CC12M_and_Imagenet21K_Recap_Highqual_256
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/gmongaras/CC12M_and_Imagenet21K_Recap_Highqual_256
下载链接
链接失效反馈官方服务:
资源简介:
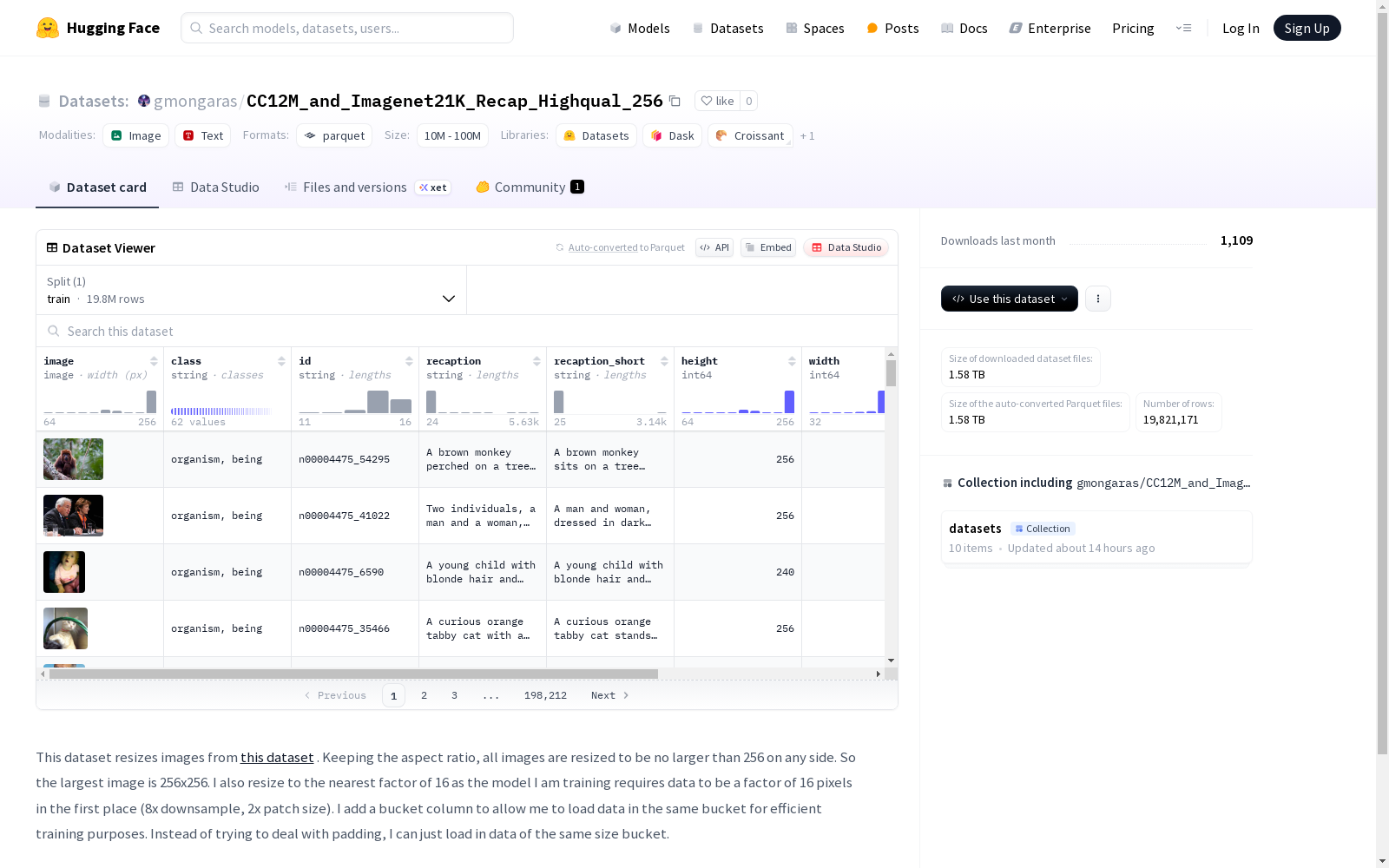
该数据集包含从另一个数据集调整大小的图片,所有图片在保持原始宽高比的前提下,任何一边的最大长度不超过256。图片大小调整到最接近的16的倍数,以满足模型训练对数据尺寸的要求。数据集中还包括图片的类别、唯一标识符、重新生成的描述(长和短版本)、高度、宽度、宽高比和存储桶大小信息。数据集分为训练集,其大小为3072353745字节,包含42443个样本。
创建时间:
2025-04-20
搜集汇总
数据集介绍
构建方式
在计算机视觉与多模态学习领域,高质量图像数据集对模型训练至关重要。CC12M_and_Imagenet21K_Recap_Highqual_256数据集基于原始数据集进行智能重构,通过保持原始宽高比将图像长边统一缩放到256像素以内,同时确保尺寸为16的整数倍以满足特定模型的输入要求。该处理流程采用分桶策略存储不同尺寸的图像,有效避免了填充操作带来的计算冗余,显著提升了训练效率。
特点
该数据集囊括42,443张经过严格筛选的图像样本,每张图像均附带类别标签、唯一标识符及长短两种版本的文本描述。其核心优势在于精确的尺寸控制与元数据完整性——不仅记录原始分辨率与宽高比,还通过分桶标记实现批处理优化。多层次的文本描述为跨模态研究提供了丰富语义线索,而统一的最大边长限制则确保了计算资源的高效利用。
使用方法
研究者可借助分桶信息实现同尺寸图像的批量加载,大幅加速训练过程。数据集内置的三种文本描述字段支持不同粒度的视觉语言任务,而标准化的图像尺寸兼容主流卷积神经网络架构。建议优先利用recaption字段进行细粒度跨模态对齐实验,结合bucket_size字段设计动态批处理策略,以充分发挥该数据集在高效训练方面的独特优势。
背景与挑战
背景概述
CC12M_and_Imagenet21K_Recap_Highqual_256数据集是基于CC12M和Imagenet21K两大知名视觉数据集构建的高质量图像资源,旨在为计算机视觉领域的研究者提供标准化的图像处理基准。该数据集由研究人员对原始图像进行智能尺寸调整,确保所有图像在保持原始宽高比的前提下,最大边长不超过256像素,同时满足16的倍数这一特定模型训练需求。这一处理策略不仅优化了存储效率,还显著提升了模型训练过程中的数据加载速度,为图像分类、目标检测等任务提供了更为高效的数据支持。
当前挑战
构建CC12M_and_Imagenet21K_Recap_Highqual_256数据集面临多重挑战。在领域问题层面,如何在不损失图像质量的前提下实现尺寸的统一调整,同时保持原始图像的宽高比,是确保后续模型训练效果的关键。技术实现上,数据集构建需精确计算每张图像的调整比例,并确保调整后的尺寸符合16的倍数这一特定要求,这对图像处理算法提出了较高要求。此外,高效的数据加载机制设计也是挑战之一,需要通过合理的分桶策略来避免训练过程中的冗余计算,这对数据集的整体架构设计提出了考验。
常用场景
经典使用场景
在计算机视觉领域,CC12M_and_Imagenet21K_Recap_Highqual_256数据集因其高质量的图像和丰富的标注信息,成为图像分类和生成模型训练的首选资源。该数据集通过保持原始图像的长宽比并将其最大边长限制为256像素,为研究者提供了标准化的输入尺寸,特别适合用于卷积神经网络和Transformer架构的预训练与微调。
解决学术问题
该数据集有效解决了大规模图像数据预处理中的尺寸标准化问题,为模型训练提供了高效的数据支持。通过将图像尺寸调整为16的倍数,避免了传统填充方法带来的信息损失,显著提升了模型训练的效率与稳定性。其丰富的类别标注和重新标注文本,为多模态学习研究提供了宝贵的跨模态对齐数据。
衍生相关工作
围绕该数据集,研究者们开展了一系列创新性工作。最具代表性的是基于视觉-语言预训练的跨模态检索系统,以及结合图像分类与文本生成的混合模型架构。这些工作不仅推动了多模态学习的发展,也为图像理解与生成任务设立了新的性能基准。
以上内容由遇见数据集搜集并总结生成


