CS-Eval 大模型网络安全评测数据集
收藏超神经2025-01-21 更新2024-06-29 收录
下载链接:
https://hyper.ai/cn/datasets/32631
下载链接
链接失效反馈官方服务:
资源简介:
CS-Eval 是由阿里安全、复旦大学和中国科学院大学联合建立的大模型网络安全能力评测集。数据集覆盖 11 个网络安全大类领域、 42 个子类领域,4,369 多项选择题、判断题、知识抽取题,提供知识型和实战型的综合评估任务,支持用户自主评测,同时为大模型落地网络安全提供参考和启发。
CS-Eval is a cybersecurity capability evaluation dataset for large language models jointly established by Alibaba Security, Fudan University, and the University of Chinese Academy of Sciences. The dataset covers 11 high-level cybersecurity domains and 42 sub-domains, including 4,369 multiple-choice questions, true-false questions, and knowledge extraction questions. It provides comprehensive assessment tasks covering both knowledge-based and practical scenarios, supports users to conduct self-evaluation, and offers references and inspirations for the deployment of large language models in the field of cybersecurity.
创建时间:
2024-06-26
搜集汇总
数据集介绍
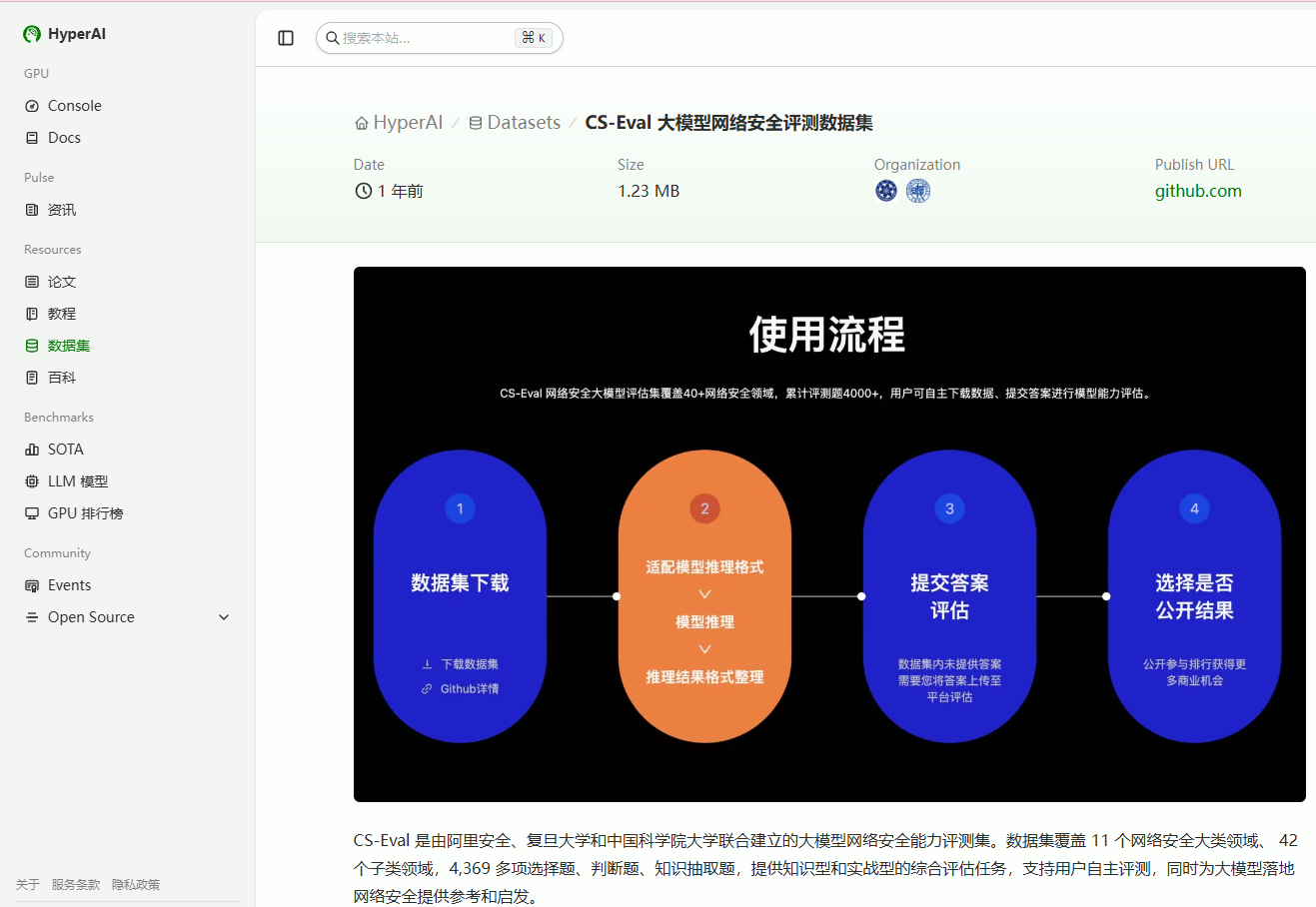
构建方式
数据集由网络安全专家联合构建,围绕网络安全知识体系与真实攻防场景设计题目,涵盖基础概念理解、威胁识别、攻击手法分析、防御策略判断及知识抽取等任务类型,并通过人工审核与一致性校验保证数据质量。
特点
覆盖网络安全主要知识体系与典型应用场景,兼顾理论知识与实践能力;题型多样,既可用于自动化评分,也适用于人工分析模型失误类型与能力短板。
使用方法
可用于对不同大模型进行离线对比评测,分析其在网络安全各子领域的能力分布,也可用于模型微调、能力诊断与安全能力专项优化。
背景与挑战
背景概述
CS-Eval是一个由阿里安全、复旦大学和中国科学院大学联合构建的大模型网络安全评测数据集,旨在评估大模型在网络安全领域的能力。它覆盖11个网络安全大类、42个子类,包含4,369道多项选择题、判断题和知识抽取题,提供知识型和实战型综合评估任务,支持用户自主评测,并为大模型在网络安全应用提供参考和启发。
常用场景
经典使用场景
用于评估大模型在漏洞识别、威胁分析、安全策略理解等方面的能力差异。
实际应用
辅助企业和机构在引入大模型前进行安全能力评估,降低模型在安全相关业务中的潜在风险。
衍生相关工作
可用于构建漏洞分析、攻击识别、安全问答等子任务数据集,或作为网络安全智能体的评测与训练参考。
以上内容由遇见数据集搜集并总结生成


