thesaurus-linguae-aegyptiae/tla-Earlier_Egyptian_original-v18-premium
收藏Hugging Face2024-06-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/thesaurus-linguae-aegyptiae/tla-Earlier_Egyptian_original-v18-premium
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含古埃及早期(即古埃及古王国和中王国时期)的句子,以象形文字和转写形式呈现,并附有词形还原、词性标注、注释和德语翻译。数据集仅包含新王国开始之前(公元前16世纪末)的文本见证。数据来源于Thesaurus Linguae Aegyptiae数据库的第18版语料库,仅包含完整且明确可读的句子(共12,773句,占55,026句中的一部分),并经过语言学和编辑标记的调整。数据集可用于训练象形文字到转写的翻译模型、创建词形还原工具以及训练转写到德语的翻译模型。
该数据集包含古埃及早期(即古埃及古王国和中王国时期)的句子,以象形文字和转写形式呈现,并附有词形还原、词性标注、注释和德语翻译。数据集仅包含新王国开始之前(公元前16世纪末)的文本见证。数据来源于Thesaurus Linguae Aegyptiae数据库的第18版语料库,仅包含完整且明确可读的句子(共12,773句,占55,026句中的一部分),并经过语言学和编辑标记的调整。数据集可用于训练象形文字到转写的翻译模型、创建词形还原工具以及训练转写到德语的翻译模型。
提供机构:
thesaurus-linguae-aegyptiae
原始信息汇总
数据集概述
数据集描述
- 名称: Thesaurus Linguae Aegyptiae, Original Earlier Egyptian sentences, corpus v18, premium
- 语言: 古埃及语(egy),德语(de)
- 多语言性: 多语种
- 大小类别: 10K<n<100K
- 许可证: CC BY-SA 4.0
- 任务类别: 翻译、词性标注
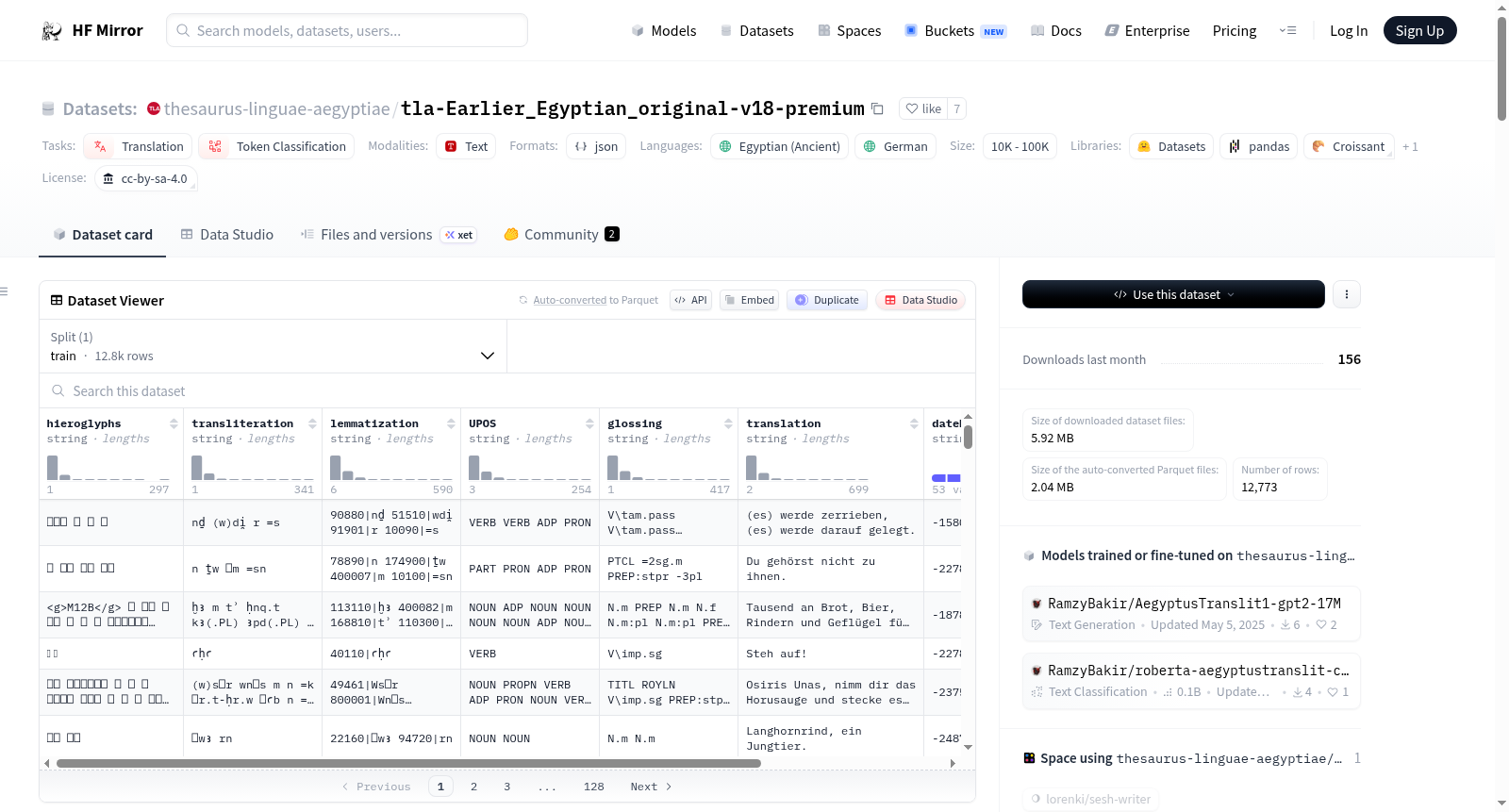
数据集结构
特征
- hieroglyphs: 字符串,埃及象形文字序列
- transliteration: 字符串,埃及学音译
- lemmatization: 字符串,词形还原
- UPOS: 字符串,通用词性标签
- glossing: 字符串,词形标注
- translation: 字符串,德语翻译
- dateNotBefore: 字符串,文本见证的最早日期
- dateNotAfter: 字符串,文本见证的最晚日期
数据分割
- train: 12773个样本
数据实例
json { "hieroglyphs": "𓆓𓂧𓇋𓈖 𓅈𓏏𓏭𓀜𓀀 𓊪𓈖 𓈖 𓌞𓏲𓀀 𓆑", "transliteration": "ḏd.ꞽn nm.tꞽ-nḫt pn n šms.w =f", "lemmatization": "185810|ḏd 851865|Nmt.j-nḫt.w 59920|pn 400055|n 155030|šms.w 10050|=f", "UPOS": "VERB PROPN PRON ADP NOUN PRON", "glossing": "V\tam.act-cnsv PERSN dem.m.sg PREP N.m:stpr -3sg.m", "translation": "Nun sagte dieser Nemti-nacht zu seinem Diener:", "dateNotBefore": "-1939", "dateNotAfter": "-1630" }
数据集创建
数据来源
数据来自Thesaurus Linguae Aegyptiae数据库,版本18。
数据收集和处理
数据集包含所有古埃及语句子,满足以下条件:
- 无损坏
- 无可疑读物
- 包含象形文字编码
- 完全词形还原(且词形有音译和词性)
- 有德语翻译
标注过程
音译有时包含圆括号(( )),表示编辑添加的音素,但不视为遗漏错误。象形文字有时包含尚未纳入Unicode的符号,这些符号用JSesh代码标记。
使用场景
直接使用
- 训练翻译模型:埃及象形文字 => 埃及学音译
- 创建词形还原器:古埃及语音译 => TLA词形ID
- 训练翻译模型:古埃及语音译 => 德语
超出范围的使用
该数据集不适合用于重建完整的古代源文本。
搜集汇总
数据集介绍
构建方式
在埃及学与计算语言学交叉领域,构建高质量的古埃及语数据集对于推动语言模型研究至关重要。本数据集源自Thesaurus Linguae Aegyptiae(TLA)语料库第18版,由柏林-勃兰登堡科学院与莱比锡萨克森科学院联合编纂。构建过程严格筛选了公元前16世纪之前的新王国时期原始文本,仅保留完整无损、无歧义阅读且完全词形还原的句子。专家团队依据莱顿统一转写标准,对圣书体字符进行Unicode编码,并剔除了大量文献学标记,最终从55,026个句子中精选出12,773条高质量数据,形成结构化的JSON行格式文件。
特点
该数据集在古埃及语研究领域展现出独特的学术价值。其核心特征在于多维度的语言标注体系:每条数据均包含圣书体原文、埃及学转写、词形还原标识符、通用词性标签、形态标注及德语译文。特别值得注意的是,词形还原采用稳定的TLA引理ID系统,有效解决了圣书体书写元音缺失导致的同形异义问题。数据集严格遵循时间边界标注原则,每条记录均附带精确的年代上下限标识,为历时语言学研究提供了可靠的时间锚点。这种多层次、跨语言的标注结构,为机器翻译、词形还原和跨语言分析任务奠定了坚实基础。
使用方法
在数字人文研究框架下,该数据集为古埃及语计算分析开辟了新的路径。研究者可直接利用其平行语料特性,训练圣书体到转写文字的序列转换模型,或构建早期埃及语到德语的神经机器翻译系统。对于语言学分析任务,可基于词形还原标识符开发自动词形还原工具,或利用通用词性标签进行句法模式挖掘。使用前需注意数据预处理:转写中的圆括号表示编者补充音素,模型训练时可选择性移除括号符号;部分尚未纳入Unicode的圣书体字符采用JSesh编码系统标注,需通过专用字形库进行解析。建议研究者根据具体任务需求创建随机划分的训练验证集。
背景与挑战
背景概述
在数字人文与计算语言学领域,古埃及语文本的数字化处理构成了一个极具学术价值的研究方向。Thesaurus Linguae Aegyptiae (TLA) 项目由柏林-勃兰登堡科学院与莱比锡萨克森科学院联合主导,其数据集“tla-Earlier_Egyptian_original-v18-premium”于2024年正式发布,核心研究人员包括Daniel A. Werning等学者。该数据集聚焦于古埃及早期语言,即古埃及语和中古埃及语的原始句子,旨在通过提供象形文字、转写、词元化、词性标注及德语翻译等多层次标注,为古埃及语的机器翻译、词元分析与跨语言理解建立高质量语料基础。它不仅推动了埃及学研究的定量化转型,也为自然语言处理技术在低资源历史语言上的应用开辟了新的路径。
当前挑战
该数据集致力于解决古埃及语自动处理中的核心挑战,即从象形文字到现代语言的精准翻译与语言学分析。由于古埃及语缺乏元音标注且存在大量同音词,词元化与语义消歧面临显著困难。在构建过程中,挑战主要源于原始文本的残缺与解读模糊性,数据集仅筛选了完全完整且无疑问的句子,这虽提升了数据质量,却限制了语料规模与文本连贯性。此外,象形文字Unicode编码的尚未完全覆盖以及转写中编辑标记的存在,为数据标准化与模型训练增添了技术复杂性。这些因素共同构成了利用计算手段深度解析古埃及语言遗产的主要障碍。
常用场景
经典使用场景
在古埃及语言学研究领域,该数据集为学者提供了早期埃及语(包括古埃及语和中埃及语)的标准化语料。其经典使用场景在于训练从埃及象形文字到埃及学转写的自动翻译模型,同时支持基于莱顿统一转写系统的词形还原与词性标注任务。数据集包含完整的句子实例,每条数据均配有象形文字、转写、词元化、词性标注及德语翻译,为构建跨模态语言处理系统奠定了坚实基础。
实际应用
在实际应用层面,该数据集支撑着文化遗产数字化项目,例如博物馆智能导览系统中的古文献实时解读工具。教育机构可基于此开发交互式古埃及语学习平台,而考古学研究则能借助其翻译模型快速解析新出土碑文。数据集的德语翻译标注更促进了跨语言文化研究,为多语种古籍知识库构建提供核心语料资源。
衍生相关工作
该数据集已衍生出多项经典研究工作,包括基于注意力机制的象形文字序列到转写序列的神经机器翻译模型。在词元化任务中,研究者利用其稳定的TLA词元ID体系开发了古埃及语形态分析器。另有学者结合词性标注与时间标注特征,构建了早期埃及语语法结构的历时演化图谱,推动了计算历史语言学方法在古文字领域的创新应用。
以上内容由遇见数据集搜集并总结生成


