moving_20k_sam3_v0
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/moveparallel/moving_20k_sam3_v0
下载链接
链接失效反馈官方服务:
资源简介:
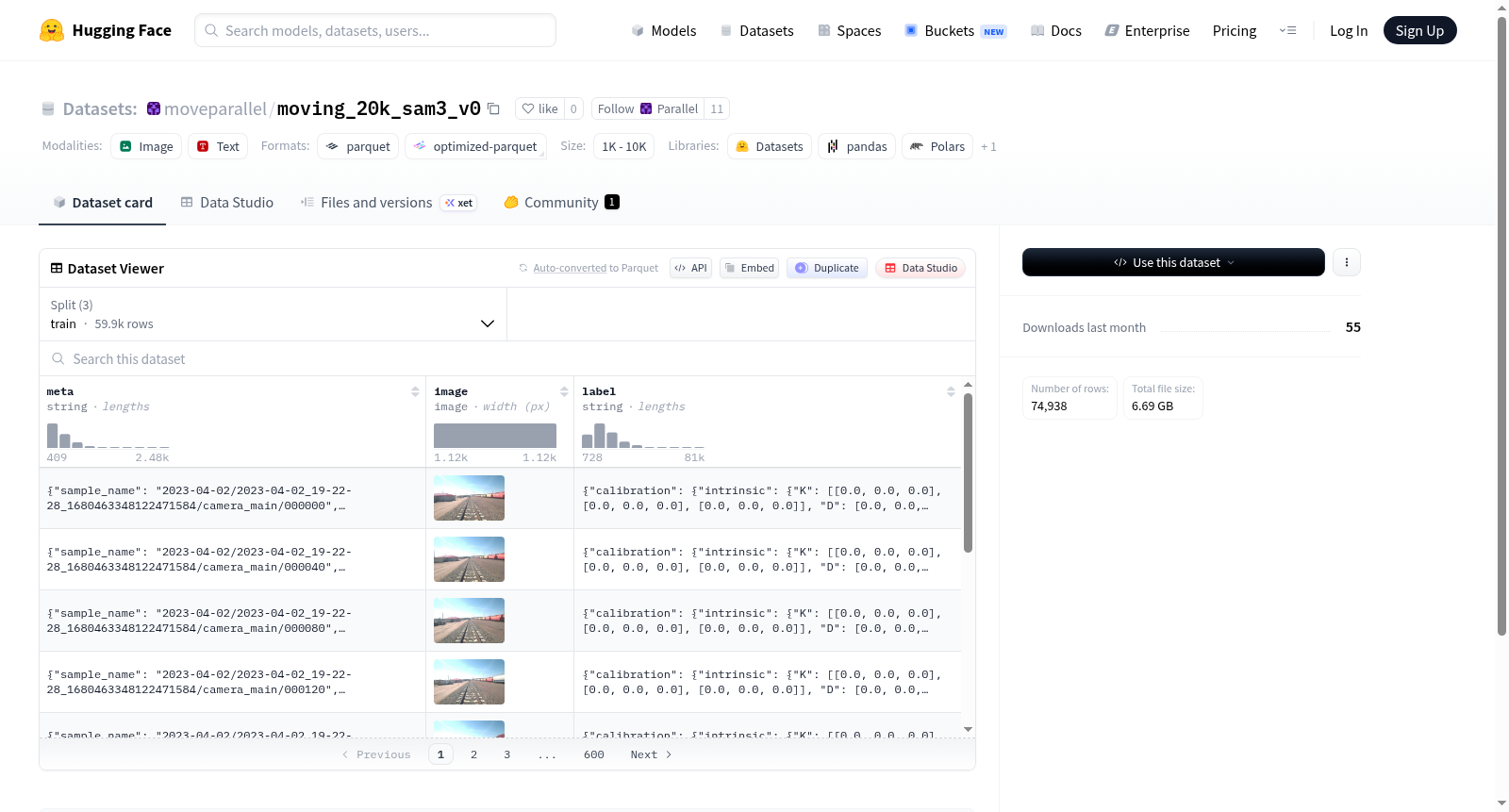
该数据集包含59,943个训练样本、7,498个验证样本和7,497个测试样本,总大小约9.14GB。每个样本包含三个字段:meta(字符串类型)、image(图像类型)和label(字符串类型)。数据已预分为标准的训练集、验证集和测试集,其中训练集约占82.4%的数据量。文件存储采用分片模式,路径格式分别为data/train-*、data/validation-*和data/test-*。该数据集适用于需要图像与文本元数据及标签关联的多模态机器学习任务。
The dataset contains 59,943 training samples, 7,498 validation samples, and 7,497 test samples, with a total size of approximately 9.14GB. Each sample includes three fields: meta (string type), image (image type), and label (string type). The data is pre-split into standard training, validation, and test sets, with the training set accounting for about 82.4% of the total data. The files are stored in a sharded format, with path patterns as data/train-*, data/validation-*, and data/test-*. This dataset is suitable for multimodal machine learning tasks that require the association of images with textual metadata and labels.
创建时间:
2026-04-22
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的概述:
数据集名称
- moving_20k_sam3_v0
数据集结构
该数据集包含以下三种特征:
- meta:字符串类型,可能存储元数据信息。
- image:图像类型,存储图片数据。
- label:字符串类型,存储标签信息。
数据划分
数据集分为三个子集:
- 训练集(train):包含 59,943 个样本,数据大小约为 7,555.78 MB。
- 验证集(validation):包含 7,498 个样本,数据大小约为 790.19 MB。
- 测试集(test):包含 7,497 个样本,数据大小约为 792.76 MB。
总体规模
- 下载大小:约 6,689.51 MB
- 数据集总大小:约 9,138.73 MB
搜集汇总
数据集介绍
构建方式
该数据集名为moving_20k_sam3_v0,其构建过程依托于大规模图像采集与标注技术。数据集中包含三个核心字段:`meta`(元数据)、`image`(图像)和`label`(标签),分别以字符串、图像和字符串类型存储。数据集划分为训练集、验证集和测试集,其中训练集包含59943个样本,验证集与测试集分别约含7498和7497个样本,总样本量近75000例。数据文件以分片形式存储于`data/`目录下,按`train-*`、`validation-*`和`test-*`模式组织,便于分布式加载与处理。整体数据集大小约9.1GB,下载大小约6.7GB,体现了其足够丰富的数据容量,适合用于图像分类或语义理解任务的模型训练与评估。
使用方法
使用该数据集时,研究者可通过HuggingFace的`datasets`库便捷加载。首先引入`load_dataset`函数,指定数据集名称`moving_20k_sam3_v0`即可自动下载并解析所有分片数据。加载后,可通过`dataset['train']`、`dataset['validation']`和`dataset['test']`分别获取训练、验证和测试子集。每个样本包含`image`字段可直接用于图像输入,`label`字段作为监督信号,`meta`字段则可用于存储额外的辅助信息或记录数据来源。在模型训练前,建议结合`torchvision`或`tensorflow`的预处理管道对图像进行统一尺寸调整和归一化处理。该数据集直接支持基于查询的样本索引和批量迭代,极大简化了从数据加载到模型输入的流程。
背景与挑战
背景概述
在计算机视觉与多媒体内容理解领域,动态场景分析一直是研究的热点与难点,其中运动目标的检测与识别对于自动驾驶、智能监控等应用至关重要。moving_20k_sam3_v0数据集由相关研究团队创建,旨在推动动态视频中运动物体理解的研究进展。该数据集包含约七万五千张标注图像,涵盖训练、验证与测试三个标准分割,为评估运动目标识别算法提供了大规模、高质量的标准化基准。其核心研究问题聚焦于如何从复杂动态背景中精准分离并识别运动物体,进而提升模型在真实世界场景中的泛化能力。自发布以来,该数据集已成为运动分析领域的重要参考资源,对促进时空特征学习、运动感知网络等研究方向的发展具有显著影响力。
当前挑战
该数据集所解决的领域问题核心在于运动目标识别与分割面临的挑战,包括动态背景中的运动模糊、光照变化、遮挡以及多尺度运动目标的精准建模。传统静态图像分析方法难以直接迁移至视频动态场景,模型需同时捕获时空连续性信息并克服非刚性形变带来的干扰。在数据集构建过程中,挑战主要体现为大规模高质量标注的获取,涉及从海量原始视频流中高效筛选包含运动目标的帧,以及确保标注一致性以避免歧义。此外,不同运动模式(如快速移动与缓慢变形)的平衡采样、以及验证与测试集分布的代表性,亦是保障数据集实用价值的关键难题。
常用场景
经典使用场景
在计算机视觉与图像理解的研究浪潮中,数据集扮演着驱动模型性能跃迁的关键角色。moving_20k_sam3_v0数据集以其精心策划的二十万级图像样本,为视觉识别任务提供了丰沛的训练土壤。其经典使用场景集中于图像分类与标签预测领域,研究者可依托该数据集的标准化划分——训练集、验证集与测试集——开展端到端的监督学习实验。借助图像与标签的配对结构,该数据集成为验证卷积神经网络与视觉Transformer架构效能的理想基准,尤其在中等规模数据场景下,为模型泛化能力与过拟合风险的权衡提供了宝贵的评估平台。
解决学术问题
在学术前沿,该数据集主要回应了图像标注不一致与数据规模受限带来的模型鲁棒性挑战。通过提供约七万五千例的验证与测试样本,研究者得以在统一指标下量化模型对视觉模式的理解深度,从而推动少样本学习与领域自适应等方向的发展。其意义在于破解了学术研究中大量依赖人工标注且难以复现的困境,为图像理解的泛化理论研究奠定了可重复实验的基础。该数据集的影响超越单一任务范畴,它促进了跨场景特征迁移机制的探索,并激励学界重新审视数据质量与模型表征能力之间的深层耦合关系。
实际应用
在工业界与日常生活的技术赋能中,该数据集的实际应用场景呈现出多元化的渗透趋势。基于其高质量的图像标注,开发者可构建面向智能安防的异常事件检测系统,或训练医疗影像中的辅助诊断模块,从而在实时性与准确性之间达成精细平衡。此外,该数据集还可服务于电商平台的产品分类引擎,通过强化视觉检索与人机交互的流畅性,提升用户决策效率。其“细粒度”与“中等规模”的特性,尤其适合部署在边缘计算设备上,助力轻量级模型在受限资源环境下的高效推理。
数据集最近研究
最新研究方向
基于大规模标注图像数据集的视觉语义理解与动态场景分析研究
以上内容由遇见数据集搜集并总结生成


