nba_players_draft_analysis_tamir_sela
收藏Hugging Face2025-11-18 更新2025-11-19 收录
下载链接:
https://huggingface.co/datasets/tamir25/nba_players_draft_analysis_tamir_sela
下载链接
链接失效反馈官方服务:
资源简介:
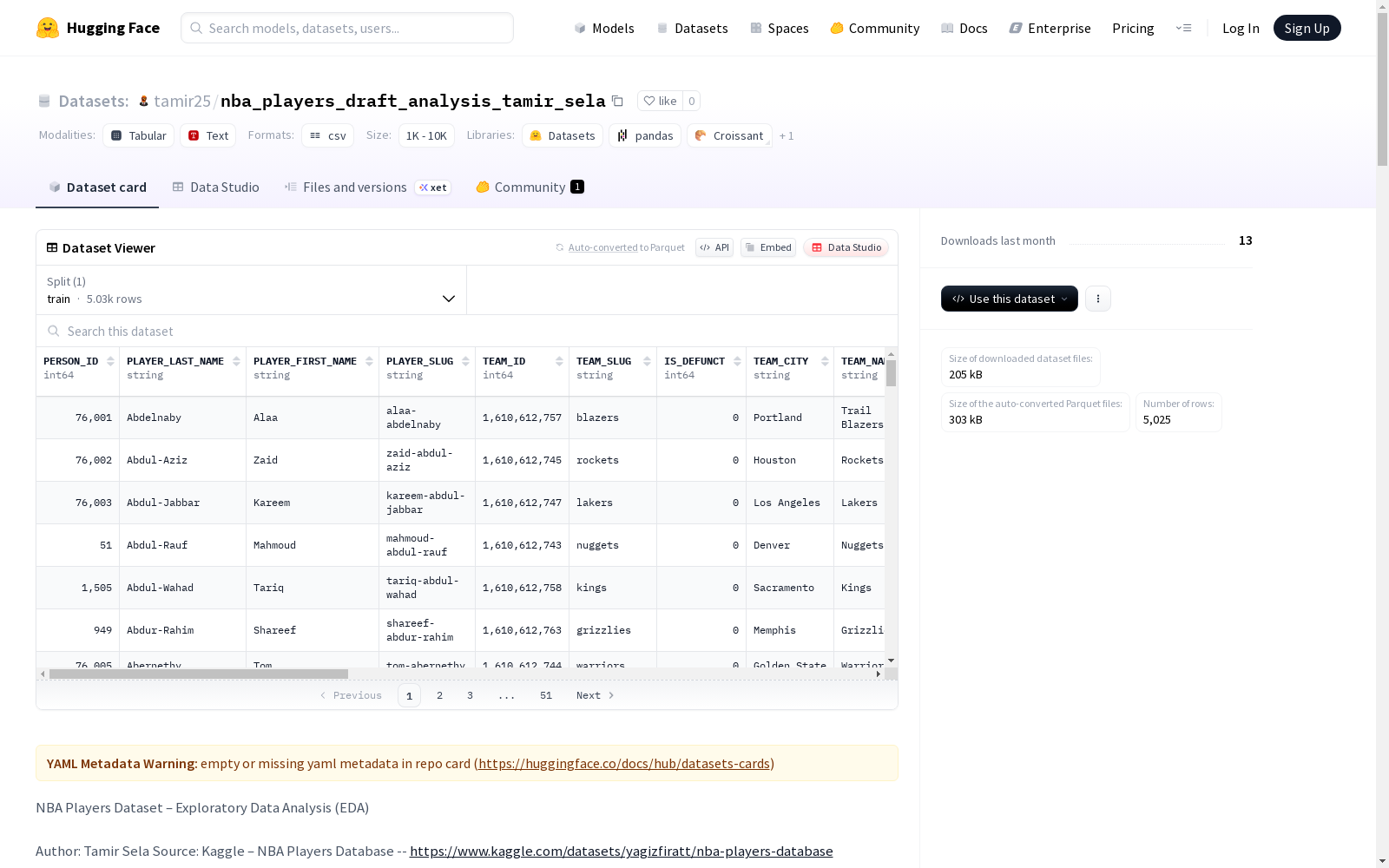
NBA球员数据集,包含超过5000名球员的统计信息,用于分析不同选秀年份的球员平均每场比赛得分情况,探究哪些年份的球员在进攻端表现最为出色。
创建时间:
2025-11-13
原始信息汇总
NBA球员选秀分析数据集概述
数据集基本信息
- 数据集名称: NBA Players Dataset – Exploratory Data Analysis (EDA)
- 作者: Tamir Sela
- 数据来源: Kaggle NBA Players Database (https://www.kaggle.com/datasets/yagizfiratt/nba-players-database)
- 数据规模: 超过5,000名NBA球员记录
研究目标
确定场均得分最高的球员来自哪些NBA选秀年份
数据准备
- 从Kaggle加载数据集
- 清理缺失值和重复值
- 保留分析相关列:球员名、选秀年份、场均得分
- 将选秀年份转换为整数并移除空值
探索性数据分析
数据清理
- 移除选秀年份和场均得分中的缺失值
异常值检测
- 保留场均得分超过30分的异常值,代表真实精英球员
描述性统计
- 整体平均得分:约7.0分
- 中位数得分:约5.8分
- 大多数球员场均得分低于10分
主要研究发现
选秀年份得分趋势
- 现代球员不一定得分更高,趋势线显示轻微波动但无强烈上升趋势
突出选秀年份
- 2003年和2017年等选秀年份超过整体平均7分,表明这些是进攻能力特别强的选秀班
得分分布特征
- 大多数NBA球员场均得分低于10分
- 小部分精英球员贡献了大部分总得分
结论
- 少数选秀年份表现突出,但整体得分水平随时间保持相对稳定
- 大多数NBA球员得分贡献有限,突显顶级球员的统治地位
- 分析展示了数据清理、可视化和探索性数据分析在揭示体育数据真实模式中的重要性
可视化图表
- 场均得分分布图: https://cdn-uploads.huggingface.co/production/uploads/6915d91530500b43788834d7/7aZNLIgOXYx_Njkvw4rHB.png
- 选秀年份得分趋势图: https://cdn-uploads.huggingface.co/production/uploads/6915d91530500b43788834d7/fxW5q-lj9tEHo8Khfxckk.png
- 选秀年份对比图1: https://cdn-uploads.huggingface.co/production/uploads/6915d91530500b43788834d7/YSuURf1UZh9zHu83m9MWC.png
- 选秀年份对比图2: https://cdn-uploads.huggingface.co/production/uploads/6915d91530500b43788834d7/wtyZPUpuMvTx2Dn_kmgRK.png
- 球员得分分布图: https://cdn-uploads.huggingface.co/production/uploads/6915d91530500b43788834d7/7bB5Du46_B_RVjjAmAgBO.png
搜集汇总
数据集介绍
构建方式
在职业篮球数据分析领域,该数据集源自Kaggle平台的NBA球员数据库,涵盖超过5000名球员的完整档案。构建过程采用系统化数据清洗流程,首先剔除存在缺失值与重复记录的条目,随后聚焦于球员姓名、选秀年份和场均得分等核心字段。通过将选秀年份转换为整型数据并过滤空值,形成可用于统计建模的标准化数据集。
特点
该数据集呈现出职业篮球运动员得分能力的典型分布特征,整体场均得分均值维持在7.0分左右,中位数约为5.8分,反映出多数球员得分集中在10分以下的分布规律。特别值得注意的是,数据保留了场均30分以上的极端值,这些记录真实体现了顶级得分手的竞技水平,为研究精英球员群体提供了关键样本。
使用方法
研究者可借助该数据集开展多维度的篮球统计分析,通过选秀年份与得分数据的关联性研究,能够识别出像2003届、2017届等产出高效得分手的黄金选秀年。数据可视化模块支持生成选秀年得分趋势线、球员得分分布直方图等专业图表,为球队管理层评估选秀质量、制定引援策略提供量化依据。
背景与挑战
背景概述
职业体育数据分析领域自21世纪以来逐渐成为运动科学的重要分支,由数据科学家Tamir Sela于2023年基于Kaggle平台发布的NBA球员数据库构建的选秀分析数据集,聚焦于探索选秀年份与球员得分能力的关联性。该研究通过量化分析五千余名球员的生涯数据,旨在揭示不同选秀批次产出精英得分手的规律,为球队人才选拔与竞技体育预测模型提供数据支撑。
当前挑战
在篮球运动员能力评估领域,传统球探报告与统计指标常难以精准量化选秀潜力,该数据集需解决选秀年份与长期得分稳定性关联的复杂建模问题。数据构建过程中面临历史档案缺失、跨赛季统计标准不一等挑战,尤以早期选秀记录数据完整性不足为显著难点,同时需通过异常值保留策略平衡真实精英球员数据与统计噪声的矛盾。
常用场景
经典使用场景
在体育数据分析领域,该数据集被广泛用于探索NBA选秀年份与球员得分表现之间的关联。通过整合超过5000名球员的统计数据,研究者能够系统分析不同选秀批次球员的进攻效率,揭示选秀策略对球队得分能力的潜在影响。此类分析常借助可视化工具呈现得分趋势分布,为评估选秀质量提供量化依据。
解决学术问题
该数据集有效解决了体育统计学中关于选秀价值评估的经典问题。通过纵向比较不同年代选秀球员的场均得分,研究者能够验证选秀年份与球员进攻贡献的相关性,驳斥了现代球员必然更具得分效率的普遍假设。其意义在于建立了可复用的数据分析框架,为职业体育的人才评估体系提供了实证基础。
衍生相关工作
基于该数据集的探索性分析范式,衍生出多项球员综合评价研究。后续工作扩展了防守效率、职业生涯长度等维度,构建了更全面的球员价值评估模型。在方法层面,其数据清洗流程与异常值处理策略被广泛应用于体育数据挖掘领域,促进了统计学习方法在运动科学中的交叉融合。
以上内容由遇见数据集搜集并总结生成


