tts-rj-hi-karya-44100hz-part-32
收藏Hugging Face2025-03-29 更新2025-03-30 收录
下载链接:
https://huggingface.co/datasets/SayantanJoker/tts-rj-hi-karya-44100hz-part-32
下载链接
链接失效反馈官方服务:
资源简介:
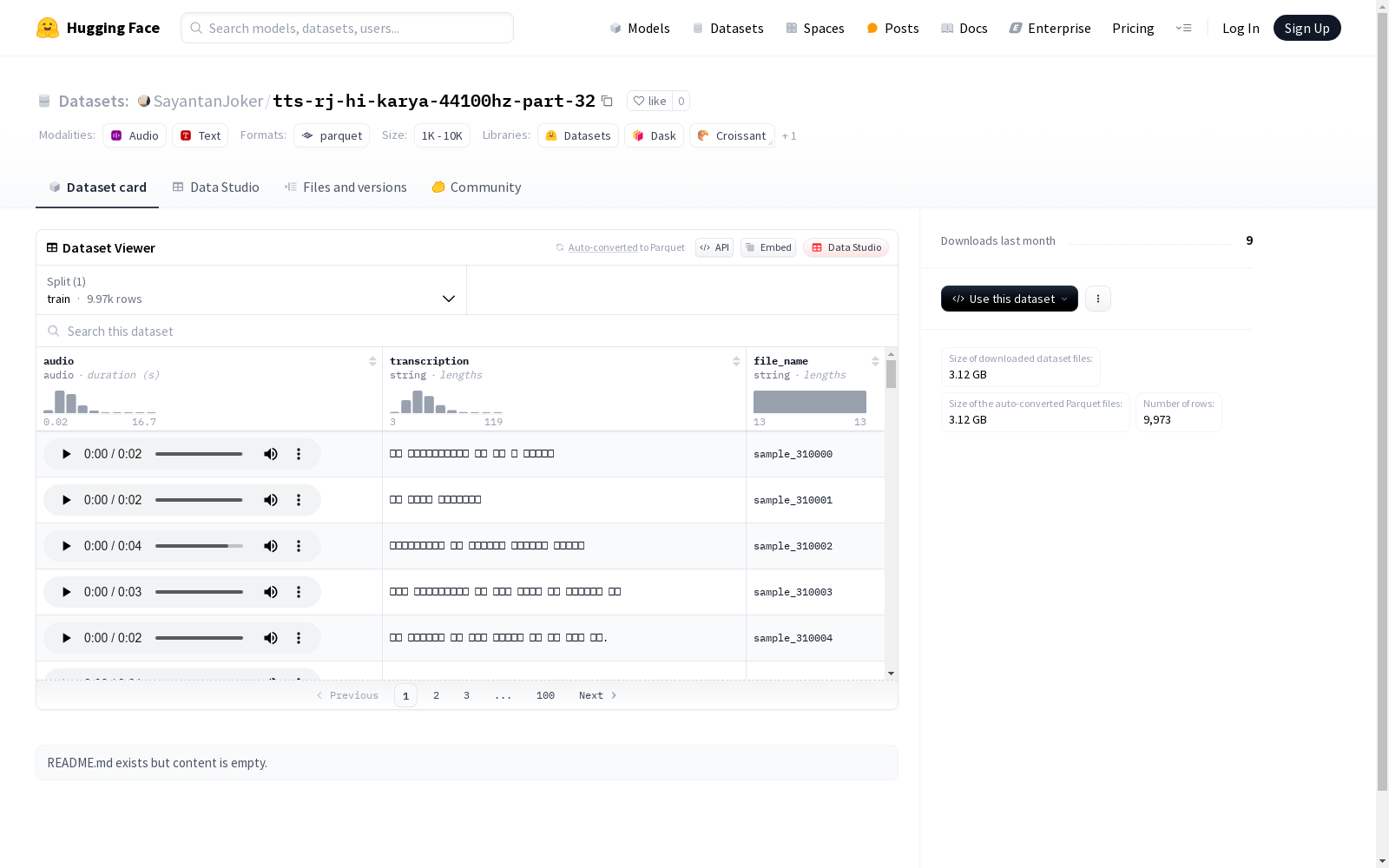
该数据集包含了音频文件及其对应的转录文本。音频文件的采样率为44100,每个音频文件都有一个对应的转录文本和文件名。数据集分为训练集,共有大约10000个示例,整个数据集的大小为3.4GB。提供了默认配置,用于指定训练集数据文件的路径。
创建时间:
2025-03-27
搜集汇总
数据集介绍
构建方式
在语音合成研究领域,高质量音频数据集的构建至关重要。tts-rj-hi-karya-44100hz-part-32数据集通过专业录音设备和标准化采集流程,收录了9973条采样率为44.1kHz的音频样本,每条音频均配有精准的文本转录。数据以训练集形式组织,总容量达3.41GB,采用分片存储技术优化下载效率,体现了现代语音数据处理的工程智慧。
特点
该数据集最显著的特征在于其CD级音频质量,44.1kHz的采样率完美覆盖人耳可闻频段,为语音合成模型提供丰富的声学细节。每条数据包含音频波形、文本转录和文件名三元组结构,支持端到端的TTS模型训练。数据规模经过科学设计,既保证模型训练的充分性,又避免冗余存储,展现了研究级数据集的专业水准。
使用方法
研究人员可通过HuggingFace数据集库直接加载该资源,利用标准接口访问音频流和对应文本。典型应用场景包括:基于深度学习的声学模型训练、语音合成系统评测、以及跨语言语音转换研究。数据的高采样特性特别适合需要宽频带合成的先进模型,建议配合现代神经网络架构如Tacotron2或FastSpeech2使用。
背景与挑战
背景概述
tts-rj-hi-karya-44100hz-part-32数据集是一个专注于高质量语音合成研究的音频数据集,由专业研究团队构建。该数据集收录了采样率为44.1kHz的音频样本及其对应文本转录,旨在为语音合成技术的开发与优化提供可靠的数据支持。其高保真音频特性为语音合成模型的训练与评估设立了新的基准,推动了语音合成领域的技术进步。
当前挑战
该数据集面临的挑战主要包括两方面:在领域问题层面,高采样率音频数据的处理对计算资源提出了更高要求,同时保持语音合成模型在如此高采样率下的自然度和清晰度是一大技术难题;在构建过程中,确保大规模音频数据与文本转录的精确对齐,以及维护音频质量的一致性,均需要精细的数据采集与处理流程。
常用场景
经典使用场景
在语音合成技术的研究中,tts-rj-hi-karya-44100hz-part-32数据集以其高质量的音频样本和精确的文本转录,成为训练和评估文本到语音(TTS)模型的理想选择。该数据集特别适用于研究印度语言的语音合成,其高采样率(44100Hz)确保了音频的清晰度和自然度,为研究者提供了丰富的语音数据资源。
解决学术问题
tts-rj-hi-karya-44100hz-part-32数据集解决了印度语言语音合成研究中数据稀缺的问题。通过提供大量高质量的语音样本和对应的文本转录,该数据集支持了语音合成模型的训练和优化,促进了印度语言语音技术的学术研究和发展。
衍生相关工作
基于tts-rj-hi-karya-44100hz-part-32数据集,研究者们开发了多种先进的语音合成模型,如基于深度学习的TTS系统和端到端的语音合成框架。这些工作进一步推动了印度语言语音合成技术的发展,并为相关领域的研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


