KARRIEREWEGE
收藏arXiv2024-12-19 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/ElenaSenger/Karrierewege
下载链接
链接失效反馈官方服务:
资源简介:
KARRIEREWEGE是由德国慕尼黑大学信息与语言处理中心创建的一个大规模职业路径预测数据集,包含超过50万条职业路径数据。该数据集通过与ESCO分类法关联,提供了标准化职业和技能描述,适用于多语言环境。数据集的创建过程包括从德国就业机构获取匿名简历,并手动映射到ESCO分类法,确保了数据的多样性和标准化。该数据集主要用于职业路径预测研究,旨在解决职业发展、招聘和劳动力规划中的实际问题。
KARRIEREWEGE is a large-scale career path prediction dataset developed by the Center for Information and Language Processing at LMU Munich, Germany. It contains over 500,000 career path records. Linked to the ESCO taxonomy, this dataset provides standardized descriptions of occupations and skills, and is applicable in multilingual environments. The dataset was constructed by collecting anonymous resumes from German employment agencies and manually mapping them to the ESCO taxonomy, which ensures the diversity and standardization of the data. This dataset is primarily used for career path prediction research, aiming to address practical issues in career development, recruitment and workforce planning.
提供机构:
德国慕尼黑大学信息与语言处理中心
创建时间:
2024-12-19
搜集汇总
数据集介绍
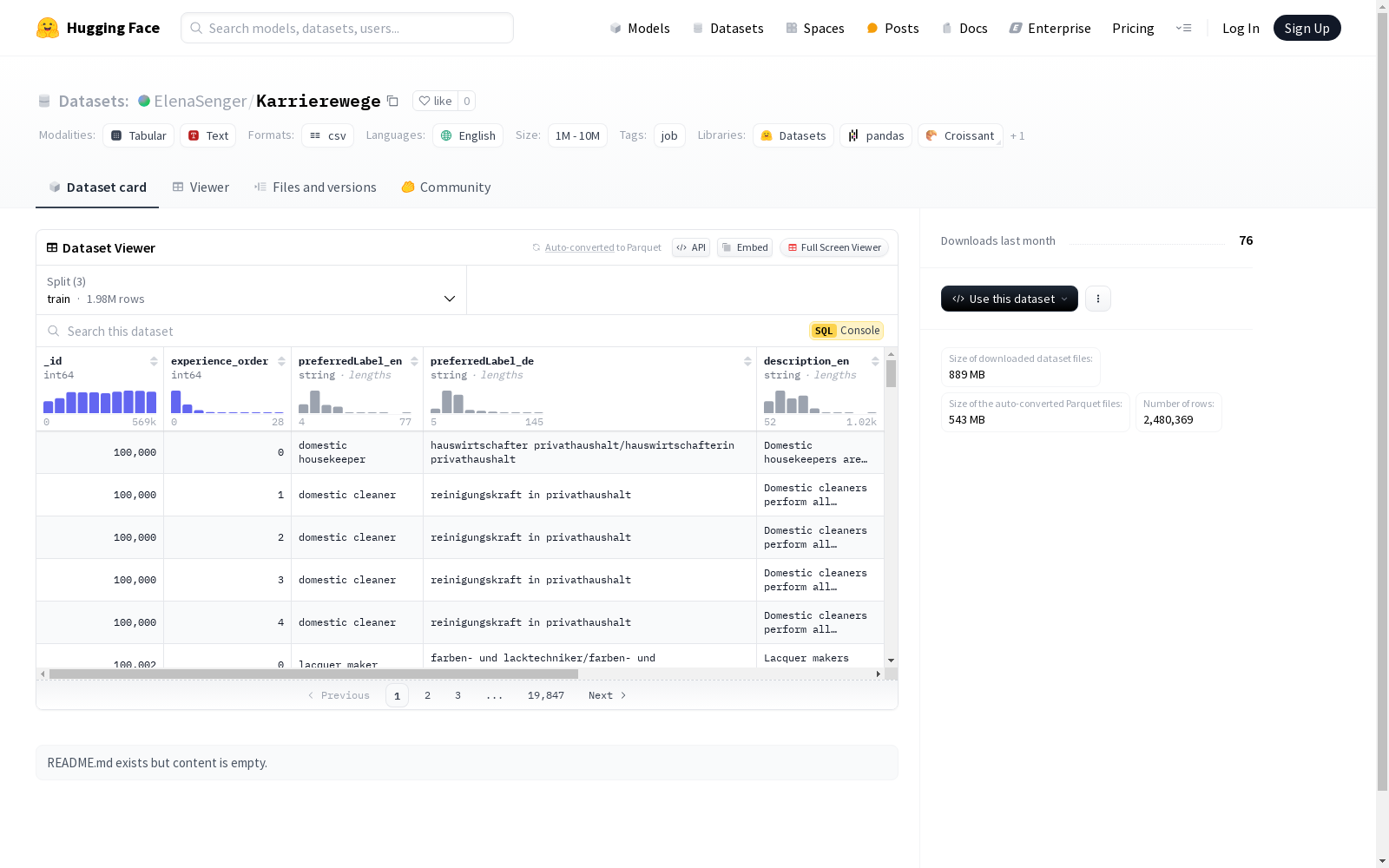
构建方式
KARRIEREWEGE数据集的构建基于德国就业机构提供的匿名简历数据,涵盖了多个行业的求职者。为了确保数据的标准化和广泛适用性,研究团队将这些职业信息手动映射到ESCO(欧洲技能、资格和职业分类)框架中,该框架提供了跨欧洲劳动力市场的标准化职业和技能描述。此外,为了应对简历中常见的自由文本输入问题,研究团队通过合成技术生成了多种职业标题和描述,形成了KARRIEREWEGE+数据集,从而增强了数据集在实际应用中的适用性。
特点
KARRIEREWEGE数据集的显著特点在于其规模庞大,包含超过50万条职业路径,远超以往的职业预测数据集。此外,数据集通过与ESCO框架的映射,提供了跨语言和跨行业的标准化职业描述,增强了数据的互操作性。KARRIEREWEGE+数据集通过合成技术生成了多样化的职业标题和描述,使其能够更好地处理自由文本输入,提升了数据集在实际应用中的鲁棒性和准确性。
使用方法
KARRIEREWEGE数据集可用于职业路径预测模型的训练和评估,特别适用于需要处理自由文本输入的场景。研究者可以通过该数据集训练模型,预测个体的未来职业发展路径。此外,数据集的ESCO映射特性使其能够应用于跨语言和跨行业的职业预测任务。KARRIEREWEGE+数据集则进一步提供了合成数据,适用于需要多样化职业描述的模型训练,帮助提升模型在复杂文本输入下的表现。
背景与挑战
背景概述
职业路径预测作为近年来快速发展的研究领域,具有广泛的应用潜力,能够为求职者、招聘人员、人力资源部门以及项目经理等提供重要支持。然而,公开可用的职业路径预测数据集和工具相对匮乏。在此背景下,Elena Senger等人于2024年推出了KARRIEREWEGE数据集,该数据集包含超过50万条职业路径,显著超越了先前可用的数据集规模。该数据集通过与ESCO分类法关联,提供了标准化资源,旨在推动职业轨迹预测研究的发展。KARRIEREWEGE+版本通过生成职位标题和描述,进一步增强了数据集的实用性,使其能够更准确地处理简历中的非结构化数据,从而更好地应对现实世界中的应用挑战。
当前挑战
KARRIEREWEGE数据集在构建过程中面临多项挑战。首先,职业路径预测领域的核心问题是如何基于个人的工作历史预测未来的职业变动,而现有的大规模职业历史数据集稀缺,这为该领域的研究带来了重大挑战。其次,构建过程中需要处理简历中的自由文本输入,这要求数据集具备处理非结构化数据的能力。此外,数据集的映射工作也面临困难,尤其是将德国的职业分类系统与ESCO分类法进行准确映射,这一过程需要高度的专业知识和人工干预。最后,数据集的多样性和代表性问题也不容忽视,如何确保数据集能够覆盖不同行业和职业,避免偏差,是该数据集面临的另一大挑战。
常用场景
经典使用场景
KARRIEREWEGE数据集的经典使用场景主要集中在职业路径预测领域。通过分析个体的职业历史,结合ESCO分类体系,该数据集能够为求职者、招聘人员、人力资源部门以及项目经理提供精准的职业轨迹预测。其核心应用在于从非结构化的简历文本中提取关键信息,生成标准化的职业路径描述,从而为职业规划和劳动力市场分析提供有力支持。
实际应用
KARRIEREWEGE数据集在实际应用中具有广泛的前景。它能够为求职者提供个性化的职业建议,帮助他们规划未来的职业路径;同时,招聘人员和人力资源部门可以利用该数据集优化招聘流程,预测候选人的职业发展潜力。此外,项目经理可以通过分析职业路径数据,更好地进行团队建设和人才管理,从而提升组织的整体效率。
衍生相关工作
KARRIEREWEGE数据集的发布催生了一系列相关研究工作。研究人员基于该数据集开发了多种职业路径预测模型,并通过与现有基准数据集的对比,验证了其在大规模数据上的优越性能。此外,该数据集还激发了对职业路径合成数据生成技术的进一步探索,推动了大规模语言模型在职业领域中的应用研究,为未来的职业路径预测和劳动力市场分析提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


