ReSeDis
收藏arXiv2025-06-18 更新2025-06-22 收录
下载链接:
https://github.com/hufflepuff0596/ReSeDis
下载链接
链接失效反馈官方服务:
资源简介:
ReSeDis是一个为评估模型在真实开放世界环境中进行大规模指代对象搜索能力而设计的基准数据集。不同于传统的指代任务,ReSeDis要求模型能够根据自然语言描述,在数千张图片中找到真正包含该对象的图片,并准确地在像素级别定位对象。该数据集由7088张来自MS-COCO数据集的图片和9664个手动编写的指代表达式组成,每个表达式对应多个类别中的对象实例。数据集旨在解决现有视觉定位和文本检索方法的局限性,为构建下一代鲁棒和可扩展的多模态搜索系统提供现实和端到端的测试平台。
ReSeDis is a benchmark dataset designed to evaluate models' ability to perform large-scale referring object search in real open-world environments. Unlike traditional referring tasks, ReSeDis requires models to locate the exact images containing the target object from thousands of images based on natural language descriptions, and accurately pinpoint the object at the pixel level. This dataset comprises 7088 images from the MS-COCO dataset and 9664 manually written referring expressions, where each expression corresponds to object instances across multiple categories. It aims to address the limitations of existing visual grounding and text retrieval methods, providing a realistic and end-to-end testbed for building next-generation robust and scalable multimodal search systems.
提供机构:
国立情报学研究所, 东京大学
创建时间:
2025-06-18
原始信息汇总
ReSeDis数据集概述
数据集简介
- 名称:ReSeDis (Referring-based Object Search and Discovery)
- 用途:用于评估模型在大规模图像集合中搜索被引用对象的能力
- 任务类型:引用搜索与发现任务(Refering Search and Discovery)
数据规模
- 图像数量:7,088张(来自MSCOCO数据集)
- 引用表达式:9,664条
数据内容
- 每张图像包含:
- 图像ID(与MSCOCO保持一致)
- 目标对象的分割掩码(target_annotation)
- 目标对象的文本描述(expression)
- 目标对象的类别(category)
数据格式
- 注释文件格式:JSON
- 读取方式: python import json with open(*.json, r) as f: infos = json.load(f)
下载信息
- 下载地址:https://drive.google.com/drive/folders/1H0woMUkhVA0IcA8614b1oI6gajNN2g1-?usp=sharing
使用条款
- 仅限非商业用途的学术研究和教育目的
- 严禁商业使用
- 未经作者书面许可不得重新分发数据集或修改版本
搜集汇总
数据集介绍
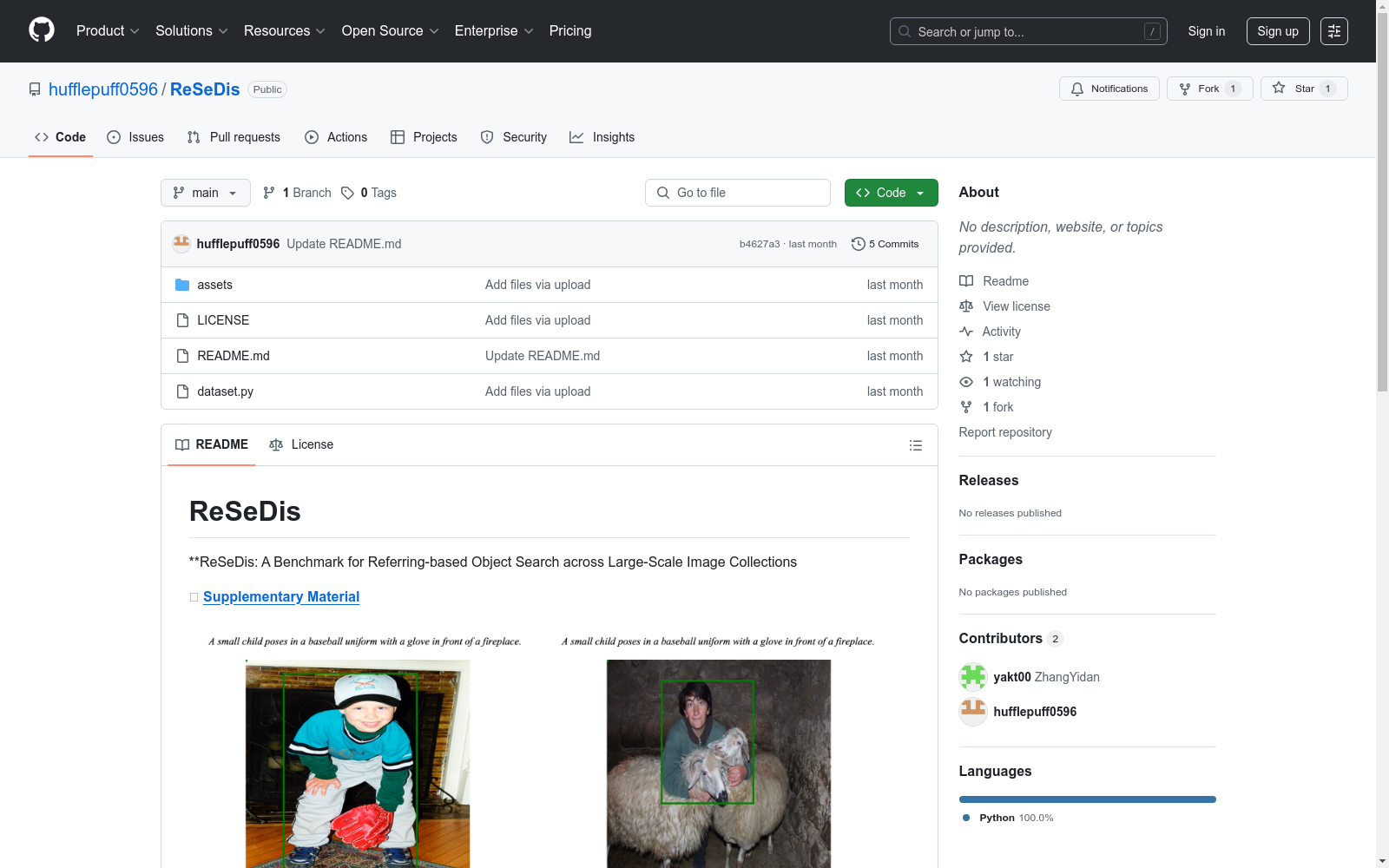
构建方式
ReSeDis数据集的构建基于MS-COCO数据集,通过多阶段筛选和标注流程确保数据质量。首先利用CLIP图像编码器和K-Means聚类算法对MS-COCO验证集中的图像进行去重和分组,筛选出约10,000张视觉独特且可通过文本区分的图像。随后采用ChatGPT生成针对图像中特定对象的细粒度描述,确保每个显著物体都配有包含属性、动作和空间关系的自然语言表达。最后通过人工校验确保文本描述与标注框、分割掩膜的精确对应,形成包含7,088张图像和9,664条指代表达的验证集。
特点
该数据集首创性地统一了跨图像检索与像素级定位的双重任务特性,其核心优势体现在三方面:语义层面,每个自然语言查询严格对应分散在大规模图像库中的特定实例,消除传统指代任务中‘查询对象必然存在’的封闭世界假设;标注层面,同时提供边界框和分割掩膜注释,支持从粗粒度到细粒度的多级定位评估;数据分布层面,继承MS-COCO的长尾类别特性,并涵盖丰富的物体属性、空间关系和交互动作描述,通过词云分析可见其语言多样性显著超越现有基准。
使用方法
使用ReSeDis需采用两阶段评估框架:首先计算目标图像的检索召回率,衡量系统在大型图像库中筛选相关图像的能力;其次通过Pr@50指标(重叠阈值50%时的定位精度)评估像素级定位准确性。研究建议采用基于CLIP和YOLOv8的基线模型,其中视觉语言模型处理跨模态相似度计算,检测模型生成候选区域,最终通过对象间关系推理提升匹配精度。该设计支持端到端训练,也可兼容现有指代分割或检索模型的迁移学习。
背景与挑战
背景概述
ReSeDis数据集由日本国立情报学研究所和东京大学的研究团队于2025年提出,旨在解决大规模图像集合中基于自然语言描述的细粒度对象搜索问题。该数据集突破了传统视觉定位任务和文本-图像检索任务的局限,首次将语料库级别的检索与像素级定位统一到一个框架中。基于MS-COCO数据集构建的ReSeDis包含7,088张图像和9,664条手工标注的指代表达式,覆盖80个对象类别,其创新性体现在每个描述唯一对应分散在大规模图像集中的对象实例。该数据集为构建下一代鲁棒、可扩展的多模态搜索系统提供了真实场景下的端到端测试平台。
当前挑战
ReSeDis面临的核心挑战体现在两个维度:在领域问题层面,需同时解决开放世界场景下的检索准确性(避免传统视觉定位的封闭世界假设)和定位精确性(克服文本-图像检索缺乏细粒度定位的缺陷);在构建过程层面,主要挑战包括:1)确保指代表达式与分散在多图像中的对象实例建立唯一映射关系,2)设计能联合评估检索召回率和定位精度的新型评价指标,3)处理MS-COCO数据集中存在的长尾类别分布问题。这些挑战使得该数据集成为测试模型在真实复杂场景下多模态理解能力的标杆。
常用场景
经典使用场景
在跨模态视觉与语言研究领域,ReSeDis数据集通过构建大规模图像集合与自然语言描述的精确关联,为指代性目标搜索任务提供了标准化测试平台。其典型应用场景体现在模型需同时完成两项核心任务:基于文本描述从海量图像库中检索包含目标物体的图像,并在正样本中实现像素级精确定位。这种端到端的评估框架有效模拟了真实世界中的视觉搜索需求,例如用户通过‘左数第三层搁板上的黄色马克杯’等复杂描述在电商图库中寻找特定商品。
实际应用
在实际应用维度,ReSeDis支撑的算法可赋能智能安防、精准农业、医疗影像分析等垂直领域。例如在机场安防场景中,系统能根据‘入口处持黑色背包的红衣男子’描述,快速定位监控视频中的目标人物并标记其位置轨迹;在农业无人机巡检中,通过识别‘灌溉管附近叶缘褐变的萎蔫植株’实现病虫害精准标注。这种融合语义搜索与空间定位的能力,显著提升了行业场景下的信息检索效率。
衍生相关工作
该数据集已催生多项创新性研究,包括基于视觉-语言预训练模型的零样本迁移方法、层级式候选区域生成策略以及跨模态关系推理架构。其中CLIP与YOLOv8结合的基线模型揭示了模态对齐与目标检测的协同优化空间,后续工作如LAVT等通过引入语言感知的视觉Transformer,在检索-定位联合任务上取得显著提升。这些衍生研究持续推动着开放世界指代理解的技术边界。
以上内容由遇见数据集搜集并总结生成


