Ditto-1M
收藏Hugging Face2025-10-22 更新2025-10-22 收录
下载链接:
https://huggingface.co/datasets/QingyanBai/Ditto-1M
下载链接
链接失效反馈官方服务:
资源简介:
Ditto-1M是一个包含一百万个高质量视频编辑三联体的综合数据集,旨在解决指令式视频编辑的基本挑战。该数据集通过将领先图像编辑器的创意多样性与创新上下文视频生成器结合,克服了现有模型的局限性。数据集包含多种视频编辑场景,包括全局风格转换、全局自由形态编辑和局部编辑。
Ditto-1M is a comprehensive dataset encompassing one million high-quality video editing triplets, designed to address the fundamental challenges of instruction-driven video editing. This dataset overcomes the limitations of existing models by integrating the creative diversity of state-of-the-art image editors with innovative contextual video generators. The dataset covers a diverse range of video editing scenarios, including global style transfer, global free-form editing, and local editing.
创建时间:
2025-10-18
原始信息汇总
Ditto-1M数据集概述
基本信息
- 数据集名称: Ditto-1M
- 语言: 英语
- 许可证: CC-BY-NC-SA-4.0
- 规模: 大于1TB
- 任务类别: 视频到视频编辑
数据集简介
Ditto-1M是一个包含一百万高质量视频编辑三元组的综合数据集,专门为解决基于指令的视频编辑的基本挑战而设计。该数据集通过创新的数据生成流程创建,融合了领先图像编辑器的创意多样性和上下文视频生成器。
数据集特点
- 高质量合成数据: 通过自动化流程生成高质量、高度多样化的视频编辑数据
- 多样化编辑场景: 涵盖全局和局部编辑任务
- 大规模: 超过1,000,000个视频编辑三元组
编辑任务类型
- 全局风格迁移: 艺术风格变化、色彩分级和视觉效果
- 全局自由编辑: 复杂场景修改、环境变化和创意转换
- 局部编辑: 精确对象修改、属性变化和局部转换
数据集结构
Ditto-1M/ ├── mini_test_videos/ # 30+测试视频案例 ├── videos/ # 主视频数据 │ ├── source/ # 源视频(原始视频) │ ├── local/ # 局部编辑结果 │ ├── global_style1/ # 全局风格编辑 │ ├── global_style2/ # 全局风格编辑 │ ├── global_freeform1/ # 自由形式编辑 │ ├── global_freeform2/ # 自由形式编辑 │ └── global_freeform3/ # 自由形式编辑(相对困难) ├── source_video_captions/ # QwenVL生成的源视频描述 ├── training_metadata/ # 训练元数据 └── csvs_for_DiffSynth/ # DiffSynth-Studio训练用CSV文件
数据规模分布
- 源视频: ~180GB
- 全局风格: ~350GB(230GB + 120GB)
- 全局自由编辑: ~1070GB(370GB + 430GB + 270GB)
- 局部编辑: ~530GB
技术规格
- 视频分辨率: 1280×720 / 720×1280
- 视频长度: 每视频101帧
- 总样本数: 1,000,000+视频编辑三元组
元数据结构
每个元数据json文件包含三元组项目:
source_path: 源视频路径instruction: 编辑指令edited_path: 对应编辑后视频路径
质量控制
- 通过数据过滤流程处理
- 使用去噪增强器增强质量
- 指令由智能代理生成的描述和编辑指令
相关资源
- 论文: https://arxiv.org/abs/2510.15742
- 项目页面: https://ezioby.github.io/Ditto_page/
- 代码仓库: https://github.com/EzioBy/Ditto
- 模型权重: https://huggingface.co/QingyanBai/Ditto/tree/main
搜集汇总
数据集介绍
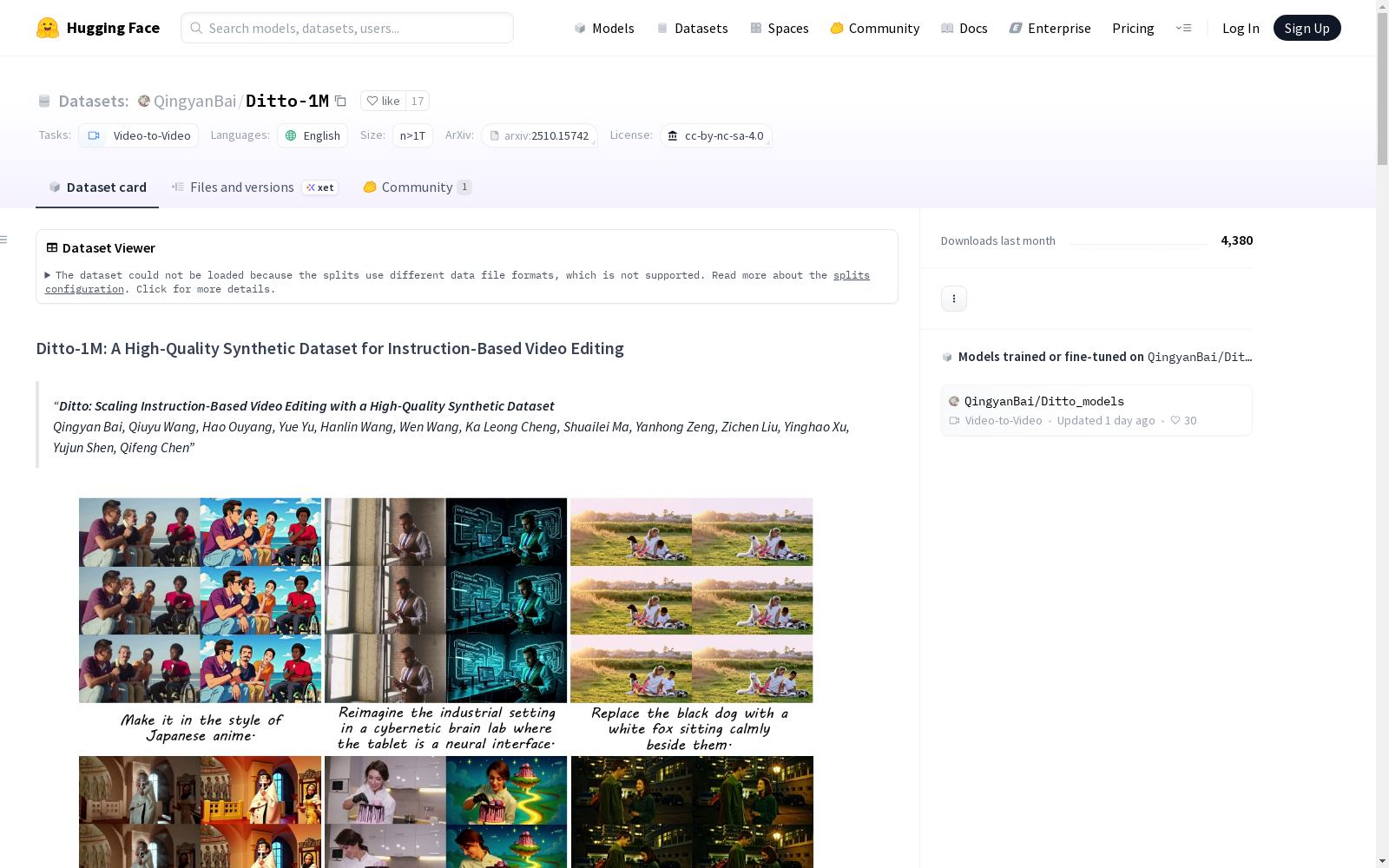
构建方式
在视频编辑领域,Ditto-1M数据集通过创新的合成数据生成流程构建而成,该流程巧妙融合了领先图像编辑器的创意多样性与上下文视频生成技术。该流程自动生成高质量的视频编辑三元组,涵盖全局风格迁移、自由形式编辑及局部对象修改等多种任务,有效克服了现有模型在指令多样性方面的局限。
使用方法
研究人员可通过HuggingFace数据集库直接加载完整数据集,或利用snapshot_download功能按需下载特定子集。数据集采用分卷压缩存储结构,支持在Linux/macOS或Windows环境下通过管道命令直接解压,有效节省存储空间。训练时可直接调用metadata中的三元组路径与编辑指令,配套提供的CSV文件还可适配DiffSynth-Studio等专业训练框架。
背景与挑战
背景概述
随着视频编辑技术的快速发展,基于指令的视频编辑成为计算机视觉领域的前沿研究方向。Ditto-1M数据集由Qingyan Bai等研究人员于2025年提出,旨在解决现有视频编辑模型在多样性和规模上的局限性。该数据集通过创新的合成数据生成流程,融合领先图像编辑器的创意多样性与上下文视频生成技术,构建了包含百万级高质量视频编辑三元组的大规模资源。其核心研究问题聚焦于如何通过自然语言指令实现精准的视频内容修改,涵盖全局风格迁移、自由形式编辑和局部对象编辑等多维度任务,为视频生成与编辑算法的突破性进展奠定了数据基础。
当前挑战
在视频编辑领域,基于指令的编辑任务面临语义理解与视觉一致性的双重挑战,需要模型准确解析复杂指令并保持时序连贯性。Ditto-1M构建过程中,研究人员需克服合成数据质量控制的难题,通过智能代理生成可信的编辑指令与对应视频对。数据规模达2TB的存储与处理要求带来了工程实现上的复杂性,需设计高效的数据流水线确保百万级样本的生成与验证。此外,涵盖全局风格转换与局部精细编辑的多样性需求,对生成算法的适应性与扩展性提出了更高要求。
常用场景
经典使用场景
在基于指令的视频编辑领域,Ditto-1M数据集通过其百万级高质量视频编辑三元组,为模型训练提供了丰富多样的场景。该数据集广泛应用于全局风格迁移任务,例如将视频转换为梵高画风或赛博朋克色调;在自由形式编辑中支持复杂场景重构,如将日间街景转化为雨夜氛围;局部编辑功能则能精准调整特定对象的属性,实现人物服饰更换或物体材质变换,为视频生成技术奠定了数据基础。
解决学术问题
该数据集有效解决了指令驱动视频编辑中数据稀缺的核心难题。传统方法受限于真实标注视频的获取成本,而Ditto-1M通过创新性合成流水线,突破了数据规模与多样性的瓶颈。其提供的精准指令-视频对映关系,显著提升了模型对复杂语义指令的理解能力,推动了视频编辑任务从特定域向开放域的跨越,为生成式人工智能在动态视觉内容创作领域的研究提供了关键支撑。
实际应用
在影视后期制作行业,该数据集训练的模型可实现智能色彩分级与特效生成,大幅降低专业剪辑的时间成本。短视频平台借助其局部编辑能力,为用户提供一键换装、背景替换等实时交互功能。教育领域则利用风格迁移技术,将历史影像自动转化为不同艺术风格的视觉教材。这些应用显著提升了视频内容生产的效率与创意表达维度,推动了视觉内容创作的民主化进程。
数据集最近研究
最新研究方向
在视频编辑领域,基于指令的生成式模型正成为前沿探索的核心方向。Ditto-1M数据集凭借其百万级高质量合成视频三元组,为全局风格迁移、自由形式编辑及局部对象修改等复杂任务提供了标准化基准。当前研究聚焦于如何利用该数据集训练大语言模型驱动的视频编辑系统,突破传统方法在语义理解与时空一致性方面的局限。随着生成式人工智能在影视制作与虚拟内容创作中的广泛应用,此类数据集正推动着可控视频生成技术的革新,为多模态交互系统的发展奠定了关键基础。
以上内容由遇见数据集搜集并总结生成


