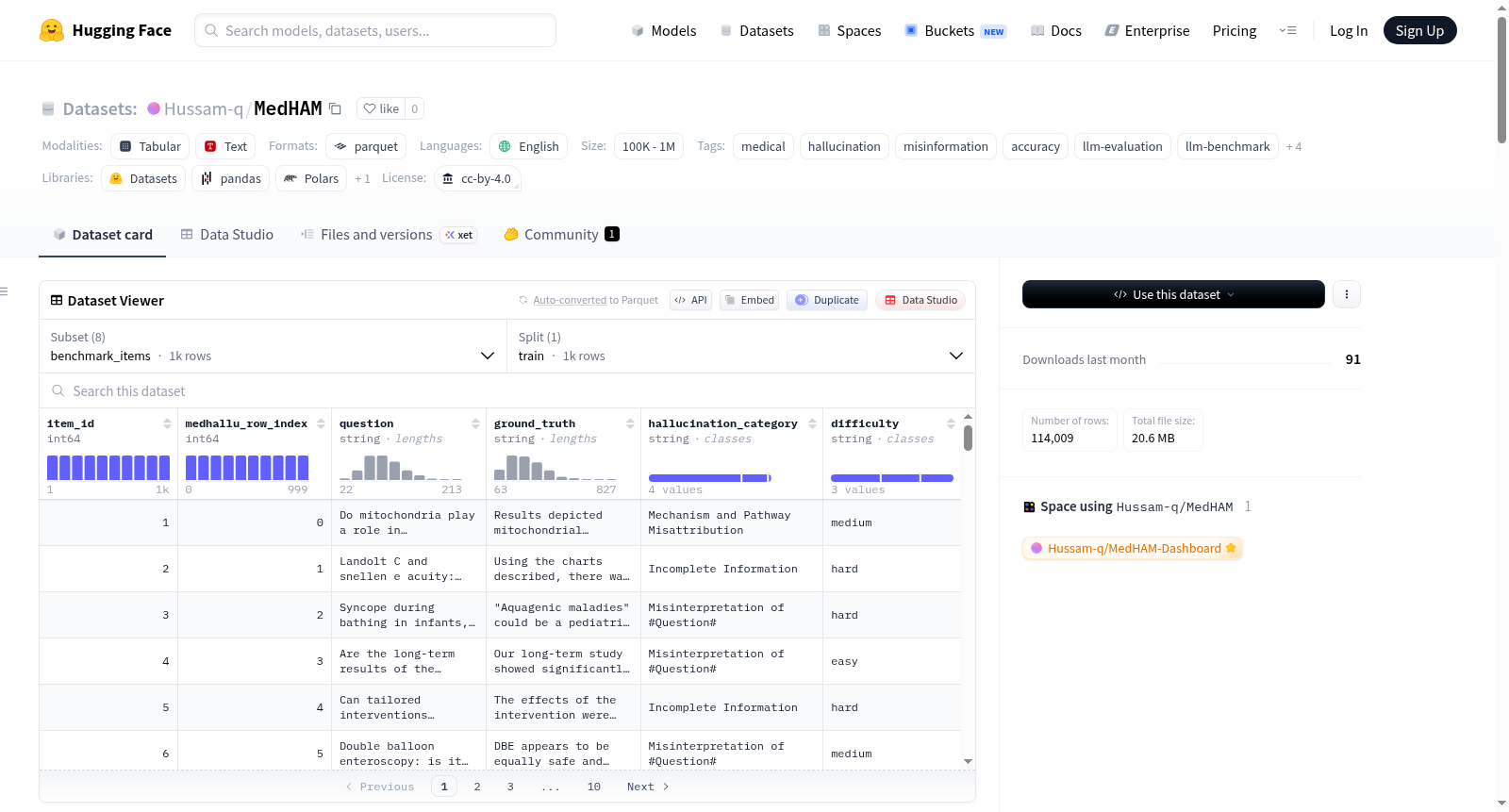
MedHAM是一个多层评估数据集,用于测量大型语言模型在回答基于证据的医学问题时产生的幻觉、准确性和错误信息。该数据集通过一个五层自动化管道生成,结合了BioBERT语义相似性、MedNLI推理、引用验证、FActScore事实基础和四法官LLM面板。数据集支持研究《评估大型语言模型在医学问答中的幻觉、准确性和错误信息:检索增强生成与引用提示的比较研究》。数据集包含8个表格,分别涵盖基准项目、模型、提示策略、RAG上下文、模型响应、评估信号、法官评估和评估结果。
MedHAM is a multi-layer evaluation dataset measuring hallucination, accuracy, and misinformation across four large language models answering evidence-based medical questions. It was produced by a 5-layer automated pipeline combining BioBERT semantic similarity, MedNLI inference, citation verification, FActScore factual grounding, and a 4-judge LLM panel. The dataset supports the study "Evaluating Hallucination, Accuracy, and Misinformation in Large Language Models for Medical Question Answering: A Comparative Study of Retrieval-Augmented Generation and Citation Prompting". The dataset consists of 8 tables covering benchmark items, models, prompt strategies, RAG contexts, model responses, evaluation signals, judge evaluations, and evaluation results.
提供机构:
Hussam-q
搜集汇总
数据集介绍
构建方式
MedHAM数据集基于MedHallu基准测试中的pqa_labeled子集,精心遴选出1000道经过人工验证的循证医学问题与真实答案。研究团队采用2×2析因实验设计,融合检索增强生成(RAG)与提示格式(零样本与引用要求)两大变量,构建出四种差异化的提示策略。随后,邀请GPT-4o、Claude Sonnet 4.6、Gemini 2.5 Flash及Llama 3.1 8B四款大型语言模型,在每种策略下生成回答,共计16000条原始响应。这些响应经过一个五层自动化流水线的深度剖析,依次运用BioBERT语义相似度、MedNLI蕴含推理、引用真实性核查、FActScore事实性评估以及四位专家级评判模型的盲审投票,最终将多源信号聚合成精确、幻觉与错误信息的三维评价标签。
使用方法
使用者可通过HuggingFace的datasets库或直接读取Parquet文件轻松加载MedHAM的八个核心表格。以evaluation_results为主干,可获取每条响应的精度、幻觉与错误信息标签及其共识分数;结合evaluation_signals可分析自动化评估信号与最终标签的关联;通过model_responses与judge_evaluations则可复现完整的评审过程。数据集支持灵活的多表联查:可按模型、提示策略或问题难度筛选数据子集,亦可利用预设的外键关系,构建从问题到响应再到多层评估的完整分析链路。其标准化的表格结构与详尽的列描述,极大地便利了临床自然语言处理领域的基准测试与提示工程研究。
背景与挑战
背景概述
MedHAM数据集诞生于大语言模型在医学问答领域快速发展的背景下,由Hussam-q等研究团队创建,其核心研究问题聚焦于系统评估大语言模型在医学事实性问答中的幻觉、准确性与错误信息传播现象。该数据集发表于2024年,依托MedHallu基准中的1000条经人工验证的医学问题,构建了一个包含五层自动化评估管线的综合性基准。通过整合BioBERT语义相似度、MedNLI推理、引用验证、FActScore事实核查及四模型陪审团投票,MedHAM为衡量大语言模型在医学信息生成中的可靠性提供了迄今为止最为细致的多维度评估框架,对推动可信医学AI的发展具有里程碑式的影响。
当前挑战
MedHAM所应对的核心挑战在于大语言模型在医学问答中普遍存在的‘幻觉’现象——模型会生成看似合理但事实错误的回答,这一问题在零样本场景下尤为突出。此外,构建过程中面临的挑战包括:如何从MedHallu基准中筛选出能够有效触发幻觉的多样性医学问题,以及设计严格的自动化评估管线以平衡语义匹配、逻辑推理与引用真实性的多信号融合。研究还面临评估一致性的难题——需要让四个不同模型的陪审团在无自评偏差的前提下达成共识,同时确保自动化信号与人类判断呈现方向性一致,这涉及复杂的投票权重分配与指标聚合策略。
常用场景
经典使用场景
在大型语言模型(LLM)于医学领域的应用浪潮中,确保其生成内容的真实性与可靠性已成为核心挑战。MedHAM数据集应运而生,其最经典的用途在于系统性地评估医学问答情境下LLM的幻觉、准确性与错误信息现象。该数据集精心设计了包含检索增强生成(RAG)与引用提示的2×2因子实验框架,覆盖了从零样本到引用要求的四种提示策略,并整合了GPT-4o、Claude、Gemini及Llama等主流模型。通过多维度分层评估管线,研究者能够精准量化模型在回答循证医学问题时虚构事实、输出不准确信息或传播误导性内容的倾向,为理解LLM在关键领域中的行为边界提供了标准化的测试基石。
解决学术问题
MedHAM精准回应了LLM在医学领域采纳中所面临的核心学术困境——如何超越单一的准确率指标,系统性地解构和量化模型输出的幻觉、准确性与错误信息等相互关联却本质迥异的缺陷。该数据集通过五层自动化评估管线,集成BioBERT语义相似度、MedNLI矛盾检测、引用真实性验证、FActScore原子声明核查以及四位LLM盲审小组投票,构建了从微观语义到宏观事实的全方位诊断框架。其引入的“共识追踪”机制(Track Consensus)能够识别自动化信号与人工评判之间的偏离,为学术界揭示了现有自动化评估方法在捕捉复杂医学谬误时的局限性,推动了关于LLM在安全敏感领域可信性评估方法论的重要思考与演进。
实际应用
在临床辅助决策与医学知识传播的现实场景中,MedHAM数据集的价值尤为凸显。它可以作为医疗AI系统的出厂前的质量验证工具,帮助开发者在模型部署前全面筛查其对常见医学知识点是否存在编造引用、混淆病因或遗漏关键禁忌等高风险行为。医疗机构可利用该数据集筛选出最适合提供预诊咨询或药物信息核对的LLM,而临床医生则能通过数据集中揭示的常见错误模式,更警觉地辨析AI辅助生成的诊疗建议中的潜在陷阱。此外,教育机构可将其用于医学AI素养培训,通过真实案例提升学生对模型输出进行批判性评估的能力,从而在医生-AI协作的闭环中筑起一道坚实的安全防线。
数据集最近研究
最新研究方向
MedHAM数据集的诞生标志着大语言模型在医学问答领域的可信度评估迈入系统化时代。该基准聚焦于幻觉检测与虚假信息治理两大前沿议题,通过构建包含医学语义相似度、自然语言推理、引文验证及事实核验的五层自动化评估流水线,对GPT-4o、Claude等顶尖模型在检索增强生成与引文提示策略下的表现展开全景式剖析。其分层评估框架不仅量化了不同技术范式对模型事实性的影响,更为医疗AI领域的数据溯源、知识忠实度与结果可解释性提供了可复现的评估范式,呼应了全球对负责任医疗人工智能的迫切需求。
以上内容由遇见数据集搜集并总结生成


