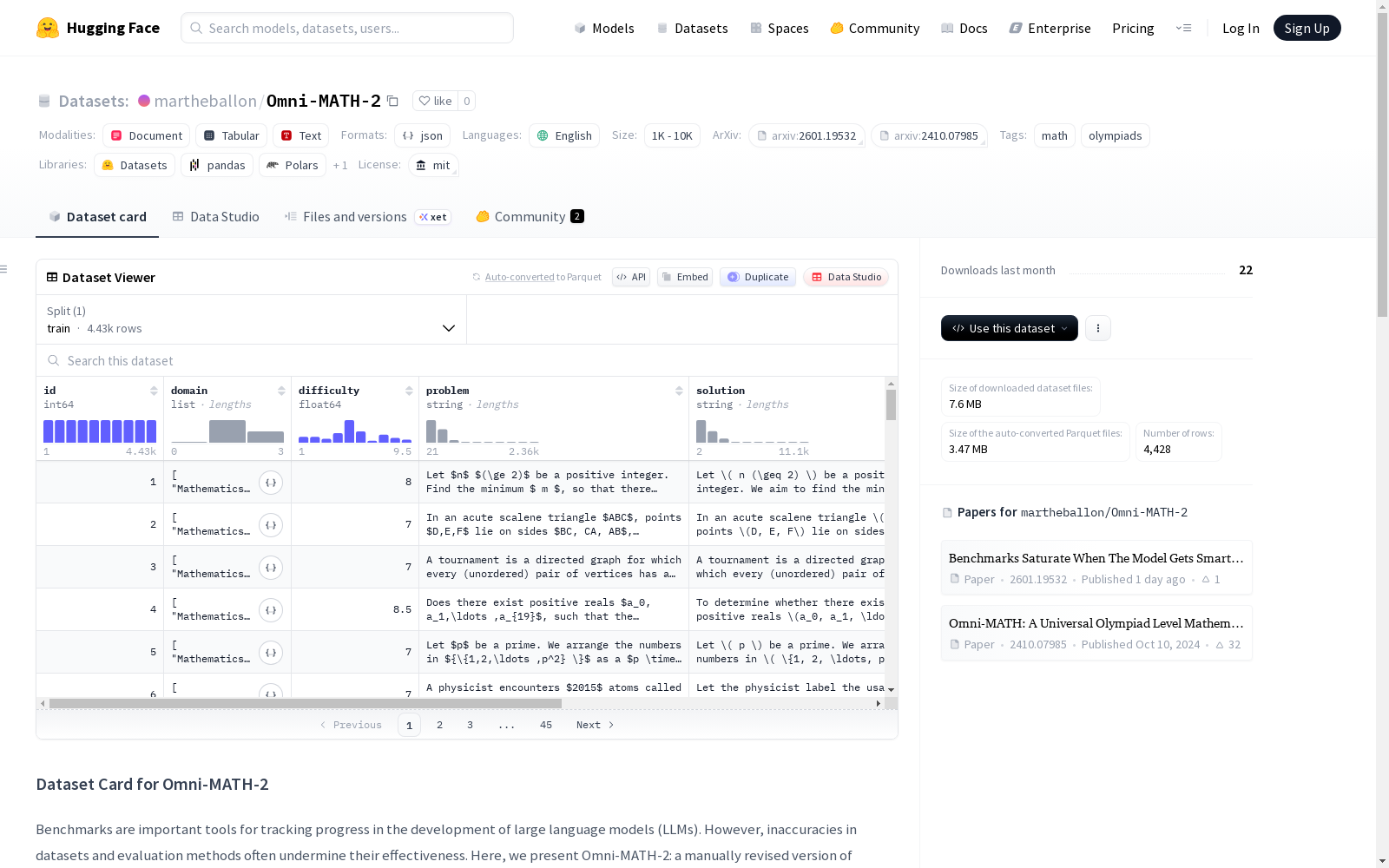
Omni-MATH-2
收藏Omni-MATH-2 数据集概述
基本信息
- 数据集名称:Omni-MATH-2
- 许可证:MIT
- 主要语言:英语
- 标签:数学、奥林匹克竞赛
- 数据规模:1K < n < 10K(具体为 4,428 个问题)
数据集描述
Omni-MATH-2 是原始 Omni-MATH 数据集的手动修订版本。该修订旨在提升数据集在评估大型语言模型时的有效性,同时保持了原始数据集的规模(n = 4,428)。修订工作显著改善了问题的 LaTeX 可编译性、可解性和可验证性。
修订详情
- 编辑问题数量:647 个(占总数的 14.6%)
- 标记为非标准问题数量:247 个(占总数的 5.6%)
- 非标准问题定义:包含图像、要求估算或证明、或是退化问题(例如重复、无参考答案、空问题等)。
数据子集
提供了一个评估就绪的子集:
- Omni-MATH-2-Filtered:包含 4,181 个问题。该子集已排除标记为非标准的问题,以确保其适用于判断精确答案。
使用方式
可通过 datasets 库加载数据集:
python
from datasets import load_dataset
dataset = load_dataset("martheballon/Omni-MATH-2")
相关资源
- 论文:https://arxiv.org/abs/2601.19532
- GitHub 仓库:https://github.com/MartheBallon/Benchmarks-saturate-when-the-model-gets-smarter-than-the-judge
- 清理过程示意图:https://huggingface.co/datasets/martheballon/Omni-MATH-2/resolve/main/Cleaning.png
引用信息
如果使用本数据集,请引用相关论文:
@misc{ballon2026benchmarkssaturatewhen, title={Benchmarks Saturate When The Model Becomes Smarter Than The Judge}, author={Ballon, Marthe and Algaba, Andres and Verbeken, Brecht and Ginis, Vincent}, year={2026}, eprint={2601.19532}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2601.19532}, }
致谢
感谢原始 Omni-MATH 数据集的作者和贡献者。他们发布的基准和验证器 Omni-Judge 为本论文的分析提供了支持。
@misc{gao2024omnimathuniversalolympiadlevel, title={Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models}, author={Bofei Gao and Feifan Song and Zhe Yang and Zefan Cai and Yibo Miao and Qingxiu Dong and Lei Li and Chenghao Ma and Liang Chen and Runxin Xu and Zhengyang Tang and Benyou Wang and Daoguang Zan and Shanghaoran Quan and Ge Zhang and Lei Sha and Yichang Zhang and Xuancheng Ren and Tianyu Liu and Baobao Chang}, year={2024}, eprint={2410.07985}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2410.07985}, }