cultural-spyfall
收藏Hugging Face2026-01-15 更新2026-01-16 收录
下载链接:
https://huggingface.co/datasets/haryoaw/cultural-spyfall
下载链接
链接失效反馈官方服务:
资源简介:
Multicultural Spyfall数据集是一个动态基准测试框架,用于评估大型语言模型(LLMs)的多语言和多元文化能力。该数据集基于社交推理游戏'Spyfall',包含多种语言(英语、中文、印尼语、埃及阿拉伯语)和文化背景(中国、埃及、印度尼西亚的本地食物和地点)的游戏历史记录。数据集结构包括通用语言配置和本地文化特定配置,每个条目包含完整的对话历史、玩家角色、问题、答案、投票记录和游戏结果。
创建时间:
2026-01-13
原始信息汇总
数据集概述
基本信息
- 数据集名称: Multicultural Spyfall
- 数据集地址: https://huggingface.co/datasets/haryoaw/cultural-spyfall
- 许可证: MIT
- 任务类别: 文本生成、文本分类、问答
- 语言: 英语 (en)、中文 (zh)、印度尼西亚语 (id)、埃及阿拉伯语 (arz)
- 数据规模: 1K<n<10K
- 标签: 文化、社交推理游戏、评估、游戏历史
数据集简介
该数据集包含来自 Multicultural Spyfall 的游戏历史记录。Multicultural Spyfall 是一个动态基准测试框架,旨在评估大型语言模型的多语言和跨文化能力。该框架基于社交推理游戏 Spyfall。在此设置中,模型扮演玩家角色,必须进行战略对话,以识别“间谍”(一个不知道秘密位置的智能体),或者如果他们是间谍,则要避免被识别并猜出秘密位置。
该基准测试在不同语言和文化背景下评估模型,重点关注:
- 多语言性能:游戏使用英语、中文、印度尼西亚语和埃及阿拉伯语进行。
- 跨文化细微差别:场景涉及与文化相关的实体,例如中国、埃及和印度尼西亚特有的本地食物和地点。
- 战略推理:评估在非英语环境中的规则遵循和战略完整性。
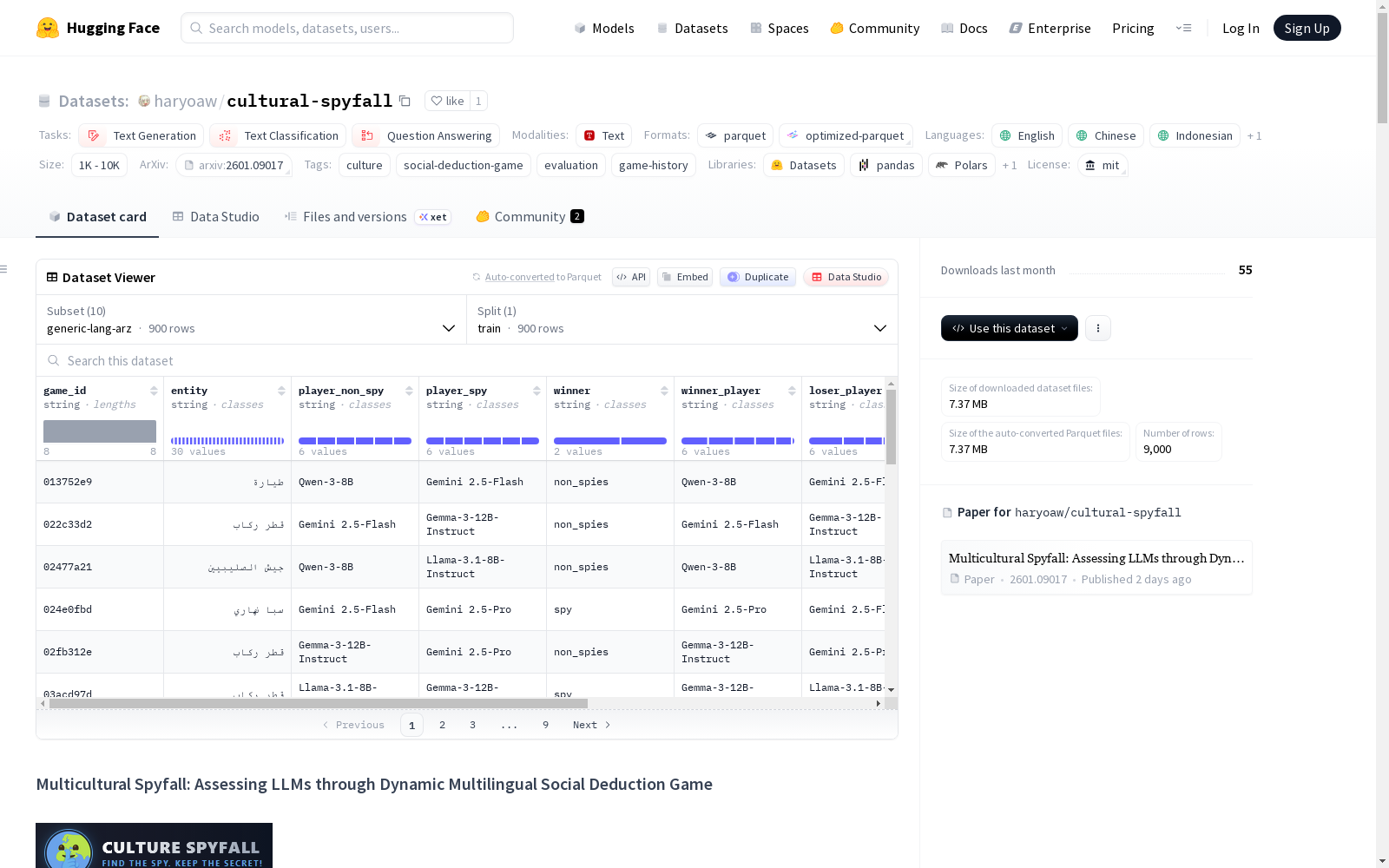
数据集结构
数据集分为多个配置,每个配置对应一种特定的游戏主题和语言组合。所有配置均仅包含训练集。
配置列表
- generic-lang-arz: 使用原始 Spyfall 游戏中的通用地点,语言为埃及阿拉伯语。
- generic-lang-en: 使用原始 Spyfall 游戏中的通用地点,语言为英语。
- generic-lang-id: 使用原始 Spyfall 游戏中的通用地点,语言为印度尼西亚语。
- generic-lang-zh: 使用原始 Spyfall 游戏中的通用地点,语言为中文。
- local-food-cn-lang-zh: 围绕中国特有的区域性食物展开,语言为中文。
- local-food-egy-lang-arz: 围绕埃及特有的区域性食物展开,语言为埃及阿拉伯语。
- local-food-id-lang-id: 围绕印度尼西亚特有的区域性食物展开,语言为印度尼西亚语。
- local-location-cn-lang-zh: 围绕中国的地标和特定地点展开,语言为中文。
- local-location-egy-lang-arz: 围绕埃及的地标和特定地点展开,语言为埃及阿拉伯语。
- local-location-id-lang-id: 围绕印度尼西亚的地标和特定地点展开,语言为印度尼西亚语。
数据规模详情
| 配置名称 | 训练集样本数 | 训练集大小(字节) | 下载大小(字节) | 数据集大小(字节) |
|---|---|---|---|---|
| generic-lang-arz | 900 | 2,986,920 | 779,141 | 2,986,920 |
| generic-lang-en | 900 | 2,967,105 | 743,473 | 2,967,105 |
| generic-lang-id | 900 | 2,766,513 | 673,672 | 2,766,513 |
| generic-lang-zh | 900 | 2,748,095 | 726,363 | 2,748,095 |
| local-food-cn-lang-zh | 900 | 2,692,973 | 714,898 | 2,692,973 |
| local-food-egy-lang-arz | 900 | 2,843,531 | 728,979 | 2,843,531 |
| local-food-id-lang-id | 900 | 2,887,943 | 663,331 | 2,887,943 |
| local-location-cn-lang-zh | 900 | 2,798,328 | 799,358 | 2,798,328 |
| local-location-egy-lang-arz | 900 | 3,001,438 | 812,659 | 3,001,438 |
| local-location-id-lang-id | 900 | 3,034,812 | 749,610 | 3,034,812 |
数据字段
所有配置共享一套核心数据特征(local-food-id-lang-id 配置额外包含一个 players 字段)。
顶级字段
game_id: 唯一的游戏对局标识符。entity: 间谍需要找出的秘密实体(例如:地点、食物)。player_non_spy: 扮演非间谍角色的模型。player_spy: 扮演间谍角色的模型。winner: 获胜的角色(间谍或非间谍)。winner_player: 赢得游戏的模型。loser_player: 输掉游戏的模型。last_type: 游戏的最后一个动作类型。spy_guess表示间谍猜测,vote_majority表示游戏以投票多数结束,surrender表示游戏过程中出现格式问题。game_players: 玩家名称与扮演该玩家的模型之间的映射关系列表。model_name: 模型名称。name: 玩家名称。
conversation: 每场对局中对话历史的列表。
对话条目字段
每个对话条目是一个包含以下20个键的字典:
| 字段名 | 描述 | 数据类型 |
|---|---|---|
accused |
投票中被指控的玩家 | string |
action |
正在执行的动作类型 | string |
answer |
玩家对问题的回答 | string |
answerer |
提供答案的玩家 | string |
correct |
间谍对地点的猜测是否正确 | bool |
first_questioner |
游戏中第一个提问的玩家 | string |
guess |
间谍对地点的猜测 | string |
is_spy_surrendering |
投降的玩家是否是间谍 | bool |
num_players |
游戏中的玩家总数 | int64 |
question |
玩家提出的问题 | string |
questioner |
提出问题的玩家 | string |
round |
当前回合数 | int64 |
spy |
间谍的玩家标识符 | string |
surrendering_player |
投降的玩家 | string |
suspect |
投票中被怀疑的玩家 | string |
target |
提问的目标玩家或猜测的目标地点 | string |
voter |
投票的玩家 | string |
votes |
获得的票数 | int64 |
was_spy |
被指控的玩家是否确实是间谍 | bool |
winner |
游戏获胜方(间谍/非间谍) | string |
相关论文
- 论文标题: Multicultural Spyfall: Assessing LLMs through Dynamic Multilingual Social Deduction Game
- 论文链接: https://huggingface.co/papers/2601.09017
搜集汇总
数据集介绍
构建方式
在社交推理游戏领域,Multicultural Spyfall数据集通过模拟经典游戏《Spyfall》的交互过程构建而成。该数据集采用多语言、多文化情境下的自动化游戏对局生成方式,利用大型语言模型扮演玩家角色,围绕通用或特定文化实体展开对话。构建过程涵盖了英语、中文、印尼语和埃及阿拉伯语四种语言,并设计了基于通用场景、地方美食和地方场所的多样化配置,每一局游戏均完整记录了从角色分配、问答交互到投票裁决的全流程对话历史与元数据。
特点
该数据集的核心特征体现在其深度的多语言与跨文化维度。它不仅覆盖了四种差异显著的语言,更通过引入中国、埃及和印度尼西亚等地区的本土化实体,如地方特色食物与地标,深入考察文化背景对语言模型理解与推理的影响。数据结构上,每条记录均包含完整的游戏会话序列,细致刻画了玩家行为、问答内容、投票决策及胜负结果,为分析智能体在社交推理中的战略完整性、规则遵循能力和跨文化适应性提供了丰富而系统的语料。
使用方法
在自然语言处理与多智能体评估研究中,该数据集可用于系统评测语言模型在多语言社交推理任务中的表现。研究者可通过加载特定配置(如local-food-cn-lang-zh)获取对应文化语境下的游戏历史,进而分析模型在问答生成、角色隐藏、间谍识别等子任务上的能力。数据中的对话序列、动作类型及胜负标签支持对模型战略行为、跨语言泛化及文化常识理解的定量与定性评估,为推进包容性、情境化的人工智能系统提供基准支持。
背景与挑战
背景概述
在人工智能与自然语言处理领域,评估大型语言模型的多语言与跨文化理解能力已成为一项前沿课题。Cultural-Spyfall数据集应运而生,其构建灵感源于社交推理游戏《Spyfall》,旨在通过动态对话环境系统性地测评模型在多元文化语境下的战略推理与语言运用能力。该数据集由研究团队于2024年正式发布,收录了涵盖英语、中文、印尼语及埃及阿拉伯语四种语言的游戏历史记录,并融入了中国、埃及、印度尼西亚等地区的本土饮食与地标文化元素。其核心研究问题聚焦于探索模型在非母语环境中的文化适配性、战略完整性及对话连贯性,为多语言人工智能模型的公平性与鲁棒性评估提供了重要的基准框架。
当前挑战
Cultural-Spyfall数据集致力于解决多语言社交推理任务中的核心挑战,即模型在跨文化语境下进行隐蔽信息推理与战略对话的效能评估。这一领域问题的复杂性体现在模型需同时处理语言转换、文化隐喻理解及动态博弈策略生成。在数据集构建过程中,研究者面临多重挑战:其一,需确保文化特定实体(如地方食物与地标)在不同语言中的准确表达与等效性,避免因文化差异导致语义偏差;其二,游戏对话的生成需维持高度的逻辑一致性与战略真实性,以反映真实社交推理场景;其三,多语言数据的平衡采集与标注需要克服资源稀缺性与语言专家协作的壁垒,以保证数据集的代表性与可靠性。
常用场景
经典使用场景
在自然语言处理领域,评估大型语言模型的多语言与跨文化理解能力是一项核心挑战。Cultural-Spyfall数据集通过模拟经典的社交推理游戏‘Spyfall’,为研究者提供了一个动态的评估框架。该数据集记录了多轮对话、角色扮演、提问与投票的完整交互历史,其经典使用场景在于系统性地评测模型在不同语言和文化背景下的战略推理、语境理解及社会互动能力。研究人员利用这些丰富的对话轨迹,能够深入分析模型在扮演间谍与非间谍角色时的决策逻辑与语言生成质量。
衍生相关工作
围绕Cultural-Spyfall数据集,已衍生出一系列聚焦于多语言与社会推理评估的经典研究工作。这些工作主要沿着两个方向展开:一是利用该数据集的对话结构,开发新的评估指标以更精细地度量模型的战略一致性和文化知识;二是以其为基准,训练或对比不同架构的模型,探究模型规模、预训练数据多样性对跨文化推理性能的影响。相关研究进一步拓展了动态博弈在AI评估中的应用,并促进了多语言社会智能研究子领域的形成与发展。
数据集最近研究
最新研究方向
在人工智能与多语言文化交互的前沿领域,cultural-spyfall数据集为评估大语言模型在复杂社会推理任务中的表现提供了独特视角。该数据集通过模拟多语言、多文化的“间谍危机”游戏对话,聚焦于模型在英语、中文、印尼语及埃及阿拉伯语等语言环境下的战略对话与跨文化理解能力。近期研究热点围绕大语言模型在非英语语境中的战略完整性、文化常识推理以及多智能体协作展开,旨在揭示模型在处理地域性食物、地标等文化特定概念时的潜在偏差与局限。这一探索对于推动全球化、包容性人工智能系统的开发具有深远意义,为构建能够适应多元文化背景的智能体奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


