ROME
收藏Hugging Face2025-09-02 更新2025-09-03 收录
下载链接:
https://huggingface.co/datasets/BAAI/ROME
下载链接
链接失效反馈官方服务:
资源简介:
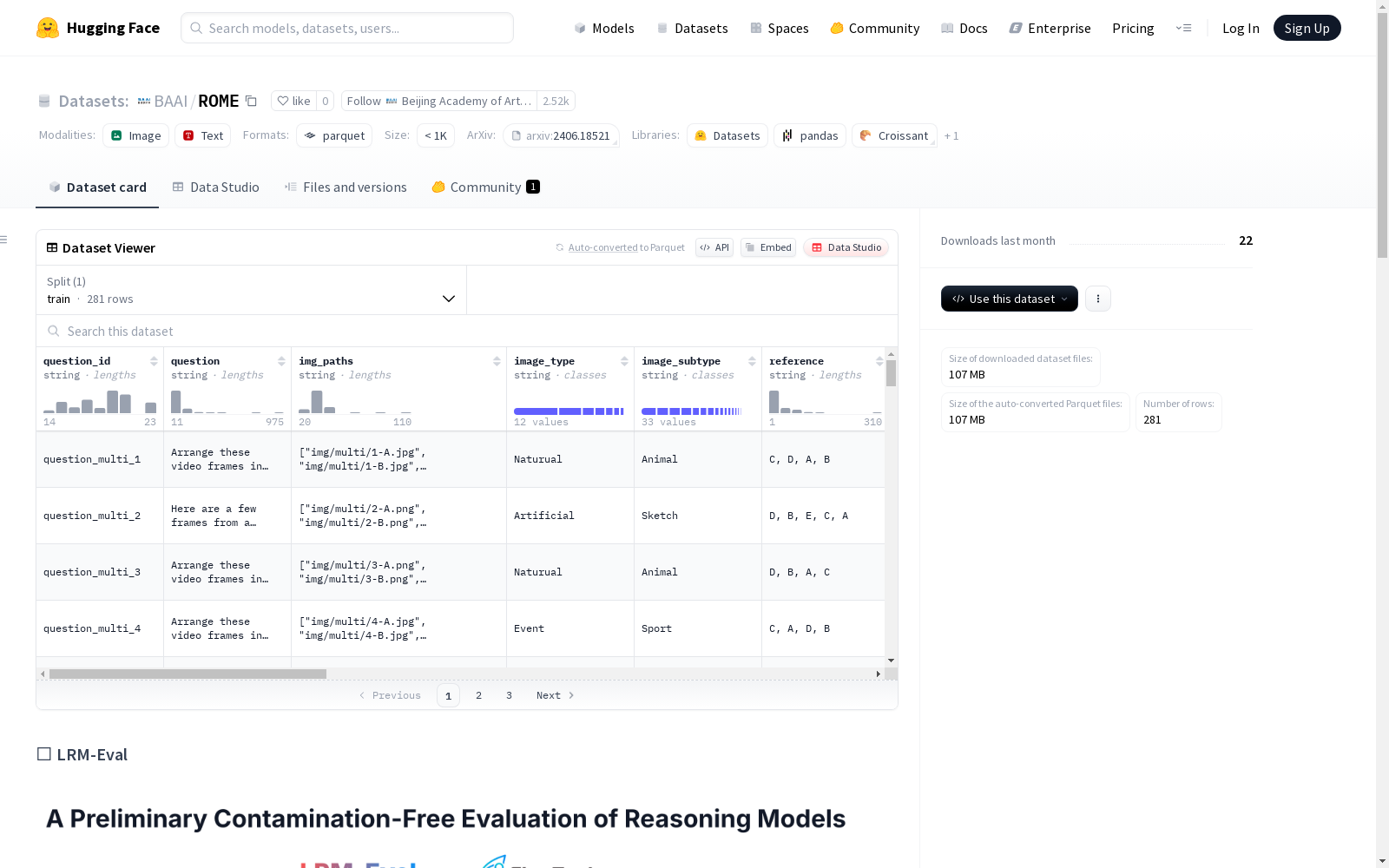
LRM-Eval是一个包含罗马评价数据的数据集,从论文《A Preliminary Contamination-Free Evaluation of Reasoning Models》中获取。该数据集包括8个子任务,总共281个高质量问题,每个样本都经过仔细检查,确保图像对于正确回答问题是必要的。问题涵盖学术、图表、谜题游戏、模因、地理推断、精细识别、多图像和空间定位等领域。
提供机构:
Beijing Academy of Artificial Intelligence
创建时间:
2025-09-02
原始信息汇总
数据集概述
基本信息
- 数据集名称:ROME
- 存储位置:https://huggingface.co/datasets/BAAI/ROME
- 论文标题:A Preliminary Contamination-Free Evaluation of Reasoning Models
- 论文链接:https://arxiv.org/abs/2406.18521
- 发布日期:2025年9月2日
数据规模
- 总样本数:281个高质量问题
- 训练集大小:108,105,743字节
- 下载大小:107,335,779字节
数据结构
特征字段
- question_id:字符串类型
- question:字符串类型
- img_paths:字符串类型
- image_type:字符串类型
- image_subtype:字符串类型
- reference:字符串类型
- question_type:字符串类型
- task_category:字符串类型
- reasoning_type:字符串类型
- evaluator:字符串类型
- evaluator_kwargs:字符串类型
- meta_info:字符串类型
- image_0至image_4:图像类型
数据划分
- 训练集:281个样本
任务分类
包含8个子任务类型:
- Academic:大学课程相关问题
- Diagrams:科学论文、报告或博客文章中的图表和图形
- Puzzles and game:瑞文测试、Rebus谜题和游戏玩法
- Memes:重现的模因
- Geo:地理定位推理
- Recognition:细粒度识别
- Multi-image:找不同或视频帧重新排序
- Spatial:相对位置、深度/距离、高度等
质量控制
每个样本都经过仔细检查,确保图像对于正确回答问题必不可少。
相关资源
- 项目主页:https://github.com/flageval-baai/LRM-Eval
- 评估代码:https://github.com/flageval-baai/ROME-evaluation
- 评估响应:https://huggingface.co/datasets/
- 排行榜:包含30+个LLM和MLLM的测试结果
引用信息
bibtex @article{LRM-Eval, title={A Preliminary Contamination-Free Evaluation of Reasoning Models}, author={BAAI FlagEval Team}, year={2025} }
搜集汇总
数据集介绍
构建方式
在视觉推理领域,ROME数据集通过精心设计的流程构建而成,涵盖学术图表、谜题游戏、地理定位等八个子任务。研究团队从大学课程、科学论文及网络资源中收集原始素材,确保每个问题必须依赖图像信息才能正确解答。所有样本均经过人工严格审核,剔除存在歧义或信息冗余的条目,最终形成包含281个高质量问题的多模态评估集。
特点
该数据集的核心特征体现在其严格的污染控制机制与细粒度标注体系。每个样本均配备五张关联图像及十余种元数据标签,包括问题类型、推理类别和任务分类等维度。特别值得注意的是其多图像设置,通过差异对比和帧序列重排等任务,有效检验模型对视觉时序和空间关系的理解能力。数据集还集成了定制化评估器,支持对模型推理过程进行可解释性分析。
使用方法
研究人员可通过HuggingFace平台直接加载数据集进行模型评估,系统自动解析图像与文本的对应关系。评估时需按照标准协议运行配套的验证脚本,该脚本会调用预设的评估器生成标准化指标报告。对于多轮对话场景,建议采用分阶段测试策略,先进行单图像推理验证,再逐步扩展至多图像复杂推理任务,以确保评估结果的可靠性。
背景与挑战
背景概述
ROME数据集由北京智源人工智能研究院(BAAI)FlagEval团队于2025年创建,旨在为多模态推理模型提供无污染的评估基准。该数据集聚焦于视觉语言推理的核心研究问题,涵盖学术图表、谜题游戏、地理定位、细粒度识别等八大子任务,共包含281个高质量样本。其设计严格确保图像信息对问题解答的必要性,推动了多模态推理模型在泛化能力和鲁棒性方面的研究进展,对人工智能领域的评估方法论产生了重要影响。
当前挑战
ROME数据集致力于解决多模态推理模型在复杂视觉语言任务中的评估挑战,包括模型对跨领域图像的语义理解、多图像关联推理以及空间关系解析等难题。构建过程中面临样本质量控制的双重挑战:一方面需确保每个问题的解答必须依赖图像信息,避免文本泄漏;另一方面需协调多样化的任务类型(如学术图表与谜题游戏),保持数据分布平衡与标注一致性,同时规避现有数据的污染风险。
常用场景
经典使用场景
在视觉推理研究领域,ROME数据集通过精心设计的八个子任务构建了多模态推理评估体系。该数据集典型应用于大型语言模型与多模态模型的联合推理能力测试,研究者利用其高质量的图像-问题对评估模型在学术图表解析、空间关系推理、谜题解答等复杂场景中的认知能力。每个样本均经过严格验证,确保视觉信息对问题解答不可或缺,为模型性能评估提供可靠基准。
解决学术问题
ROME数据集有效解决了多模态推理模型评估中的数据污染问题,为学术界提供了纯净的测试环境。其通过构建跨领域的视觉推理任务,显著提升了模型泛化能力评估的可信度,推动了推理模型在真实场景中的性能验证研究。该数据集填补了传统基准测试在思维链推理和视觉逻辑分析方面的空白,为模型透明度与一致性研究提供重要数据支撑。
衍生相关工作
基于ROME数据集的评估范式,衍生出多项关于思维链推理机制的研究工作。Gemini 2.5 Pro和GPT-5等模型在该基准上的性能分析推动了推理效率优化研究,而Claude Sonnet 4的受控思维行为发现催生了模型透明度改进方向。相关研究还拓展到多轮对话场景下的推理一致性验证,以及视觉-语言模型在对抗性样本中的鲁棒性测试等领域。
以上内容由遇见数据集搜集并总结生成


