有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
该数据集包含原始文章及其AI生成的补全内容。
human: 原始完整文章ai: 使用GPT-3.5 Turbo生成的AI补全内容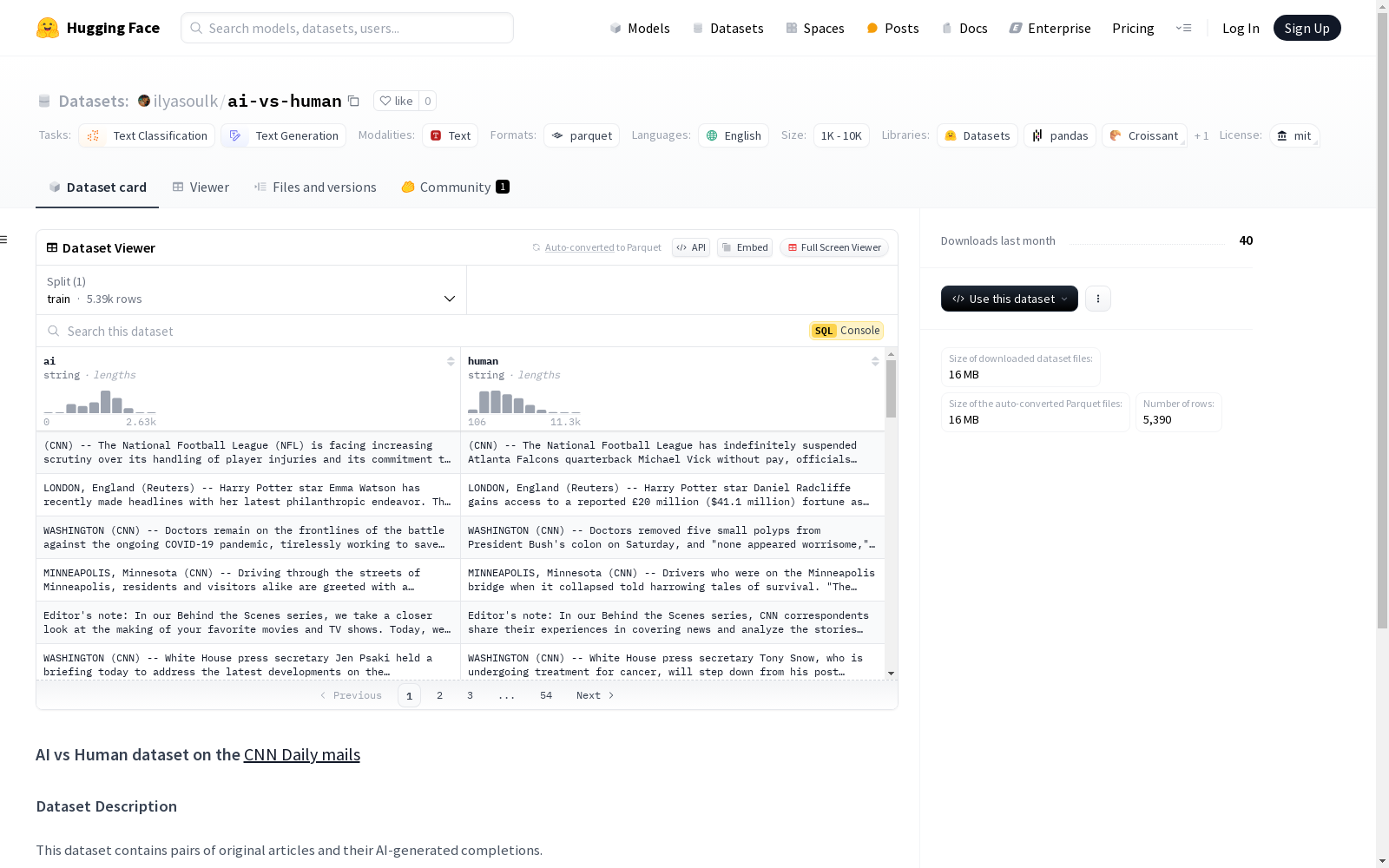
基于站点观测的中国1km土壤湿度日尺度数据集(2000-2022)
本研究提供了中国范围1km高质量的土壤湿度数据集-SMCI1.0(Soil Moisture of China by in situ data, version 1.0),SMCI1.0是包含2000-2022年、日尺度、以10厘米为间隔10层深度(10-100cm)的高时空分辨率土壤湿度,数据单位为0.001m³/m³,缺失值为-999,投影为WGS1984。该数据集是以中国气象局提供的1,648个站点观测10层土壤湿度作为基准,使用ERA5_Land气象强迫数据、叶面积指数(LAI)、土地覆盖类型(Landtypes)、地形(DEM)和土壤特性(Soil properties)作为协变量,通过机器学习方式获得。本研究进行了两组实验以验证SMCI1.0的精度,时间尺度上:ubRMSE为0.041-0.052,R为0.883-0.919;空间尺度上:ubRMSE为0.045-0.051,R为0.866-0.893。 由于SMCI1.0是基于实地观测的土壤湿度,它可以作为现有基于模型和卫星数据集的有效补充。该数据产品可用于各种水文、气象、生态分析和建模,尤其在需要高质量、高分辨率土壤湿度的应用上至关重要。有关数据集的引用及详细描述,请阅读说明文档。为便于使用,本研究提供了两种不同分辨率的版本:30 秒(~1km)和0.1度(~9km)。
国家青藏高原科学数据中心 收录
中国知识产权局专利数据库
该数据集包含了中国知识产权局发布的专利信息,涵盖了专利的申请、授权、转让等详细记录。数据内容包括专利号、申请人、发明人、申请日期、授权日期、专利摘要等。
www.cnipa.gov.cn 收录
中国空气质量数据集(2014-2020年)
数据集中的空气质量数据类型包括PM2.5, PM10, SO2, NO2, O3, CO, AQI,包含了2014-2020年全国360个城市的逐日空气质量监测数据。监测数据来自中国环境监测总站的全国城市空气质量实时发布平台,每日更新。数据集的原始文件为CSV的文本记录,通过空间化处理生产出Shape格式的空间数据。数据集包括CSV格式和Shape格式两数数据格式。
国家地球系统科学数据中心 收录
中国逐日降水数据集(1961-2022,0.1°/0.25°/0.5°)
CHM_PRE数据集基于中国境内及周边1961至今共2839个站点的日降水观测,在传统的“降水背景场 + 降水比值场”的数据集构建思路上,尝试应用月值降水约束和地形特征校正,并依据中国范围内约4万个高密度站点2015–2019年的日降水量插值后数据进行精度评价。经评估认为,CHM_PRE可以较好的表征降水的空间变异性,其日值时间序列与高密度站点日值降水观测结果之间的相关系数中位数为0.78,均方根误差中位数为8.8 mm/d,KGE值中位数为0.69,与目前常用的降水数据集(CGDPA、CN05.1、CMA V2.0)有很好的一致性。 数据集的时间范围为1961年至今,空间分辨率为0.1°、0.25°和0.5°,经纬度范围为18°N–54°N, 72°E–136°E。
国家青藏高原科学数据中心 收录
FAOSTAT Agricultural Data
FAOSTAT Agricultural Data 是由联合国粮食及农业组织(FAO)提供的全球农业数据集。该数据集涵盖了农业生产、贸易、价格、土地利用、水资源、气候变化、人口统计等多个方面的详细信息。数据包括了全球各个国家和地区的农业统计数据,旨在为政策制定者、研究人员和公众提供全面的农业信息。
www.fao.org 收录