cometadata/pmc-oa-funding-acknowledgement-statements
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/cometadata/pmc-oa-funding-acknowledgement-statements
下载链接
链接失效反馈官方服务:
资源简介:
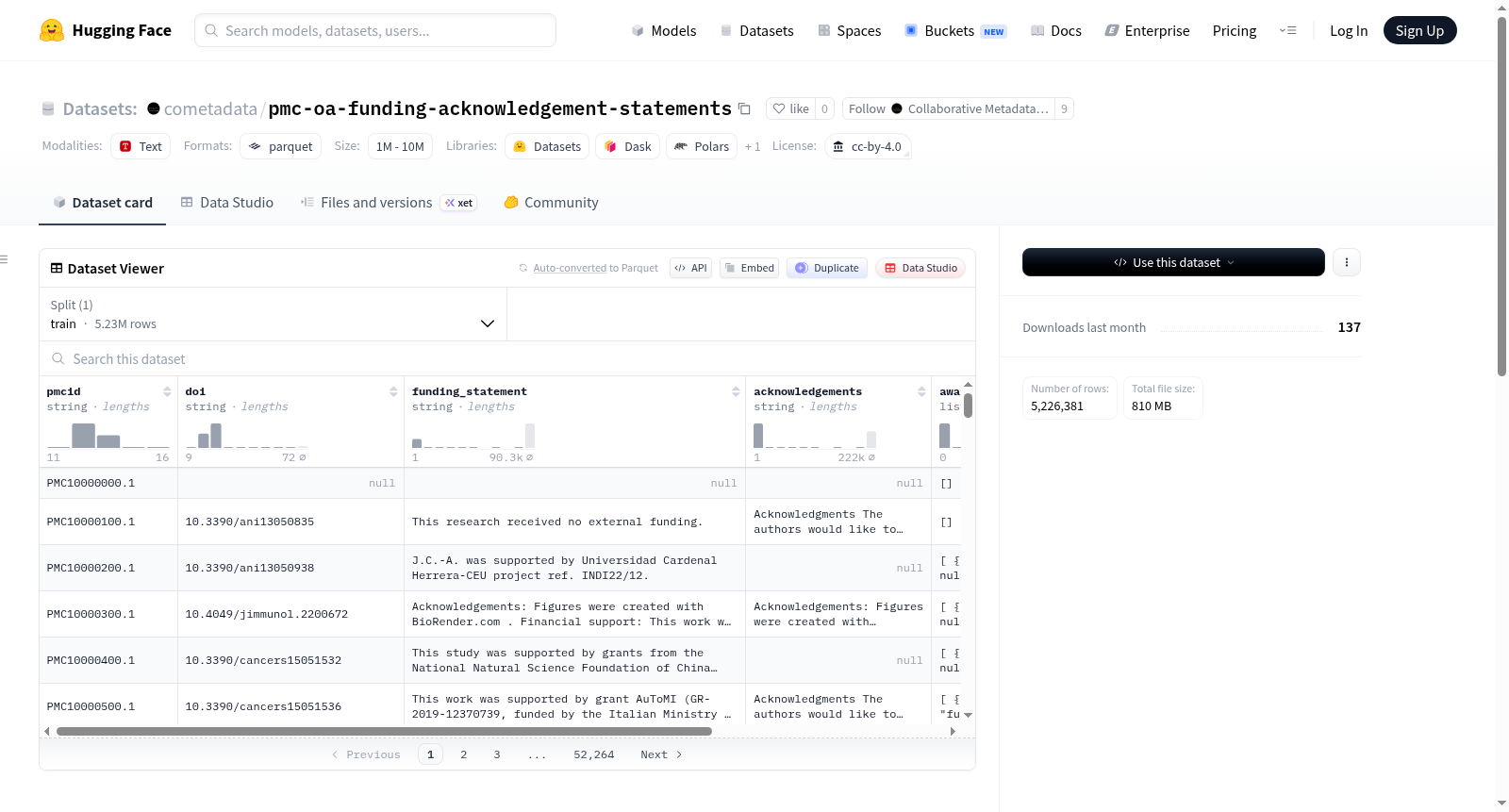
PMC开放获取资助与致谢声明数据集包含从PMC开放获取子集(仅限CC0和CC BY文章)中提取的资助声明、致谢文本和结构化资助元数据。数据集包含多个字段,如版本化的PMCID(pmcid)、DOI(doi)、资助声明文本(funding_statement)、致谢文本(acknowledgements)以及奖项列表(awards)等。数据集总共有5,226,381行数据,分布在100个parquet文件中,总大小约为810 MB。数据来源于NIH/NLM PMC开放获取子集,通过AWS开放数据平台提供。
The PMC OA Funding & Acknowledgements Statements dataset contains funding statements, acknowledgements text, and structured funding metadata extracted from the PMC Open Access Subset (CC0 + CC BY articles only). The dataset includes fields such as versioned PMCID (pmcid), DOI (doi), funding statement text (funding_statement), acknowledgements text (acknowledgements), and a list of awards (awards). The dataset consists of 5,226,381 rows across 100 parquet files (~810 MB). The source is the NIH/NLM PMC Open Access Subset, available via AWS Open Data.
提供机构:
cometadata
搜集汇总
数据集介绍
构建方式
该数据集源自NIH/NLM维护的PMC开放获取子集,仅筛选采用CC0或CC BY许可的学术文献。通过解析JATS XML结构,从<funding-statement>标签中提取基金声明,从<ack>标签中提取致谢文本,同时利用正则表达式从致谢散文中识别并恢复类资助字符串。对于每个资助条目,系统化地记录奖励编号、资助机构标识、名称及来源(结构化元数据来源标记为funding-group,文本恢复来源标记为ack),最终汇聚成包含超过522万条记录的高质量语料库。
特点
该数据集以精细化结构著称,每条记录包含版本化PMCID、DOI及三类核心字段:基金声明、致谢文本和结构化资助元数据。其中资助元数据以列表形式呈现,整合奖励编号、资助机构ID及名称,并通过source字段清晰区分元数据来源。数据规模达810MB,由100个Parquet文件组成,采用zstd压缩以兼顾存储效率与读取性能,为学术资助分析提供了兼具广度与深度的高密度信息基础。
使用方法
数据加载极为便捷,通过HuggingFace datasets库的单行命令即可完成:load_dataset('cometadata/pmc-oa-funding-acknowledgement-statements')。用户可直接获取包含pmcid、doi、funding_statement、acknowledgements及awards字段的数据集,进而灵活进行统计分析、实体识别或知识图谱构建等下游任务。Parquet格式的列式存储特性亦支持高效的数据筛选与聚合操作,适合大规模学术影响力及资助模式研究。
背景与挑战
背景概述
在生物医学研究领域,科研经费的透明性与致谢信息的规范化对于评估学术影响力、追踪研究资助脉络以及促进开放科学具有重要意义。然而,传统的基金致谢信息散落于学术论文的各个角落,缺乏系统性的结构化提取与整合手段。为此,由cometadata团队于近期构建了PMC OA Funding & Acknowledgements数据集,该数据集从NIH/NLM管理的PMC开放存取子集中提取,仅选取CC0与CC BY许可的文章,共计超过500万条记录。数据集涵盖了基金声明、致谢文本及结构化资助元数据,旨在为科研计量学、资助政策分析及知识图谱构建等领域提供高质量的基础数据资源。其发布填补了大规模结构化生物医学资助信息数据集的空白,推动了开放获取文献中隐性资助信息的显性化与可计算化进程。
当前挑战
该数据集面临的核心挑战涵盖两大层面。在领域问题层面,生物医学文献中存在大量非结构化的资助信息,尤其是嵌入在致谢段落中的资助描述,其表述方式多样且缺乏统一格式,导致自动化提取极易产生遗漏或错误,现有自然语言处理方法难以确保高精度与高召回率的平衡。在构建过程层面,数据清洗面临诸多技术难题,包括跨版本PMCID的版本管理、非标准DOI的兼容处理、以及从致谢文本中通过正则表达式识别资助编号时可能引入的虚假正例。此外,多源数据结构(如JATS元数据与自由文本致谢)的融合需要设计稳健的逻辑映射,而更新频率与数据一致性维护也成为可持续运营的隐性挑战。
常用场景
经典使用场景
在生物医学文献计量与科学资助政策研究领域,PMC OA Funding & Acknowledgement Statements数据集为解析科研经费脉络提供了不可多得的语料宝库。该数据集以PMC开放获取子集中CC0与CC BY协议文章为基底,精炼提取了超过522万条资金声明、致谢文本及结构化资助元数据,不仅囊括了JATS标准标签下的基金信息,还通过正则表达式从致谢散文中捕捉到隐含的资助线索。其经典使用场景在于系统性地分析不同资助机构、国家与学科领域的科研投入格局,揭示资金流向与学术产出之间的内在关联,为科研政策制定与资源配置优化提供数据驱动的实证依据。
实际应用
在实际应用层面,该数据集为科研管理决策平台与学术影响力评估工具注入了关键动力。科研资助机构可据此绘制自身资助项目的学术产出地图,动态监测资金使用的长期效益并优化拨款策略;高校与研究机构能借助资助网络分析识别潜在合作伙伴,强化跨学科协作布局;学术出版平台则能够整合元数据,在论文页面自动生成资金信息可视化摘要,提升学术记录的透明度和可追溯性。此外,科技智库与政策研究团队可利用该数据集开展国家间科研投入差距比较,为制定更为公平高效的全球科研协作框架提供数据支撑。
衍生相关工作
基于此数据集,学术界已衍生出一系列高影响力的研究工作。模型层面,研究者将结构化资助信息与论文引用网络相融合,构建资助影响力预测模型,探索不同基金项目对论文长期学术影响的异质性效应。在分析框架方面,有工作开发了资助链路追溯算法,识别同一研究项目在不同论文中的连续资助声明,从而重构完整的研究项目生命历程。此外,该数据集的致谢文本为本体工程与命名实体识别任务提供了优质训练语料,催生了专门针对基金名称与资助编号的序列标注工具,进一步拓展了生物医学知识图谱中资助关系的自动化抽取能力。
以上内容由遇见数据集搜集并总结生成


