llama-3-tulu-v2-sft-subset
收藏Hugging Face2024-08-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/allenai/llama-3-tulu-v2-sft-subset
下载链接
链接失效反馈官方服务:
资源简介:
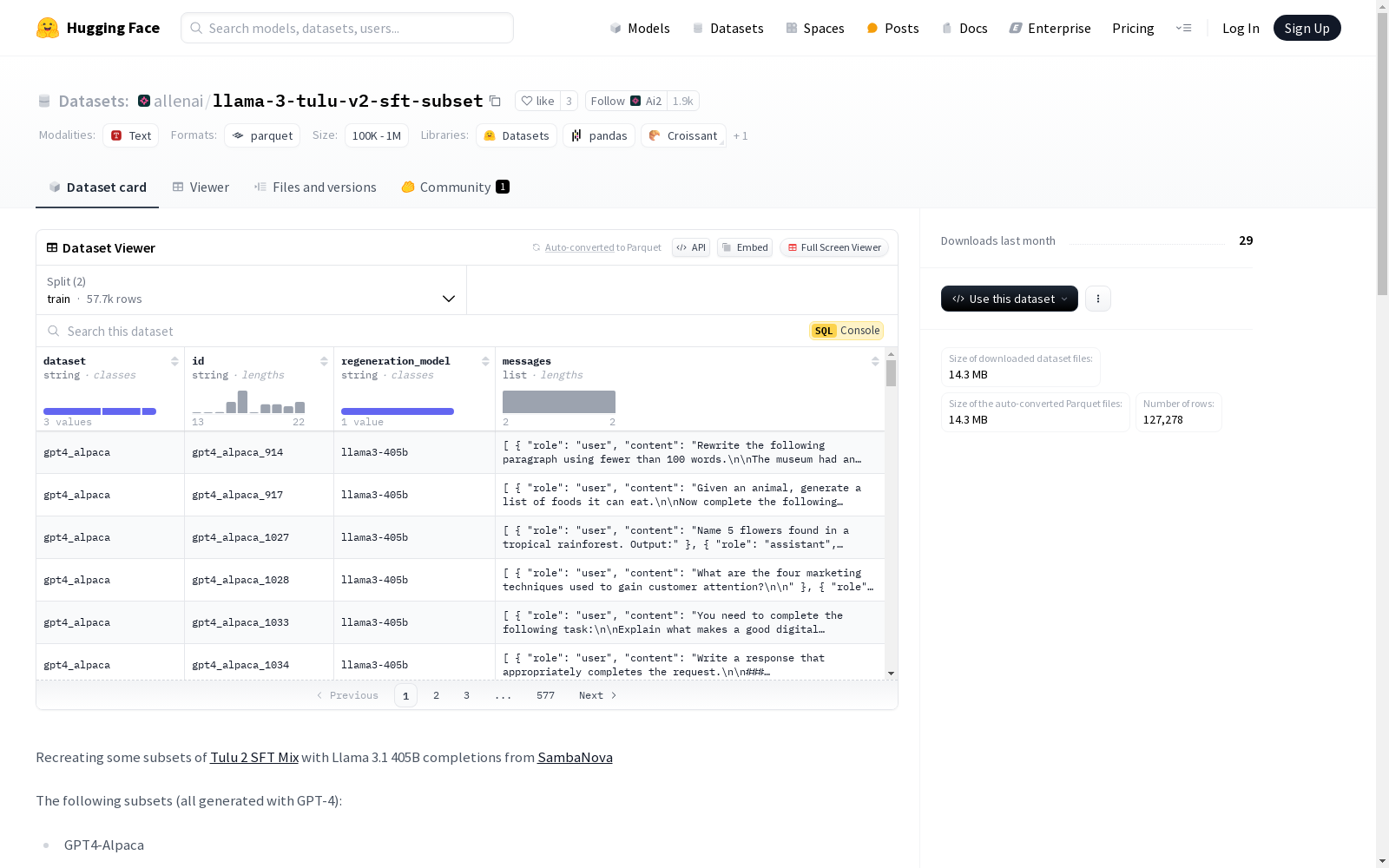
该数据集是从[Tulu 2 SFT Mix](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture)中重新创建的子集,使用Llama 3.1 405B模型生成。数据集包含多个特征,如'dataset'、'id'、'regeneration_model'和'messages',其中'messages'是一个列表,包含'role'和'content'两个子特征。数据集分为'train'和'raw'两个部分,分别包含57673和69605个样本。子集包括GPT4-Alpaca、Open Orca和Coda Alpaca。原始数据集包含所有Tulu提示,但有些由于API的max_length问题而为空,通过过滤函数去除了这些空内容。
This dataset is a recreated subset derived from the [Tulu 2 SFT Mix](https://huggingface.co/datasets/allenai/tulu-v2-sft-mixture), generated using the Llama 3.1 405B model. It includes multiple features such as "dataset", "id", "regeneration_model", and "messages". The "messages" feature is a list containing two sub-features: "role" and "content". The dataset is split into "train" and "raw" partitions, which contain 57,673 and 69,605 samples respectively. This subset encompasses GPT4-Alpaca, Open Orca, and Coda Alpaca. The original dataset contains all Tulu prompts, but some were empty due to the API's max_length limit; these empty entries were removed via a filtering function.
提供机构:
Allen Institute for AI
创建时间:
2024-08-06
原始信息汇总
数据集信息
特征
- dataset: 数据集名称,类型为字符串。
- id: 数据集中的唯一标识符,类型为字符串。
- regeneration_model: 再生模型名称,类型为字符串。
- messages: 消息列表,包含以下字段:
- role: 角色,类型为字符串。
- content: 内容,类型为字符串。
分割
- train: 训练集,包含57673个样本,大小为24540774.175950002字节。
- raw: 原始数据集,包含69605个样本,大小为29618029字节。
大小
- download_size: 下载大小为14272262字节。
- dataset_size: 数据集总大小为54158803.175950006字节。
配置
- default: 默认配置,包含以下数据文件:
- train: 路径为
data/train-*。 - raw: 路径为
data/raw-*。
- train: 路径为
搜集汇总
数据集介绍
构建方式
llama-3-tulu-v2-sft-subset数据集是基于Tulu 2 SFT Mix数据集的子集,通过Llama 3.1 405B模型进行重新生成。该数据集包含了GPT4-Alpaca、Open Orca和Coda Alpaca等子集,这些子集均由GPT-4生成。在构建过程中,原始数据集中的部分提示因API的最大长度限制而被过滤掉,确保每条数据的内容完整性。数据生成过程中,使用了SambaNova的Llama 3.1 405B模型进行对话生成,并通过特定的过滤条件筛选出有效数据。
使用方法
使用该数据集时,用户可以通过加载Hugging Face的datasets库来获取数据。数据集提供了训练集和原始数据集两个分割,用户可以根据需求选择不同的分割进行使用。数据集的每条记录包含了用户与助手的对话内容,用户可以通过解析这些对话内容来进行自然语言处理任务,如对话生成、文本分类等。此外,数据集还提供了生成脚本,用户可以根据需要自定义生成过程,进一步扩展数据集的应用场景。
背景与挑战
背景概述
llama-3-tulu-v2-sft-subset数据集是基于Tulu 2 SFT Mix数据集的一个子集,由SambaNova的Llama 3.1 405B模型生成。该数据集主要用于研究大规模语言模型在指令微调(SFT)任务中的表现。Tulu 2 SFT Mix数据集由Allen Institute for AI开发,旨在通过混合多种指令数据集来提升模型在复杂任务中的泛化能力。llama-3-tulu-v2-sft-subset的创建进一步扩展了这一研究方向,特别是在使用更大规模模型生成数据方面,为研究社区提供了新的实验平台。该数据集的出现为自然语言处理领域的研究者提供了丰富的资源,尤其是在模型微调和生成任务中,具有重要的参考价值。
当前挑战
llama-3-tulu-v2-sft-subset数据集在构建和应用过程中面临多重挑战。首先,数据生成过程中需要处理API的最大长度限制,这导致部分提示内容为空,需要通过过滤机制进行处理。其次,数据集的多样性依赖于多个子集(如GPT4-Alpaca、Open Orca和Coda Alpaca)的整合,如何确保这些子集之间的平衡性和一致性是一个技术难点。此外,使用大规模模型(如Llama 3.1 405B)生成数据时,计算资源和时间成本较高,这对数据集的扩展和更新提出了挑战。最后,数据集的应用场景主要集中在指令微调任务中,如何进一步提升模型在复杂任务中的表现,仍需深入研究。
常用场景
经典使用场景
llama-3-tulu-v2-sft-subset数据集主要用于自然语言处理领域中的指令微调任务。该数据集通过结合Llama 3.1 405B模型生成的对话数据,为研究人员提供了一个高质量的指令-响应对集合,特别适用于训练和评估对话生成模型。其经典使用场景包括对话系统的开发、指令跟随任务的优化以及多轮对话的生成与评估。
解决学术问题
该数据集解决了对话生成模型中指令理解与响应的准确性问题。通过提供多样化的指令-响应对,研究人员能够更好地训练模型以理解复杂指令并生成符合上下文的响应。此外,该数据集还帮助解决了多轮对话中上下文一致性的挑战,为对话系统的研究提供了重要的数据支持。
实际应用
在实际应用中,llama-3-tulu-v2-sft-subset数据集被广泛用于开发智能助手、客服机器人和教育领域的对话系统。其高质量的对话数据能够显著提升系统的指令理解能力和响应质量,从而改善用户体验。此外,该数据集还可用于生成个性化的对话内容,满足不同场景下的需求。
数据集最近研究
最新研究方向
在自然语言处理领域,llama-3-tulu-v2-sft-subset数据集的最新研究方向聚焦于利用Llama 3.1 405B模型对Tulu 2 SFT Mix子集进行重新生成。这一研究不仅展示了大规模语言模型在指令微调任务中的潜力,还通过GPT-4生成的子集(如GPT4-Alpaca、Open Orca和Coda Alpaca)进一步验证了模型在多样化任务中的泛化能力。该数据集的应用推动了对话系统、指令理解和生成模型的前沿研究,特别是在多轮对话和复杂指令处理方面,为未来的智能助手和自动化系统提供了重要的数据支持。
以上内容由遇见数据集搜集并总结生成


