open-index/open-wikipedia-text
收藏Hugging Face2026-04-09 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/open-index/open-wikipedia-text
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- la
license: cc-by-sa-4.0
task_categories:
- text-generation
- feature-extraction
- text-classification
- question-answering
- summarization
- translation
pretty_name: Open Wikipedia (Text)
tags:
- wikipedia
- encyclopedia
- knowledge
- plaintext
- multilingual
- wikimedia
- open-data
size_categories:
- 100K<n<1M
configs:
- config_name: la
data_files:
- split: train
path: data/la/*.parquet
dataset_info:
- config_name: la
features:
- name: id
dtype: int64
- name: title
dtype: string
- name: text
dtype: string
- name: url
dtype: string
- name: lang
dtype: string
- name: length
dtype: int32
- name: timestamp
dtype: string
splits:
- name: train
num_examples: 139421
---
# Open Wikipedia (Text)
> Every Wikipedia article as clean plain text, 139.4K articles across 1 languages
## What is it?
This dataset contains every article from every language edition of [Wikipedia](https://www.wikipedia.org/), converted from raw MediaWiki markup into **clean plain text**. All formatting, templates, references, tables, HTML tags, and wiki syntax are stripped away, leaving only the readable content of each article.
The source data comes from the official [Wikimedia database dumps](https://dumps.wikimedia.org/). Each language's full XML export is streamed, parsed, and converted article by article. The results are stored as sharded Apache Parquet files with Zstandard compression, organized by language.
This is the plain text variant of the Open Wikipedia collection. If you need Markdown with preserved headings, bold, italic, code blocks, and links, see [open-index/open-wikipedia-markdown](https://huggingface.co/datasets/open-index/open-wikipedia-markdown). If you need the original MediaWiki source markup, see [open-index/open-wikipedia](https://huggingface.co/datasets/open-index/open-wikipedia).
**139.4K articles** | **1 languages** | **Last updated: 2026-04-03** | **License: [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)**
## What is being released?
The dataset is organized as one directory per language, with sharded Parquet files inside each:
```
data/
en/en-00000.parquet English, shard 0
en-00001.parquet English, shard 1
...
de/de-00000.parquet German
fr/fr-00000.parquet French
es/es-00000.parquet Spanish
ja/ja-00000.parquet Japanese
...
la/la-00000.parquet Latin
```
Each Parquet file contains up to 500,000 rows. Languages with fewer articles fit in a single shard. All files use Zstandard compression.
## How to download and use this dataset
### Using DuckDB
DuckDB can read Parquet files directly from Hugging Face without downloading anything first.
```sql
-- Count articles per language
SELECT lang, COUNT(*) as articles
FROM read_parquet('hf://datasets/open-index/open-wikipedia-text/data/*/*.parquet')
GROUP BY lang
ORDER BY articles DESC;
```
```sql
-- Full-text search across all languages
SELECT title, lang, length, url
FROM read_parquet('hf://datasets/open-index/open-wikipedia-text/data/*/*.parquet')
WHERE text ILIKE '%artificial intelligence%'
ORDER BY length DESC
LIMIT 20;
```
```sql
-- Article length distribution for English
SELECT
percentile_disc(0.25) WITHIN GROUP (ORDER BY length) AS p25,
percentile_disc(0.50) WITHIN GROUP (ORDER BY length) AS p50,
percentile_disc(0.75) WITHIN GROUP (ORDER BY length) AS p75,
percentile_disc(0.90) WITHIN GROUP (ORDER BY length) AS p90,
percentile_disc(0.99) WITHIN GROUP (ORDER BY length) AS p99,
AVG(length)::INT AS avg_length,
MAX(length) AS max_length
FROM read_parquet('hf://datasets/open-index/open-wikipedia-text/data/en/*.parquet');
```
```sql
-- Total text volume per language (in GB)
SELECT lang, COUNT(*) AS articles,
ROUND(SUM(length) / 1e9, 2) AS text_gb
FROM read_parquet('hf://datasets/open-index/open-wikipedia-text/data/*/*.parquet')
GROUP BY lang
ORDER BY text_gb DESC
LIMIT 20;
```
```sql
-- Find the longest articles in each language
SELECT lang, title, length, url
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY lang ORDER BY length DESC) AS rn
FROM read_parquet('hf://datasets/open-index/open-wikipedia-text/data/*/*.parquet')
)
WHERE rn = 1
ORDER BY length DESC
LIMIT 20;
```
### Using `datasets`
```python
from datasets import load_dataset
# Load English Wikipedia
ds = load_dataset("open-index/open-wikipedia-text", "en")
print(ds["train"][0]["title"])
print(ds["train"][0]["text"][:500])
# Stream the full dataset without downloading everything
ds = load_dataset("open-index/open-wikipedia-text", "en", split="train", streaming=True)
for item in ds:
print(item["title"], item["length"])
# Load a specific language
ds = load_dataset("open-index/open-wikipedia-text", "de")
print(f"German articles: {len(ds['train']):,}")
```
### Using `huggingface_hub`
```python
from huggingface_hub import snapshot_download
# Download only English
snapshot_download(
"open-index/open-wikipedia-text",
repo_type="dataset",
local_dir="./wiki-text/",
allow_patterns="data/en/*",
)
```
For faster downloads, install `pip install huggingface_hub[hf_transfer]` and set `HF_HUB_ENABLE_HF_TRANSFER=1`.
### Using the CLI
```bash
# Download a single language
huggingface-cli download open-index/open-wikipedia-text \
--include "data/la/*" \
--repo-type dataset --local-dir ./wiki-text/
```
### Sentence embeddings
Plain text is the ideal input for embedding models. Here is a quick example:
```python
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
ds = load_dataset("open-index/open-wikipedia-text", "en", split="train")
model = SentenceTransformer("all-MiniLM-L6-v2")
# Embed the first 1000 article texts (truncated to 512 chars)
texts = [row["text"][:512] for row in ds.select(range(1000))]
embeddings = model.encode(texts, show_progress_bar=True)
print(f"Embeddings shape: {embeddings.shape}")
```
## Dataset statistics
### Languages
| Language | Code | Articles | Shards |
|----------|------|----------|--------|
| Latin | `la` | 139.4K | 1 |
## Schema
Every Parquet file shares the same schema:
| Column | Type | Description |
|--------|------|-------------|
| `id` | `int64` | Wikipedia page ID, unique within each language edition |
| `title` | `string` | Article title as it appears on Wikipedia |
| `text` | `string` | Full article body as plain text, all markup removed |
| `url` | `string` | Direct URL to the Wikipedia article |
| `lang` | `string` | ISO 639 language code (e.g. `en`, `de`, `fr`, `ja`) |
| `length` | `int32` | Plain text body length in bytes |
| `timestamp` | `string` | Last revision timestamp in ISO 8601 format |
### Example instance
Here is an example row from the English partition:
```json
{
"id": 12,
"title": "Anarchism",
"text": "Anarchism is a political philosophy and movement that is against all forms of authority and seeks to abolish...",
"url": "https://en.wikipedia.org/wiki/Anarchism",
"lang": "en",
"length": 65210,
"timestamp": "2025-12-15T08:22:01Z"
}
```
The `text` field contains only readable content. All wiki syntax, HTML tags, templates, references, and formatting markers have been removed.
## What gets stripped
Every element of MediaWiki markup is removed to produce clean plain text:
| Element | Handling |
|---------|----------|
| `{{templates}}` | Removed entirely, including Infobox, Navbox, Taxobox, and all other templates |
| `{| tables |}` | Removed |
| `<ref>` citations | Removed, including named references |
| `[[wiki links]]` | Replaced with the display text only (no URL, no brackets) |
| `'''bold'''` / `''italic''` | Replaced with the plain text content |
| `== Headings ==` | Replaced with the heading text only |
| `<!-- comments -->` | Removed |
| `[[File:]]` / `[[Image:]]` | Removed |
| `[[Category:]]` | Removed |
| `<code>`, `<pre>`, `<syntaxhighlight>` | Tag markup removed, content preserved as plain text |
| All other HTML tags | Removed |
| Magic words | `__NOTOC__`, `__FORCETOC__`, and similar directives are removed |
## How it works
The pipeline processes all 1 Wikipedia language editions through the following steps:
1. **Download.** The latest `{lang}wiki-latest-pages-articles.xml.bz2` dump is streamed from [dumps.wikimedia.org](https://dumps.wikimedia.org/). Downloads support HTTP range resumption, so interrupted transfers pick up where they left off.
2. **Parse.** A streaming XML parser processes the bzip2-compressed dump without extracting it to disk. Only namespace-0 pages (articles) are kept. Redirects, talk pages, user pages, and all other namespaces are skipped.
3. **Strip.** Each article's wikitext is processed to remove all markup, templates, tables, references, HTML, and formatting. Wiki links are replaced with their display text. The result is clean, readable plain text.
4. **Filter.** Articles shorter than 100 bytes after conversion are excluded. This removes stubs, disambiguation pages, and other pages with minimal content.
5. **Shard.** Articles are written to Zstandard-compressed Parquet files, approximately 500,000 rows per shard. Multiple languages are processed in parallel using a worker pool.
6. **Publish.** Each language's shards are committed to this Hugging Face repository as they complete.
## Considerations
### Why plain text?
Plain text is the right choice when you need clean input without any formatting noise. Common use cases include:
- **Text embeddings.** Embedding models work best with pure text. Markdown markers like `**` and `##` add noise that can degrade similarity scores.
- **Text classification.** Topic classifiers and sentiment models typically expect plain text input.
- **BM25 and keyword search.** Traditional information retrieval benefits from clean text without markup artifacts.
- **Tokenization and vocabulary analysis.** Formatting symbols consume tokens without adding semantic value.
If you need document structure (headings, bold, code blocks, links), use the [Markdown variant](https://huggingface.co/datasets/open-index/open-wikipedia-markdown) instead.
### Known limitations
- **Conversion is regex-based, not a full parser.** Some complex wikitext constructs may leave small artifacts. The vast majority of articles convert cleanly.
- **Templates are stripped, not expanded.** Infoboxes and navigation templates are removed entirely rather than converted to their rendered text output.
- **One snapshot in time.** This dataset represents a single snapshot of each language's dump. It does not track edit history.
- **Dump availability varies.** Not all language editions have their dumps available at all times.
## Related datasets
- [open-index/open-wikipedia-markdown](https://huggingface.co/datasets/open-index/open-wikipedia-markdown) - Same articles with Markdown formatting preserved. Headings, bold, italic, code blocks, and links are retained.
- [open-index/open-wikipedia](https://huggingface.co/datasets/open-index/open-wikipedia) - Same articles in original MediaWiki wikitext markup with templates, tables, references, and all source elements.
## Thanks
The content in this dataset was written by millions of Wikipedia editors worldwide and is hosted by the [Wikimedia Foundation](https://www.wikimedia.org/). The raw data comes from the [Wikimedia database dumps](https://dumps.wikimedia.org/), which the Foundation makes freely available for download.
Wikipedia is one of humanity's greatest collaborative achievements. All credit for the content goes to the volunteer editors who write, review, and maintain it.
This dataset is an independent conversion and is not affiliated with or endorsed by the Wikimedia Foundation.
## Licensing
Wikipedia content is released under the [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/) (CC BY-SA 4.0). This dataset inherits that license. If you redistribute or build upon this data, you must give appropriate credit and share your contributions under the same license.
## Citation
```bibtex
@dataset{open_wikipedia_text,
title = {Open Wikipedia (Text)},
author = {Open Index},
year = {2026},
url = {https://huggingface.co/datasets/open-index/open-wikipedia-text},
license = {CC BY-SA 4.0},
publisher = {Hugging Face}
}
```
_Last updated: 2026-04-03_
提供机构:
open-index
搜集汇总
数据集介绍
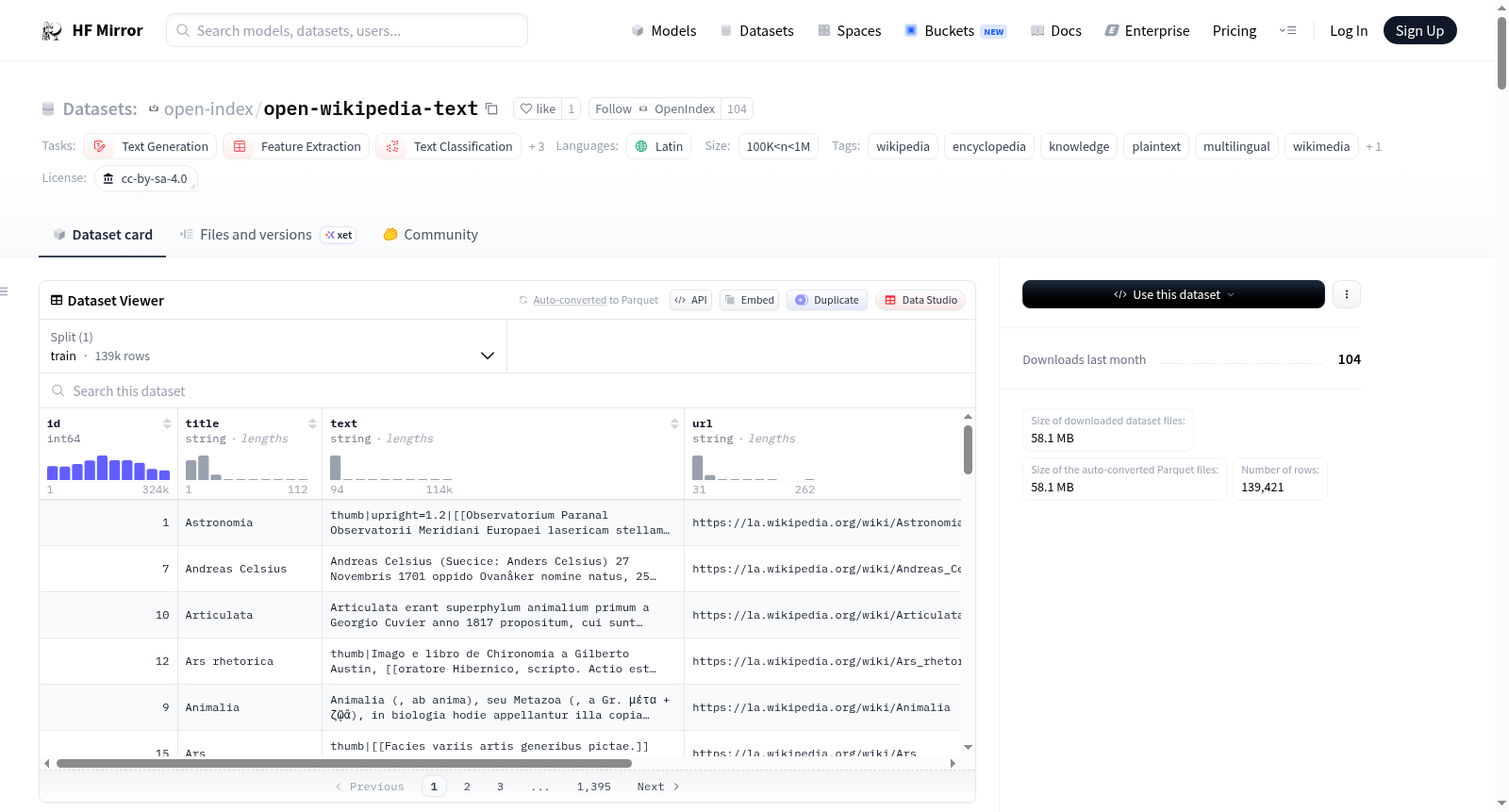
构建方式
在知识图谱构建与自然语言处理领域,大规模高质量文本语料库的获取至关重要。Open Wikipedia (Text)数据集的构建依托于维基媒体基金会官方发布的数据库转储文件,采用流式处理管道对原始MediaWiki标记语言进行深度清洗。该流程首先从dumps.wikimedia.org流式下载各语言版本的最新XML压缩包,随后通过解析器筛选出命名空间为0的标准条目文章,并运用基于正则表达式的转换引擎彻底剥离所有模板、表格、引用、HTML标签及维基语法标记,最终将纯净的文本内容以Zstandard压缩格式存储为分片Parquet文件,确保每条记录仅保留可读性内容与基础元数据。
使用方法
在实际应用层面,该数据集为研究者提供了多元化的访问接口。通过Hugging Face的datasets库可直接加载特定语言分片,支持全数据集流式读取以规避本地存储压力;利用DuckDB引擎能够直接远程执行SQL查询,实现跨语言全文检索、长度分布统计等复杂分析。对于嵌入模型训练任务,纯净文本可直接输入Sentence Transformer等框架生成语义向量。高级用户还可通过huggingface_hub选择性下载特定语种分片,或使用命令行工具进行批量数据获取,充分适应不同计算环境与研发需求。
背景与挑战
背景概述
Open Wikipedia (Text)数据集由Open Index团队于2026年构建并发布,旨在为自然语言处理领域提供经过深度清洗的纯文本维基百科语料。该数据集源于维基媒体基金会定期发布的官方数据库转储,通过自动化流程将原始MediaWiki标记语言转换为无格式干扰的纯文本内容,覆盖多种语言版本。其核心研究问题聚焦于如何高效提取并净化大规模百科全书文本,以服务于文本生成、特征提取、分类、问答及摘要等下游任务,为知识密集型语言模型训练与评估提供了标准化、高质量的数据基础,显著推动了开放知识表示与多语言理解研究的发展。
当前挑战
该数据集致力于解决从非结构化维基百科标记语言中提取纯净、连贯文本的领域挑战,其核心在于消除模板、引用、表格及复杂格式等噪声,同时保留语义完整性。构建过程中的技术挑战包括设计鲁棒的流式解析与正则清洗管道,以应对不同语言版本的标记异质性;并需平衡内容过滤策略,避免因过度清洗导致信息损失或残留标记碎片。此外,处理海量多语言数据时的存储效率与分布式处理协调,以及确保数据转换过程在时效性与准确性间的均衡,亦是关键工程难题。
常用场景
经典使用场景
在自然语言处理领域,大规模、高质量的文本语料是模型训练与评估的基石。Open Wikipedia (Text) 数据集以其纯净的文本形式,为语言模型的预训练提供了经典场景。研究者可直接利用其去除了所有标记和模板的清晰内容,进行自监督学习任务,如掩码语言建模或下一句预测,从而高效地学习语言的通用表示。
解决学术问题
该数据集有效解决了学术研究中高质量、多语言基准语料稀缺的难题。通过提供结构统一、格式纯净的维基百科文章,它支持了跨语言模型性能的公平比较、词汇分布的长尾效应分析,以及知识密集型任务中模型事实性评估等核心研究议题。其存在降低了数据清洗与预处理的壁垒,使研究者能更专注于算法与模型本身的创新。
实际应用
在实际应用层面,该数据集是构建知识密集型人工智能系统的关键资源。搜索引擎可利用其进行查询扩展与相关性排序的优化;智能问答系统能以其作为事实知识库,提升答案的准确性与覆盖面;此外,在教育科技领域,它可作为生成教学材料或构建个性化学习路径的可靠内容来源。
数据集最近研究
最新研究方向
在自然语言处理领域,维基百科作为大规模多语言知识库,其纯文本版本数据集正推动着前沿研究的深化。当前研究聚焦于利用此类清洗后的文本数据,优化多语言大语言模型的预训练与微调过程,尤其在低资源语言如拉丁语的表示学习方面展现出潜力。随着检索增强生成技术的兴起,该数据集为构建高效的知识检索系统提供了纯净语料,支持跨语言知识融合与事实性验证任务。同时,在人工智能对齐与安全研究中,纯净文本有助于减少模型训练中的格式噪声,提升生成内容的准确性与可靠性。这些方向共同体现了高质量文本资源在推动语言模型知识化、可信化发展中的核心价值。
以上内容由遇见数据集搜集并总结生成


