GEO-Bench
收藏Hugging Face2025-12-17 更新2025-12-18 收录
下载链接:
https://huggingface.co/datasets/cx-cmu/GEO-Bench
下载链接
链接失效反馈官方服务:
资源简介:
这是一个研究领域的数据集,随**AutoGEO**发布,用于**生成引擎优化(GEO)**研究。数据集包含多个配置:main(用于GEO训练和评估的主要训练/测试数据)、rule_candidate(用于内容偏好规则提取的数据)、cold_start(用于AutoGEO Mini的监督微调数据)、inference(仅用于推理的数据)、grpo_input(用于GRPO训练的输入数据)和grpo_eval(用于GRPO训练模型的评估数据)。
This is a research-domain dataset released alongside **AutoGEO**, tailored for research on **Generative Engine Optimization (GEO)**. The dataset includes multiple configurations: main (primary training and test data for GEO training and evaluation), rule_candidate (data for content preference rule extraction), cold_start (supervised fine-tuning data for AutoGEO Mini), inference (data solely for inference), grpo_input (input data for GRPO training), and grpo_eval (evaluation data for models trained via GRPO).
创建时间:
2025-12-13
原始信息汇总
GEO-Bench 数据集概述
基本信息
- 数据集名称: GEO-Bench Dataset (AutoGEO)
- 发布机构: 与 AutoGEO 一同发布
- 主要用途: 用于生成式搜索引擎优化研究
- 许可证: MIT
- 任务类别: 文本生成
- 相关标签: 生成式搜索、地理信息、AutoGEO、电子商务、大语言模型、强化学习
数据集配置
数据集包含多个配置,每个配置对应不同的数据子集和用途:
- main: 用于 GEO 训练和评估的主要训练/测试数据(约 8k 训练样本 / 约 1k 测试样本)
- rule_candidate: 用于内容偏好规则提取的数据(约 8k 样本)
- cold_start: 用于 AutoGEO Mini 监督微调的数据(约 3.5k 样本)
- inference: 仅用于推理的数据(约 1k 样本)
- grpo_input: 用于 GRPO 训练的输入数据(约 8k 样本)
- grpo_eval: 用于评估 GRPO 训练模型的数据(约 8k 样本)
相关资源
- 论文: "What Generative Search Engines Like and How to Optimize Web Content Cooperatively"
- 作者: Yujiang Wu*, Shanshan Zhong*, Yubin Kim, Chenyan Xiong (*Equal contribution)
- 代码库: AutoGEO on GitHub
引用格式
bibtex @article{wu2025generative, title={What Generative Search Engines Like and How to Optimize Web Content Cooperatively}, author={Wu, Yujiang and Zhong, Shanshan and Kim, Yubin and Xiong, Chenyan}, journal={arXiv preprint arXiv:2510.11438}, year={2025} }
搜集汇总
数据集介绍
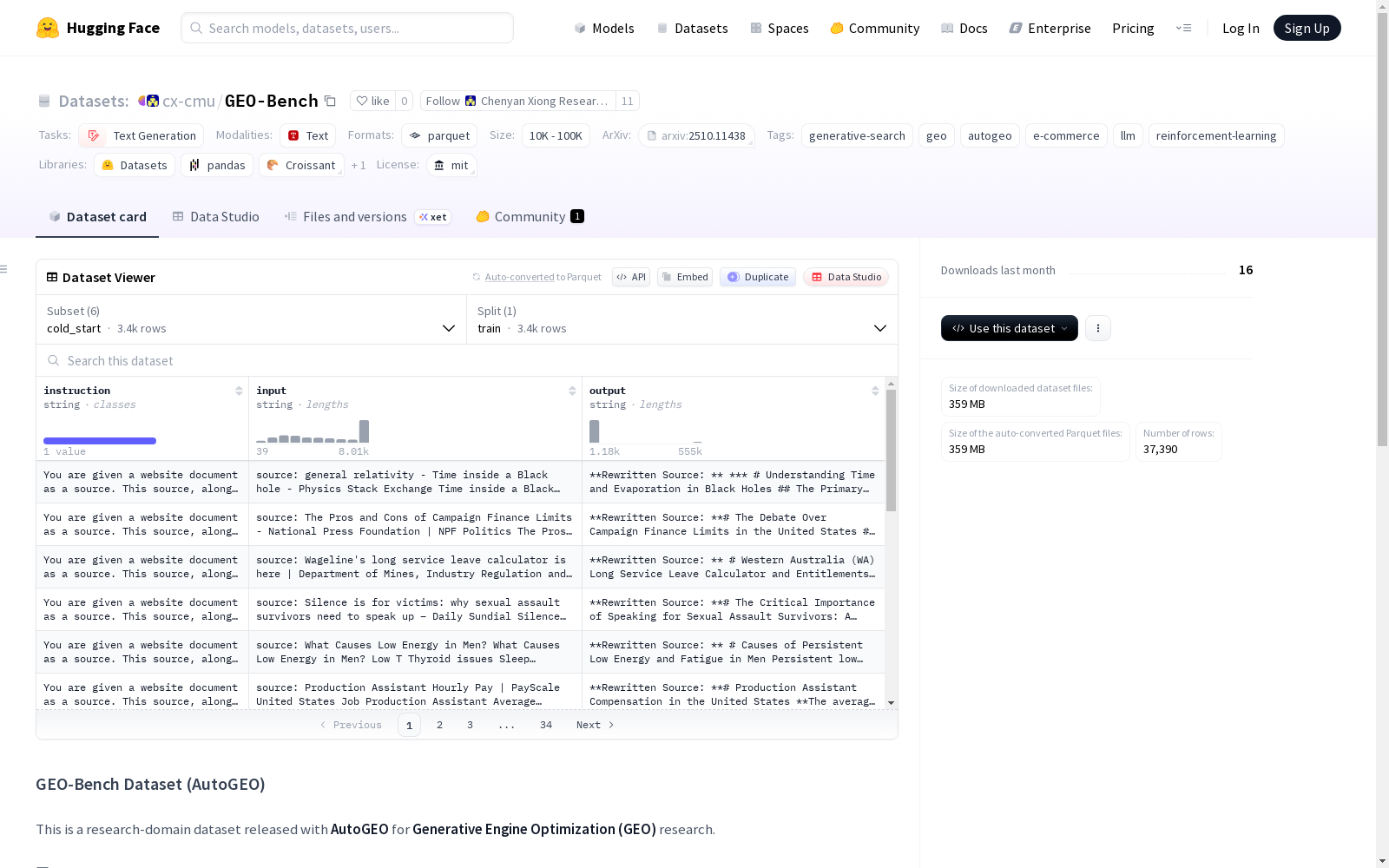
构建方式
在生成式搜索引擎优化研究领域,GEO-Bench数据集的构建遵循了严谨的学术范式。其核心数据来源于对生成式搜索引擎交互行为的系统性采集与标注,旨在模拟真实网络内容优化场景。研究人员通过设计多阶段的数据处理流程,生成了包括主训练测试集、规则候选集、冷启动微调集以及用于强化学习训练与评估的专用子集。每个子集均经过精心划分,例如主配置包含约八千条训练样本和一千条测试样本,确保了数据在模型训练与性能评估中的有效性和代表性。
特点
该数据集的一个显著特点是其多维度的任务导向性结构,专门服务于生成式搜索引擎优化这一前沿研究方向。它提供了多种配置,如用于内容偏好规则提取的规则候选集、支持模型冷启动的监督微调数据,以及适配生成式强化学习策略优化的输入与评估集。这种模块化设计使得研究者能够针对GEO任务的不同层面,如内容生成、策略学习和效果评估,进行灵活而深入的实验探索。数据集紧密关联实际电子商务与生成式搜索场景,具有高度的领域针对性和实用性。
使用方法
对于希望利用GEO-Bench的研究者而言,其使用路径清晰而高效。用户可通过HuggingFace平台提供的配置选择器,便捷地访问不同的数据子集。例如,进行基础的GEO模型训练与评估可加载‘main’配置;若需研究内容优化规则,则可调用‘rule_candidate’子集。针对特定的训练范式,如使用GRPO进行强化学习,数据集专门提供了‘grpo_input’和‘grpo_eval’配置以支持端到端的实验流程。这种按需取用的设计,极大便利了复杂研究管线的构建与复现。
背景与挑战
背景概述
生成式搜索引擎优化(GEO)作为信息检索领域的前沿方向,旨在探索如何使网络内容更适配于生成式搜索模型的偏好。GEO-Bench数据集由卡内基梅隆大学等机构的研究团队于2025年创建,伴随AutoGEO框架一同发布,其核心研究问题聚焦于理解生成式搜索引擎的内容倾向,并以此为基础优化网页内容。该数据集为生成式搜索、电子商务与大语言模型协同优化提供了关键基准,推动了检索系统从传统匹配向生成式交互的范式转变。
当前挑战
GEO-Bench致力于解决生成式搜索引擎优化中的核心挑战,即如何量化并建模生成式模型对内容的结构、语义与风格偏好,以指导内容创作与调整。在构建过程中,数据集需克服多维度标注的复杂性,包括从真实查询-生成结果对中提取可泛化的优化规则,并确保不同配置(如冷启动、强化学习输入)间数据的一致性与评估有效性。此外,生成式搜索的动态性与黑箱特性也为构建具有高信噪比的训练样本带来了显著困难。
常用场景
经典使用场景
在生成式搜索引擎优化领域,GEO-Bench数据集为研究者和开发者提供了一个标准化的评估平台。该数据集主要用于训练和评估生成式搜索引擎优化模型,通过其主配置中的训练和测试数据,支持模型学习如何优化网页内容以提升在生成式搜索中的可见性。经典使用场景涉及利用强化学习策略,模拟生成式搜索引擎的偏好,从而自动生成或调整内容,以适应不断演进的搜索范式。
解决学术问题
GEO-Bench数据集致力于解决生成式搜索时代内容优化的核心学术挑战。它帮助研究者探究生成式搜索引擎的内容偏好机制,为自动化优化方法提供数据基础。通过规则候选和冷启动等配置,数据集支持从规则提取到模型微调的全流程研究,推动了生成式搜索引擎优化理论的深化,并为评估模型在真实场景中的泛化能力设立了基准。
衍生相关工作
围绕GEO-Bench数据集,衍生出了一系列重要的研究工作,其中AutoGEO框架是典型代表。该框架利用数据集的多个配置,实现了从监督微调到基于强化学习的策略优化完整流程。相关研究进一步探索了生成式搜索的协同优化机制,推动了大型语言模型在搜索优化中的应用,并为后续在生成式信息检索领域的模型开发和评估提供了重要参考。
以上内容由遇见数据集搜集并总结生成


