open-index/open-github-meta
收藏Hugging Face2026-04-04 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/open-index/open-github-meta
下载链接
链接失效反馈官方服务:
资源简介:
---
license: odc-by
task_categories:
- feature-extraction
language:
- en
- mul
pretty_name: OpenGitHub Meta
size_categories:
- 10M<n<100M
tags:
- github
- metadata
- issues
- pull-requests
- code-review
- open-source
- software-engineering
configs:
- config_name: issues
data_files: "data/issues/**/*.parquet"
- config_name: pull_requests
data_files: "data/pull_requests/**/*.parquet"
- config_name: comments
data_files: "data/comments/**/*.parquet"
- config_name: review_comments
data_files: "data/review_comments/**/*.parquet"
- config_name: reviews
data_files: "data/reviews/**/*.parquet"
- config_name: timeline_events
data_files: "data/timeline_events/**/*.parquet"
- config_name: pr_files
data_files: "data/pr_files/**/*.parquet"
- config_name: commit_statuses
data_files: "data/commit_statuses/**/*.parquet"
---
# OpenGitHub Meta
## What is it?
The full development metadata of 9 public GitHub repositories, fetched from the [GitHub REST API](https://docs.github.com/en/rest) and [GraphQL API](https://docs.github.com/en/graphql), converted to Parquet and hosted here for easy access.
Right now the archive has **10.4M rows** across 8 tables in **897.2 MB** of Zstd-compressed Parquet. Every issue, pull request, comment, code review, timeline event, file change, and CI status check is stored as a separate table you can load individually or query together.
This is the companion to [OpenGitHub](https://huggingface.co/datasets/open-index/open-github), which mirrors the real-time GitHub event stream via [GH Archive](https://www.gharchive.org/). That dataset tells you what happened across all of GitHub. This one gives you the full picture for specific repos: complete issue threads, full PR review conversations, the state machine from open to close.
People use it for:
- **Code review research** with inline comments attached to specific diff lines
- **Project health metrics** like merge rates, review turnaround, label usage
- **Issue triage and classification** with full text, labels, and timeline
- **Software engineering process mining** from timeline event sequences
Last updated: **2026-04-04 15:49 UTC**.
## Repositories
| Repository | Issues | PRs | Comments | Reviews | Timeline | Total | Last Updated |
|---|---:|---:|---:|---:|---:|---:|---|
| **facebook/react** | 33.7K | 19.2K | 170.6K | 20.1K | 250.0K | 859.8K | 2026-04-04 15:16 UTC |
| **golang/go** | 75.8K | 4.9K | 536.0K | 323 | 266.4K | 955.3K | 2026-04-04 15:37 UTC |
| **mdn/content** | 41.5K | 31.5K | 157.3K | 18.8K | 12.9K | 412.0K | 2026-04-04 15:28 UTC |
| **microsoft/TypeScript** | 62.1K | 19.1K | 336.6K | 41.9K | 12.4K | 1.1M | 2026-04-04 15:24 UTC |
| **python/cpython** | 145.7K | 69.8K | 864.1K | 149.8K | 20.5K | 1.9M | 2026-04-04 15:40 UTC |
| **rust-lang/rust** | 153.9K | 92.2K | 1.5M | 185.7K | 38.5K | 3.6M | 2026-04-04 15:39 UTC |
| **swiftlang/swift** | 84.4K | 66.8K | 447.2K | 108.4K | 13.1K | 1.4M | 2026-04-04 15:38 UTC |
| **vuejs/core** | 12.0K | 6.1K | 35.7K | 4.8K | 10.3K | 90.2K | 2026-04-04 09:36 UTC |
| **vuejs/docs** | 3.3K | 2.2K | 7.0K | 2.7K | 10.0K | 40.4K | 2026-04-03 19:23 UTC |
## How to download and use this dataset
Data lives at `data/{table}/{owner}/{repo}/0.parquet`. Load a single table, a single repo, or everything at once. Standard Hugging Face Parquet layout, works with DuckDB, `datasets`, `pandas`, and `huggingface_hub` out of the box.
### Using DuckDB
DuckDB reads Parquet directly from Hugging Face, no download step needed. Save any query below as a `.sql` file and run it with `duckdb < query.sql`.
```sql
-- Top issue authors across all repos
SELECT
author,
COUNT(*) as issue_count,
COUNT(*) FILTER (WHERE state = 'open') as open,
COUNT(*) FILTER (WHERE state = 'closed') as closed
FROM read_parquet('hf://datasets/open-index/open-github-meta/data/issues/**/0.parquet')
WHERE is_pull_request = false
GROUP BY author
ORDER BY issue_count DESC
LIMIT 20;
```
```sql
-- PR merge rate by repo
SELECT
split_part(filename, '/', 8) || '/' || split_part(filename, '/', 9) as repo,
COUNT(*) as total_prs,
COUNT(*) FILTER (WHERE merged) as merged,
ROUND(COUNT(*) FILTER (WHERE merged) * 100.0 / COUNT(*), 1) as merge_pct
FROM read_parquet('hf://datasets/open-index/open-github-meta/data/pull_requests/**/0.parquet', filename=true)
GROUP BY repo
ORDER BY total_prs DESC;
```
```sql
-- Most reviewed PRs by number of review submissions
SELECT
r.pr_number,
COUNT(*) as review_count,
COUNT(*) FILTER (WHERE r.state = 'APPROVED') as approvals,
COUNT(*) FILTER (WHERE r.state = 'CHANGES_REQUESTED') as changes_requested
FROM read_parquet('hf://datasets/open-index/open-github-meta/data/reviews/**/0.parquet') r
GROUP BY r.pr_number
ORDER BY review_count DESC
LIMIT 20;
```
```sql
-- Label activity over time (monthly)
SELECT
date_trunc('month', created_at) as month,
COUNT(*) as label_events
FROM read_parquet('hf://datasets/open-index/open-github-meta/data/timeline_events/**/0.parquet')
WHERE event_type = 'LabeledEvent'
GROUP BY month
ORDER BY month;
```
```sql
-- Largest PRs by lines changed
SELECT
number,
additions,
deletions,
changed_files,
additions + deletions as total_lines
FROM read_parquet('hf://datasets/open-index/open-github-meta/data/pull_requests/**/0.parquet')
ORDER BY total_lines DESC
LIMIT 20;
```
### Using Python (`uv run`)
These scripts use [PEP 723](https://peps.python.org/pep-0723/) inline metadata. Save as a `.py` file and run with `uv run script.py`. No virtualenv or `pip install` needed.
**Stream issues:**
```python
# /// script
# requires-python = ">=3.11"
# dependencies = ["datasets"]
# ///
from datasets import load_dataset
ds = load_dataset("open-index/open-github-meta", "issues", streaming=True)
for i, row in enumerate(ds["train"]):
print(f"#{row['number']}: [{row['state']}] {row['title']} (by {row['author']})")
if i >= 19:
break
```
**Load a specific repo:**
```python
# /// script
# requires-python = ">=3.11"
# dependencies = ["datasets"]
# ///
from datasets import load_dataset
ds = load_dataset(
"open-index/open-github-meta",
"pull_requests",
data_files="data/pull_requests/facebook/react/0.parquet",
)
df = ds["train"].to_pandas()
print(f"Loaded {len(df)} pull requests")
print(f"Merged: {df['merged'].sum()} ({df['merged'].mean()*100:.1f}%)")
print(f"\nTop 10 by lines changed:")
df["total_lines"] = df["additions"] + df["deletions"]
print(df.nlargest(10, "total_lines")[["number", "additions", "deletions", "total_lines"]].to_string(index=False))
```
**Download files:**
```python
# /// script
# requires-python = ">=3.11"
# dependencies = ["huggingface-hub"]
# ///
from huggingface_hub import snapshot_download
# Download only issues
snapshot_download(
"open-index/open-github-meta",
repo_type="dataset",
local_dir="./open-github-meta/",
allow_patterns="data/issues/**/*.parquet",
)
print("Downloaded issues parquet files to ./open-github-meta/")
```
For faster downloads, install `pip install huggingface_hub[hf_transfer]` and set `HF_HUB_ENABLE_HF_TRANSFER=1`.
## Dataset structure
### `issues`
Both issues and PRs live in this table (check `is_pull_request`). Join with `pull_requests` on `number` for PR-specific fields like merge status and diff stats.
| Column | Type | Description |
|---|---|---|
| `number` | int32 | Issue/PR number (primary key) |
| `node_id` | string | GitHub GraphQL node ID |
| `is_pull_request` | bool | True if this is a PR |
| `title` | string | Title |
| `body` | string | Full body text in Markdown |
| `state` | string | `open` or `closed` |
| `state_reason` | string | `completed`, `not_planned`, or `reopened` |
| `author` | string | Username of the creator |
| `created_at` | timestamp | When opened |
| `updated_at` | timestamp | Last activity |
| `closed_at` | timestamp | When closed (null if open) |
| `labels` | string (JSON) | Array of label names |
| `assignees` | string (JSON) | Array of assignee usernames |
| `milestone_title` | string | Milestone name |
| `milestone_number` | int32 | Milestone number |
| `reactions` | string (JSON) | Reaction counts (`{"+1": 5, "heart": 2}`) |
| `comment_count` | int32 | Number of comments |
| `locked` | bool | Whether the conversation is locked |
| `lock_reason` | string | Lock reason |
### `pull_requests`
PR-specific fields. Join with `issues` on `number` for title, body, labels, and other shared fields.
| Column | Type | Description |
|---|---|---|
| `number` | int32 | PR number (matches `issues.number`) |
| `merged` | bool | Whether the PR was merged |
| `merged_at` | timestamp | When merged |
| `merged_by` | string | Username who merged |
| `merge_commit_sha` | string | Merge commit SHA |
| `base_ref` | string | Target branch (e.g. `main`) |
| `head_ref` | string | Source branch |
| `head_sha` | string | Head commit SHA |
| `additions` | int32 | Lines added |
| `deletions` | int32 | Lines deleted |
| `changed_files` | int32 | Number of files changed |
| `draft` | bool | Whether the PR is a draft |
| `maintainer_can_modify` | bool | Whether maintainers can push to the head branch |
### `comments`
Conversation comments on issues and PRs. These are the threaded discussion comments, not inline code review comments (those are in `review_comments`).
| Column | Type | Description |
|---|---|---|
| `id` | int64 | Comment ID (primary key) |
| `issue_number` | int32 | Parent issue/PR number |
| `author` | string | Username |
| `body` | string | Comment body in Markdown |
| `created_at` | timestamp | When posted |
| `updated_at` | timestamp | Last edit |
| `reactions` | string (JSON) | Reaction counts |
| `author_association` | string | `OWNER`, `MEMBER`, `CONTRIBUTOR`, `NONE`, etc. |
### `review_comments`
Inline code review comments on PR diffs. Each comment is attached to a specific file and line in the diff.
| Column | Type | Description |
|---|---|---|
| `id` | int64 | Comment ID (primary key) |
| `pr_number` | int32 | Parent PR number |
| `review_id` | int64 | Parent review ID |
| `author` | string | Reviewer username |
| `body` | string | Comment body in Markdown |
| `path` | string | File path in the diff |
| `line` | int32 | Line number |
| `side` | string | `LEFT` (old code) or `RIGHT` (new code) |
| `diff_hunk` | string | Surrounding diff context |
| `created_at` | timestamp | When posted |
| `updated_at` | timestamp | Last edit |
| `in_reply_to_id` | int64 | Parent comment ID (for threaded replies) |
### `reviews`
PR review decisions. One row per review action on a PR.
| Column | Type | Description |
|---|---|---|
| `id` | int64 | Review ID (primary key) |
| `pr_number` | int32 | Parent PR number |
| `author` | string | Reviewer username |
| `state` | string | `APPROVED`, `CHANGES_REQUESTED`, `COMMENTED`, `DISMISSED` |
| `body` | string | Review summary in Markdown |
| `submitted_at` | timestamp | When submitted |
| `commit_id` | string | Commit SHA that was reviewed |
### `timeline_events`
The full lifecycle of every issue and PR. Every label change, assignment, cross-reference, merge, force-push, lock, and other state transition.
| Column | Type | Description |
|---|---|---|
| `id` | string | Event ID (node_id or synthesized) |
| `issue_number` | int32 | Parent issue/PR number |
| `event_type` | string | Event type (see below) |
| `actor` | string | Username who triggered the event |
| `created_at` | timestamp | When it happened |
| `database_id` | int64 | GitHub database ID for the event |
| `label_name` | string | Label name (`labeled`, `unlabeled`) |
| `label_color` | string | Label hex color |
| `state_reason` | string | Close reason: `COMPLETED`, `NOT_PLANNED` (`closed`) |
| `assignee_login` | string | Username assigned/unassigned (`assigned`, `unassigned`) |
| `milestone_title` | string | Milestone name (`milestoned`, `demilestoned`) |
| `title_from` | string | Previous title before rename (`renamed`) |
| `title_to` | string | New title after rename (`renamed`) |
| `ref_type` | string | Referenced item type: `Issue` or `PullRequest` (`cross-referenced`, `referenced`) |
| `ref_number` | int32 | Referenced issue/PR number |
| `ref_url` | string | URL of the referenced item |
| `will_close` | bool | Whether the reference will close this issue |
| `lock_reason` | string | Lock reason (`locked`) |
| `data` | string (JSON) | Remaining event-specific payload (common fields stripped) |
Event types: `labeled`, `unlabeled`, `closed`, `reopened`, `assigned`, `unassigned`, `milestoned`, `demilestoned`, `renamed`, `cross-referenced`, `referenced`, `locked`, `unlocked`, `pinned`, `merged`, `review_requested`, `head_ref_force_pushed`, `head_ref_deleted`, `ready_for_review`, `convert_to_draft`, and more.
Common fields (`actor`, `created_at`, `database_id` and extracted columns above) are stored in dedicated columns and removed from `data` to reduce storage. The `data` field contains only remaining event-specific payload. See the [GitHub GraphQL timeline items documentation](https://docs.github.com/en/graphql/reference/unions#issuetimelineitems) for the full type catalog.
### `pr_files`
Every file touched by each pull request, with per-file diff statistics.
| Column | Type | Description |
|---|---|---|
| `pr_number` | int32 | Parent PR number |
| `path` | string | File path |
| `additions` | int32 | Lines added |
| `deletions` | int32 | Lines deleted |
| `status` | string | `added`, `removed`, `modified`, `renamed` |
| `previous_filename` | string | Original path (for renames) |
### `commit_statuses`
CI/CD status checks and GitHub Actions results for each commit.
| Column | Type | Description |
|---|---|---|
| `sha` | string | Commit SHA |
| `context` | string | Check name (e.g. `ci/circleci`, `check:build`) |
| `state` | string | `success`, `failure`, `pending`, `error` |
| `description` | string | Status description |
| `target_url` | string | Link to CI details |
| `created_at` | timestamp | When reported |
## Dataset statistics
| Table | Rows | Description |
|-------|-----:|-------------|
| `issues` | 612.5K | Issues and pull requests (shared metadata) |
| `pull_requests` | 311.8K | PR-specific fields (merge status, diffs, refs) |
| `comments` | 3.4M | Conversation comments on issues and PRs |
| `review_comments` | 662.5K | Inline code review comments on PR diffs |
| `reviews` | 532.5K | PR review decisions |
| `timeline_events` | 634.2K | Activity timeline (labels, closes, merges, assignments) |
| `pr_files` | 4.1M | Files changed in each pull request |
| `commit_statuses` | 164.0K | CI/CD status checks per commit |
| **Total** | **10.4M** | |
## How it's built
The sync pipeline uses both GitHub APIs. The [REST API](https://docs.github.com/en/rest) handles bulk listing: issues, comments, and review comments are fetched repo-wide with `since`-based incremental pagination and parallel page fetching across multiple tokens. The [GraphQL API](https://docs.github.com/en/graphql) handles per-item detail: one query grabs reviews, timeline events, file changes, and commit statuses in a single round trip, with automatic REST fallback for PRs with more than 100 files or reviews.
Multiple GitHub Personal Access Tokens rotate round-robin to spread rate limit load. The pipeline is fully incremental and idempotent: re-running picks up only what changed since the last sync.
Everything lands in per-repo [DuckDB](https://duckdb.org/) files first, then gets exported to Parquet with Zstd compression for publishing here. No filtering, deduplication, or content changes. Bot activity, automated PRs, CI noise, Dependabot upgrades, all of it is preserved, because that's how repos actually work.
## Known limitations
- **Point-in-time snapshot.** Data reflects the state at the last sync, not real-time. Incremental updates capture everything that changed since the previous sync.
- **Bot activity included.** Comments and PRs from bots (Dependabot, Renovate, GitHub Actions, etc.) are included without filtering. This is intentional. Filter on `author` if you want humans only.
- **JSON columns.** `labels`, `assignees`, `reactions`, and `data` contain JSON strings. Use `json_extract()` in DuckDB or `json.loads()` in Python.
- **Body text can be large.** Issue and comment bodies contain full Markdown, sometimes with embedded images. Project only the columns you need for memory-constrained workloads.
- **Timeline data varies by event type.** The `data` field in `timeline_events` contains the raw event payload as JSON. The schema depends on `event_type`.
## Personal and sensitive information
Usernames, user IDs, and author associations are included as they appear in the GitHub API. All data was already publicly accessible on GitHub. Email addresses do not appear in this dataset (they exist only in git commit objects, which are in the separate code archive, not here). No private repository data is present.
## License
Released under the [Open Data Commons Attribution License (ODC-By) v1.0](https://opendatacommons.org/licenses/by/1-0/). The underlying data is sourced from GitHub's public API. [GitHub's Terms of Service](https://docs.github.com/en/site-policy/github-terms/github-terms-of-service) apply to the original data.
## Thanks
All the data here comes from [GitHub](https://github.com/)'s public [REST API](https://docs.github.com/en/rest) and [GraphQL API](https://docs.github.com/en/graphql). We are grateful to the open-source maintainers and contributors whose work is represented in these tables.
- **[OpenGitHub](https://huggingface.co/datasets/open-index/open-github)**, our companion dataset covering the full GitHub event stream via [GH Archive](https://www.gharchive.org/) by [Ilya Grigorik](https://www.igvita.com/)
- Built with [DuckDB](https://duckdb.org/) (Go driver), [Apache Parquet](https://parquet.apache.org/) (Zstd compression), published via [Hugging Face Hub](https://huggingface.co/)
Questions, feedback, or issues? Open a discussion on the [Community tab](https://huggingface.co/datasets/open-index/open-github-meta/discussions).
提供机构:
open-index
搜集汇总
数据集介绍
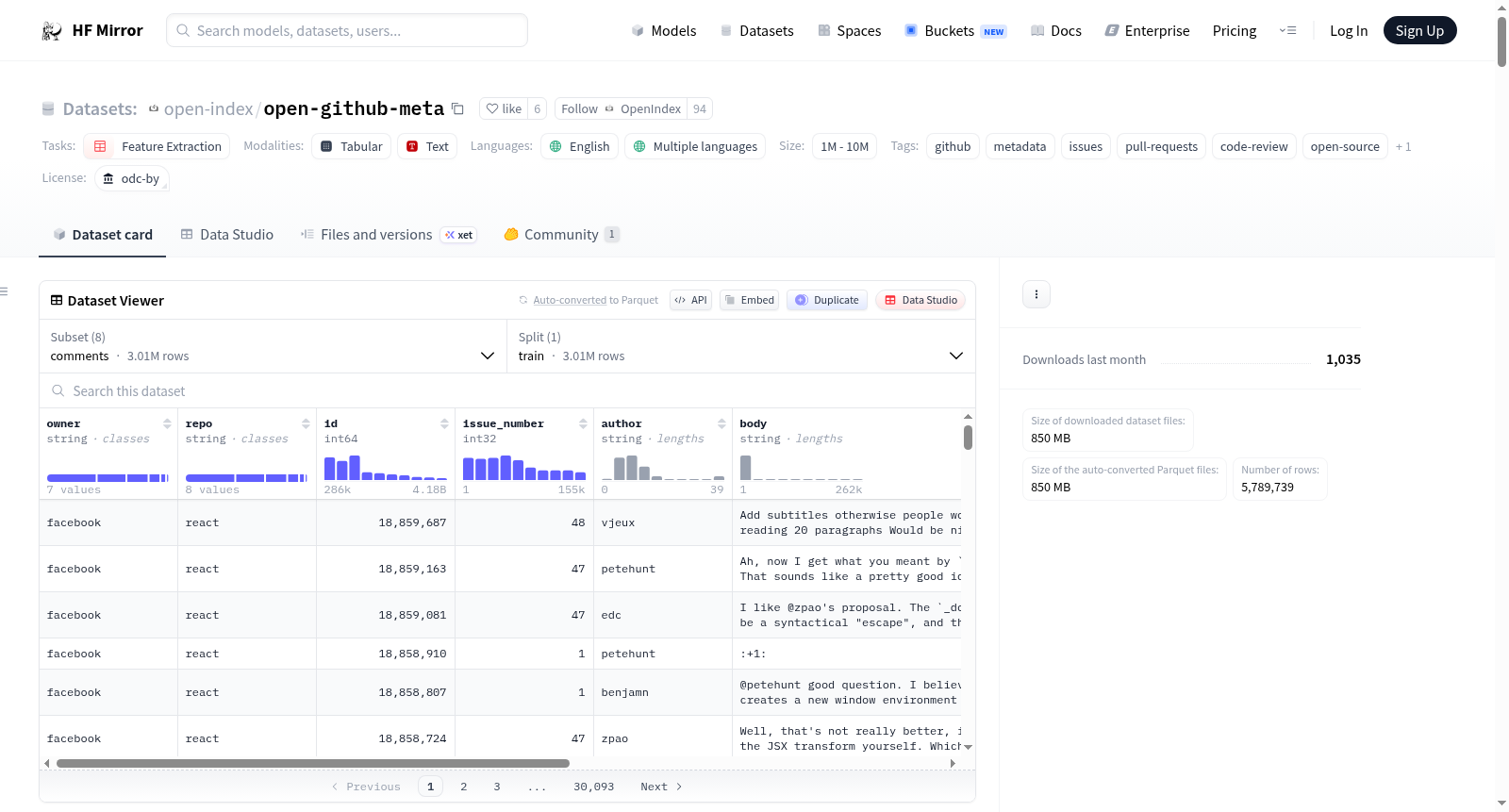
构建方式
在开源软件开发领域,全面获取项目协作过程的元数据对于理解软件开发实践至关重要。OpenGitHub Meta数据集通过精心设计的同步管道构建而成,该管道巧妙结合了GitHub REST API与GraphQL API的双重优势。REST API负责批量获取议题、评论等基础数据,采用基于时间戳的增量分页机制,并利用多令牌轮询策略分散请求负载;而GraphQL API则用于高效提取每个项目的详细元数据,如代码审查、时间线事件等,通过单次查询即可获取关联数据。所有采集的数据首先存储于按仓库组织的DuckDB文件中,随后转换为经过Zstd压缩的Parquet格式,确保数据完整性的同时优化存储效率。整个流程具备完全增量和幂等特性,能够持续捕捉项目状态的动态演变。
使用方法
该数据集采用标准的Hugging Face Parquet布局设计,确保了与多种数据分析工具的即插即用兼容性。研究人员可根据具体分析需求灵活选择数据加载范围,既可以加载单个数据表进行横向比较研究,也可以聚焦于特定仓库进行纵向深度分析。利用DuckDB可直接从远程读取Parquet文件执行复杂SQL查询,无需预先下载完整数据集,这为探索性数据分析提供了极大便利。Python用户可通过`datasets`库以流式或批量方式加载数据,或使用`huggingface_hub`工具选择性下载特定文件。数据集中的JSON字段(如标签、反应数据)可通过相应的解析函数进行结构化处理,而丰富的连接键(如`issue_number`、`pr_number`)使得跨表关联分析变得直观高效,支持从代码审查效率到项目健康度评估等多种研究场景。
背景与挑战
背景概述
OpenGitHub Meta数据集由Open-Index团队于2026年构建,旨在为软件工程研究提供一套全面且结构化的开源项目开发元数据。该数据集聚焦于GitHub平台上九个知名开源仓库的完整开发历程,涵盖议题、拉取请求、代码审查、时间线事件等核心要素,通过整合GitHub REST与GraphQL API,以Parquet格式高效存储了约990万行数据。其核心研究问题在于深入解析大规模协作开发中的流程模式、代码审查效率与项目健康度,为软件工程领域的实证研究提供了前所未有的细粒度数据支持,显著推动了开源生态系统的量化分析与过程挖掘。
当前挑战
该数据集致力于解决软件工程研究中开发过程量化分析的挑战,其核心在于如何从海量异构的协作数据中提取有意义的模式,例如代码审查动态、议题分类与项目演进轨迹。在构建过程中,团队面临多重技术挑战:需协调GitHub API的速率限制与数据增量同步,确保数百万条记录的高效获取与一致性;同时,处理时间线事件等复杂嵌套结构,并将其规范化为可查询的表格格式,亦对数据管道设计提出了严峻考验。此外,原始数据中混杂的机器人活动与大规模Markdown文本,进一步增加了数据清洗与存储优化的复杂性。
常用场景
经典使用场景
在软件工程研究领域,OpenGitHub Meta数据集为代码审查过程提供了深度分析的基础。该数据集整合了GitHub上九个知名开源项目的完整开发元数据,包括问题、拉取请求、评论、代码审查意见以及时间线事件等结构化信息。研究人员能够利用这些数据构建代码审查模型,分析审查意见与代码修改之间的关联,从而揭示高效审查模式的形成机制。通过追踪拉取请求从创建到合并的全过程,该数据集支持对审查效率、合并率以及贡献者协作动态的量化评估,为开源社区的健康度测量提供了实证依据。
解决学术问题
该数据集有效解决了软件工程领域多个关键研究问题,尤其是在开源协作过程的可视化与量化方面。它使得学者能够系统探究代码审查质量的影响因素,例如审查意见的及时性、详细程度与最终代码质量的关系。同时,数据集支持对问题分类与分诊机制的自动化研究,通过分析标签使用模式、讨论线程和时间线事件,可以构建智能分类模型以辅助社区维护。此外,其完整的时间序列数据为软件过程挖掘提供了丰富素材,能够揭示项目开发流程中的瓶颈与优化机会,推动基于数据的软件工程方法论发展。
实际应用
在实际应用层面,OpenGitHub Meta数据集为开源项目维护者和企业研发团队提供了宝贵的洞察工具。团队可以基于历史数据计算关键绩效指标,如平均合并时间、审查周转周期以及贡献者活跃度,从而优化内部工作流程。该数据集还能训练自动化工具,用于智能问题路由、重复问题检测以及审查工作量预测,减轻维护负担。对于平台开发者而言,这些元数据有助于设计更有效的协作界面与通知机制,提升开发者体验。教育机构亦可利用其进行案例教学,展示真实世界中的软件协作模式。
数据集最近研究
最新研究方向
在开源软件工程领域,OpenGitHub Meta数据集正推动着代码审查智能化的前沿探索。该数据集整合了九个知名开源项目的完整开发元数据,为研究大规模协作中的代码质量保障机制提供了前所未有的细粒度视角。当前研究热点聚焦于利用机器学习模型分析代码审查对话的语义模式,通过自然语言处理技术自动识别审查意见中的关键缺陷类别,并预测代码合并的成功概率。这些探索与业界对提升开源项目可持续性的迫切需求紧密相连,特别是在应对日益复杂的依赖管理和安全漏洞修复场景中,智能审查辅助系统展现出显著的应用潜力。相关研究不仅深化了我们对分布式协作动力学的理解,更为构建下一代自动化软件工程工具奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


