VideoVista-2
收藏VideoVista-2 数据集概述
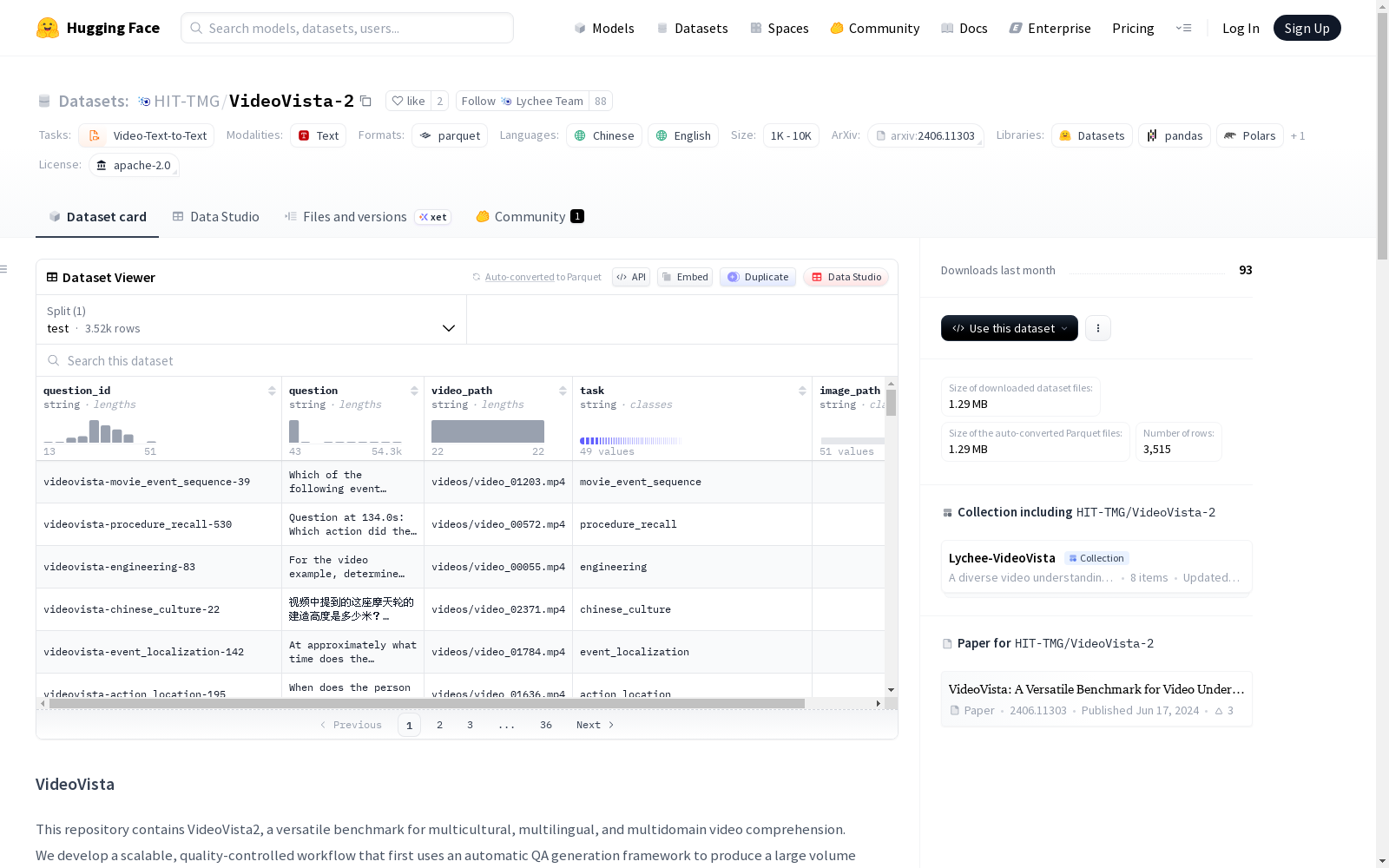
数据集基本信息
- 数据集名称: VideoVista-2
- 托管平台: Hugging Face
- 页面地址: https://huggingface.co/datasets/HIT-TMG/VideoVista-2
- 支持语言: 中文 (zh)、英文 (en)
- 许可证: Apache License 2.0
- 数据规模: 1K<n<10K
- 任务类别: 视频文本到文本 (video-text-to-text)
数据集简介
VideoVista-2 是一个用于多文化、多语言、多领域视频理解的通用基准测试集。该数据集通过一个可扩展、质量可控的工作流程构建,该流程首先使用自动问答生成框架,从经过筛选的、领域多样化的视频中产生大量候选问答对。
当前发布状态
- 发布日期: 2026年1月18日
- 发布状态: 作为 VideoVista Competition 的 Benchmark B 发布。
- 数据内容: 目前仅提供原始视频文件和问题。
- 答案发布计划: 答案将于 2026年2月8日 发布。
文件与数据
- 问题文件:
test-00000-of-00001.parquetVideoVista2_no_answer.json
- 媒体文件:
videos.zip(需合并解压)images.zip
- 解压说明:
- 使用命令
zip -s 0 videos.zip --out videos_full.zip合并视频分卷。 - 使用命令
unzip videos_full.zip解压完整视频文件。 - 使用命令
unzip images.zip解压图像文件。
- 使用命令
评估方法
- 评估指标: 准确率 (Accuracy)
实验结果
- 实验结果图表:

引用信息
如果 VideoVista 对您的研究和应用有帮助,请使用以下 BibTeX 引用:
bibtex @inproceedings{chen2025videovista, title={VideoVista-CulturalLingo: 360^{circ} Horizons-Bridging Cultures, Languages, and Domains in Video Comprehension}, author={Chen, Xinyu and Li, Yunxin and Shi, Haoyuan and Hu, Baotian and Luo, Wenhan and Wang, Yaowei and Zhang, Min}, booktitle={Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, year={2025}, publisher={Association for Computational Linguistics}, address={Vienna, Austria}, pages={27102--27128} }
@article{li2024videovista, title={Videovista: A versatile benchmark for video understanding and reasoning}, author={Li, Yunxin and Chen, Xinyu and Hu, Baotian and Wang, Longyue and Shi, Haoyuan and Zhang, Min}, journal={arXiv preprint arXiv:2406.11303}, year={2024} }