FaceCaption-15M
收藏Hugging Face2024-07-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/OpenFace-CQUPT/FaceCaption-15M
下载链接
链接失效反馈官方服务:
资源简介:
FaceCaption-15M是一个大规模、多样化和高质量的面部图像及其自然语言描述的数据集,包含超过1500万对面部图像和相应的自然语言描述,旨在促进以面部为中心的任务研究。数据集的构建过程包括图像收集、面部属性标注、面部描述生成和统计分析。
FaceCaption-15M is a large-scale, diverse and high-quality dataset that contains over 15 million pairs of facial images and their corresponding natural language descriptions, aiming to advance research on face-centric tasks. The dataset's construction process includes image collection, facial attribute annotation, facial description generation and statistical analysis.
创建时间:
2024-07-03
原始信息汇总
FaceCaption-15M 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 语言: 英语
- 数据量: 10M < n < 100M
- 任务类别: 图像到文本、文本到图像
- 标签: 计算机视觉、人脸、数据集
数据集描述
FaceCaption-15M 是一个大规模、多样化和高质量的人脸图像及其自然语言描述(面部图像到文本)的数据集。该数据集包含超过1500万对人脸图像及其对应的自然语言描述,是目前最大的人脸图像描述数据集。
更新记录
- 24/07/17: 发布了名为FLIP的模型。
- 24/07/06: 更新了引用信息。
- 24/07/05: 发布了FaceCaption-15M-V1版本。
数据集版本
- FaceCaption-15M-V1: 包含url、人脸框、laion_caption、face_caption等信息。
- 即将发布: HumanCaption V2版本,包含人脸图像描述、短描述和详细描述。
使用方法
python
使用Datasets库:
from datasets import load_dataset ds = load_dataset("OpenFace-CQUPT/FaceCaption-15M")
使用pandas库:
import pandas as pd df = pd.read_parquet("hf://datasets/OpenFace-CQUPT/FaceCaption-15M/FaceCaption-v1.parquet")
数据集构建流程
1.1 人脸图像收集
- 图像收集: 从LAION-Face数据集获取原始数据,该数据集包含超过5000万对图像-文本对。
- 人脸分割: 使用RetinaFace模型从LAION-Face中筛选出约3700万张含有人脸的图像,并通过裁剪、对齐和过滤,最终保留约2300万张高质量人脸图像。
1.2 人脸属性标注
- 属性设计: 设计了40个外观属性用于人脸特征描述。
- 自动标注: 使用开源算法进行自动标注,保留预测概率超过0.85的标签,并保留至少有五个有效预测标签的样本,最终数据集大小为1500万。
1.3 人脸描述生成
- 原始文本生成: 将属性标注输入设计的语法模板生成原始文本。
- 重写文本: 将原始文本输入大型语言模型(LLM)生成自然、多样和准确的文本描述。
1.4 统计分析
- 与其他人脸图像数据集的比较: 包括样本数量、平均分辨率、标注数量和平均字数等。
- 图像质量评分分布: 使用BRISQUE和CLIPIQA进行评估。
- 文本分布: 包括标注类别分布、句子字数分布、4-gram分布等。
限制与讨论
- 数据集偏见: 在数据清洗和制作过程中可能引入一定程度的偏见,将持续更新数据集以最小化偏见的影响。
- 法律合规性: 遵循LAION数据集的开源发布模式,发布图像原始链接、清洗后的文本描述和人脸在原图中的位置坐标。
- 隐私保护: 如果发现个人图像在数据集中且不希望被使用,请联系我们进行处理。
联系信息
- 邮箱: 2018211556@stu.cqupt.edu.cn 或 dw_dai@163.com
许可证信息
FaceCaption-15M数据集遵循Creative Commons Attribution 4.0 International License (CC-BY 4.0),仅限用于科研和教育目的。
引用信息
tex @misc{dai202415mmultimodalfacialimagetext, title={15M Multimodal Facial Image-Text Dataset}, author={Dawei Dai and YuTang Li and YingGe Liu and Mingming Jia and Zhang YuanHui and Guoyin Wang}, year={2024}, eprint={2407.08515}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2407.08515}, }
搜集汇总
数据集介绍
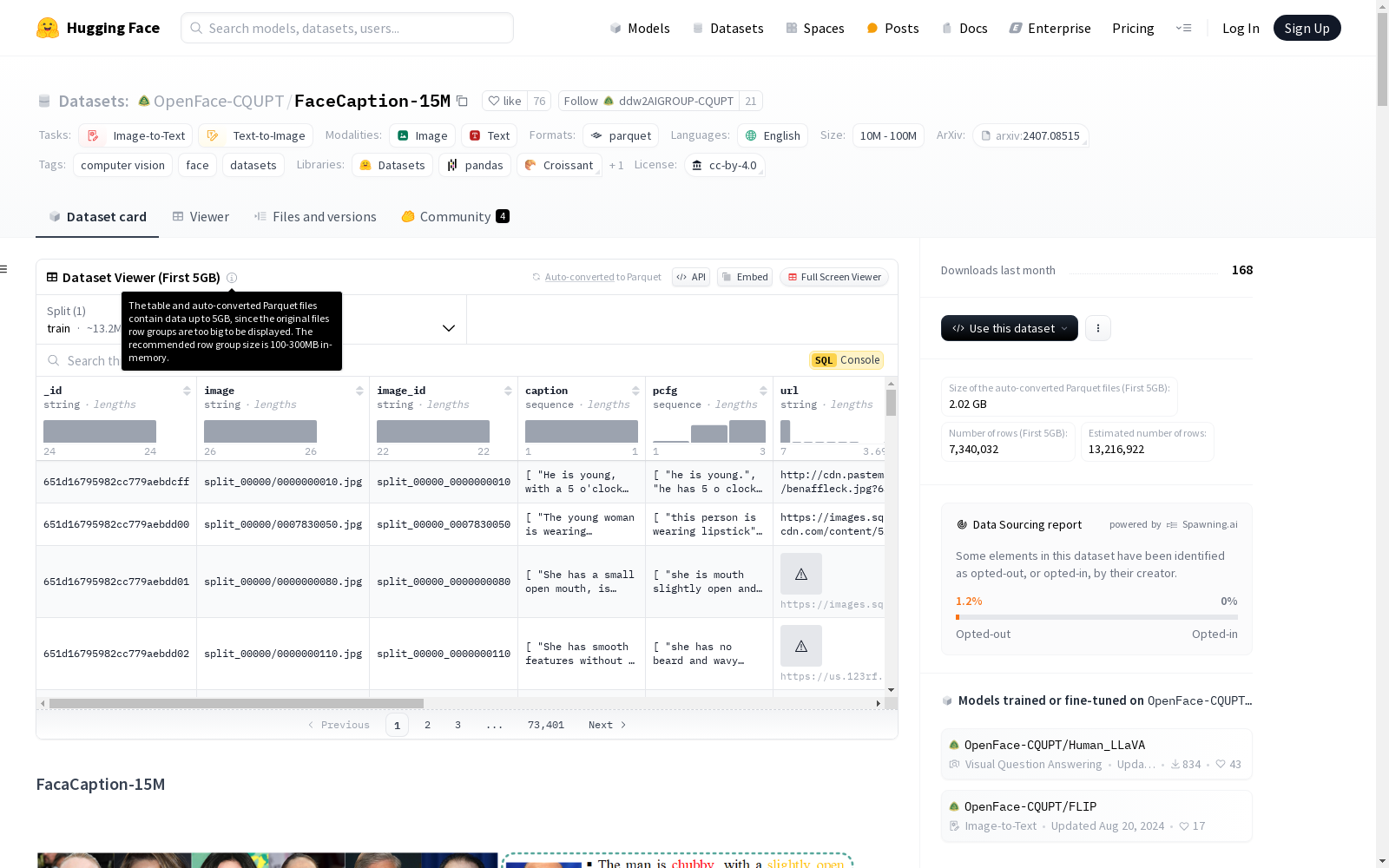
构建方式
FaceCaption-15M数据集的构建过程分为三个主要步骤。首先,从LAION-Face数据集中收集了超过50M的图像-文本对,并通过RetinaFace模型筛选出约23M的高质量面部图像。其次,设计了40个面部特征属性,并采用自动标注方法对这些图像进行属性标注,最终保留了15M个样本。最后,结合语法模板和大型语言模型(LLM)生成自然语言描述,确保文本的多样性和准确性。
特点
FaceCaption-15M是目前规模最大的面部图像-文本描述数据集,包含超过15M对高质量的面部图像及其自然语言描述。该数据集的特点在于其多样性和高质量,图像分辨率不一且未进行统一缩放,确保了数据的自然分布。文本描述通过语法模板与LLM结合生成,具有高度的自然性和多样性。此外,数据集还提供了面部属性标注,进一步增强了图像与文本之间的关联性。
使用方法
FaceCaption-15M数据集可通过Hugging Face的Datasets库或pandas库加载使用。用户可以通过简单的代码调用数据集,例如使用`load_dataset`函数加载数据集,或通过`pandas.read_parquet`读取数据文件。该数据集适用于图像到文本、文本到图像等多模态任务的研究,尤其是面部相关的计算机视觉任务。此外,基于该数据集训练的FLIP模型可用于面部图像与语义的对齐任务,进一步扩展了其应用场景。
背景与挑战
背景概述
FaceCaption-15M数据集由OpenFaceCQUPT团队于2024年发布,旨在为面部图像与自然语言描述之间的多模态研究提供支持。该数据集包含超过1500万对的面部图像及其对应的自然语言描述,是目前规模最大的面部图像描述数据集。其构建基于LAION-Face数据集,通过自动化的面部区域分割、属性标注以及结合语法模板与大语言模型(LLM)的文本生成策略,确保了数据的高质量和多样性。FaceCaption-15M的发布为面部图像理解、图像生成、多模态对齐等任务提供了重要的数据基础,推动了计算机视觉与自然语言处理领域的交叉研究。
当前挑战
FaceCaption-15M数据集在构建过程中面临多重挑战。首先,面部图像与文本描述的强相关性要求高质量的标注与生成策略,而传统自动生成方法在多样性和自然性上存在局限。为此,团队结合语法模板与大语言模型(如Qwen-7B-Chat)生成描述文本,但仍需解决模型偏见与生成质量不稳定的问题。其次,数据集的规模与多样性依赖于大规模图像来源(如LAION-Face),但网络链接失效与图像质量问题导致部分数据无法使用。此外,数据集的使用场景受到法律与伦理限制,需确保其仅用于科学研究,并避免侵犯肖像权与隐私权。这些挑战不仅影响了数据集的构建,也对其在真实场景中的应用提出了更高的要求。
常用场景
经典使用场景
FaceCaption-15M数据集在计算机视觉领域中被广泛应用于面部图像与自然语言描述之间的多模态对齐研究。通过提供超过1500万对高质量的面部图像及其对应的自然语言描述,该数据集为研究人员提供了丰富的资源,用于训练和评估图像到文本生成模型。特别是在面部识别、情感分析以及面部属性描述等任务中,FaceCaption-15M成为了一个重要的基准数据集。
衍生相关工作
基于FaceCaption-15M数据集,研究人员开发了多种经典的多模态模型,如FLIP(Facial Language Image Pretraining)模型。FLIP模型通过结合视觉变换器和文本编码器,实现了面部图像与语义的高效对齐。此外,该数据集还催生了一系列关于面部图像生成、多模态对齐以及自然语言处理的研究工作,极大地推动了相关领域的技术进步。
数据集最近研究
最新研究方向
近年来,FaceCaption-15M数据集在计算机视觉领域引起了广泛关注,尤其是在人脸图像与自然语言描述的多模态对齐任务中。该数据集通过提供超过1500万对人脸图像及其对应的自然语言描述,为人脸识别、图像生成和文本生成等任务提供了丰富的数据支持。基于FaceCaption-15M,研究者们开发了FLIP模型,该模型类似于CLIP,专注于人脸图像与语义的对齐,推动了多模态表示学习的发展。此外,随着大语言模型(LLM)的进步,研究者们结合语法模板与LLM生成高质量的自然语言描述,进一步提升了数据集的多样性和准确性。FaceCaption-15M的发布不仅为人脸相关任务提供了新的研究工具,也为多模态学习领域的创新提供了重要推动力。
以上内容由遇见数据集搜集并总结生成


