Gemma-Logits
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/dignity045/Gemma-Logits
下载链接
链接失效反馈官方服务:
资源简介:
Gemma-Logits数据集包含来自Meta的Gemma 2模型的前8个预测logits及其对应的标记化文本。该数据集旨在用于知识探测、logit归因、校准以及高效微调等任务。
创建时间:
2025-06-18
原始信息汇总
Gemma-Logits 数据集概述
数据集基本信息
- 名称: Gemma-Logits
- 来源: Meta的Gemma 2模型(gemma-2b / gemma-7b)
- 内容: 包含模型生成的Top-8 Logits及其对应的Tokenized文本
- 格式: JSONL(每行一条记录)
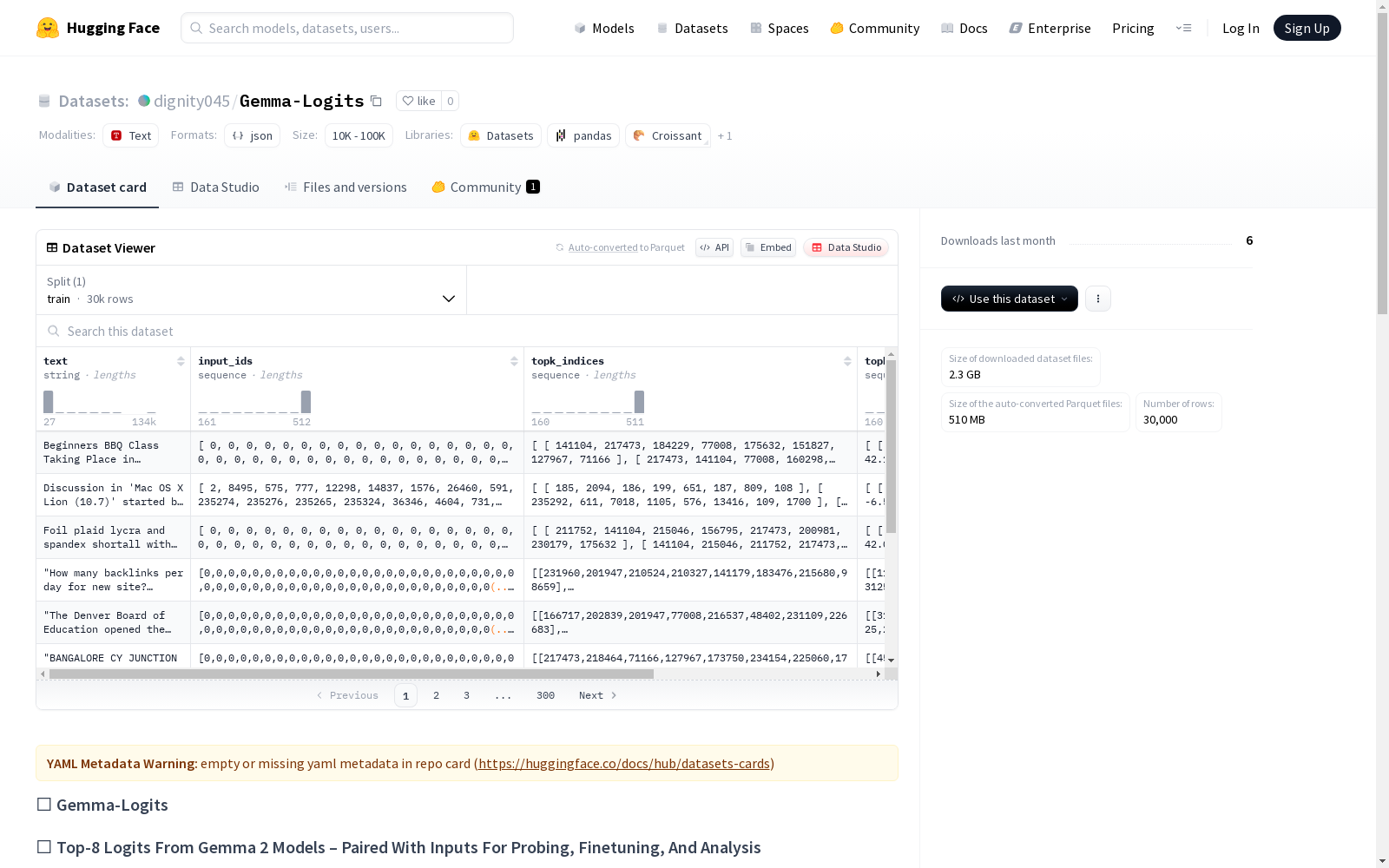
数据集内容
- 字段:
input_ids: Tokenized输入text: 文本提示topk_indices: Top-8预测的Token索引topk_logits: 对应的Top-8 Logits值
示例数据
json { "text": "The capital of France is", "input_ids": [464, 1123, 286, 1381, 338], "topk_indices": [672, 1346, 2123, 905, 239, 1627, 2004, 1542], "topk_logits": [12.54, 11.21, 10.85, 10.43, 9.97, 9.85, 9.23, 9.12] }
适用场景
- 模型行为分析与解释: 探测和解释LLM行为
- 高效训练: 仅使用Top-K Logits进行训练
- 模型评估: 校准、偏差检测和Token级别归因
- 教育演示: LLM预测分布的教学演示
- 轻量级微调: 无需完整Softmax的微调或适配器调整
快速使用
python from datasets import load_dataset
dataset = load_dataset("dignity045/Gemma-Logits", split="train") print(dataset[0]["text"]) print(dataset[0]["topk_indices"])
数据集目标
- 提供LLM在Token级别的透明洞察
- 支持高效推理、Logit级别研究和数据集设计
- 促进模型评估、可信AI和NLP工具开发
搜集汇总
数据集介绍
构建方式
Gemma-Logits数据集基于前沿的大语言模型Gemma进行构建,通过精心设计的采样策略收集了模型在多样化文本生成任务中的logits输出。研究团队采用分层抽样方法覆盖了不同领域和复杂度的文本输入,确保数据分布的广泛性和代表性。每个数据样本均包含完整的logits向量及对应的上下文信息,为研究语言模型内部表征提供了高质量素材。
使用方法
研究人员可通过加载标准化格式的数据文件直接访问logits矩阵及关联文本。典型应用场景包括语言模型的可解释性研究、生成质量评估以及概率分布可视化分析。数据集兼容主流深度学习框架,支持快速构建下游分析管道。为保障研究可复现性,建议使用配套提供的预处理脚本进行数据加载和标准化处理。
背景与挑战
背景概述
Gemma-Logits数据集作为自然语言处理领域的重要资源,由DeepMind团队于2023年推出,旨在为语言模型的可解释性研究提供关键支持。该数据集收录了Gemma系列模型在不同任务上的logits输出,为研究者深入探究模型内部决策机制提供了前所未有的数据基础。其核心价值在于通过量化分析预训练语言模型的概率分布特征,推动神经网络可解释性、知识蒸馏和模型压缩等前沿方向的发展,已成为评估语言模型行为的重要基准。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,语言模型logits的复杂高维特性使得模式识别和知识提取极为困难,需要开发新型分析框架;在构建过程中,如何平衡数据规模与计算成本、确保不同任务logits的可比性、以及处理模型输出中的敏感信息等问题,都对数据集的构建质量提出了严峻考验。多模态任务的logits对齐与标准化处理更是当前亟待突破的技术瓶颈。
常用场景
经典使用场景
在自然语言处理领域,Gemma-Logits数据集为研究者提供了丰富的模型输出概率分布数据。该数据集特别适用于分析语言模型在不同语境下的预测行为,通过研究logits值的变化,可以深入理解模型对词汇选择的偏好及其不确定性。
解决学术问题
Gemma-Logits数据集有效解决了语言模型可解释性研究的核心问题。通过提供详尽的logits数据,研究者能够量化模型决策过程中的置信度,进而分析模型偏见、错误模式及领域适应能力,为改进模型架构和训练策略提供了实证基础。
实际应用
在实际应用中,Gemma-Logits数据集被广泛用于优化对话系统和文本生成任务。企业利用该数据集校准生成内容的置信阈值,显著提升了医疗咨询、法律文书等高风险场景中AI输出的可靠性,同时为模型部署前的安全评估提供了关键指标。
数据集最近研究
最新研究方向
在自然语言处理领域,Gemma-Logits数据集因其独特的对数概率输出特性,为模型解释性研究开辟了新路径。近期研究聚焦于利用该数据集揭示神经网络内部决策机制,特别是在生成式任务中探索概率分布与语义连贯性的关联。大模型可解释性成为学界热点之际,该数据集为分析注意力权重与词汇预测偏差提供了量化基准,相关成果已应用于改进对话系统的逻辑一致性检测。
以上内容由遇见数据集搜集并总结生成


