DFKI-SLT/nyt-multi
收藏Hugging Face2024-08-11 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/DFKI-SLT/nyt-multi
下载链接
链接失效反馈官方服务:
资源简介:
NYT-multi数据集源自Riedel等人(2010)的NYT数据集,包含1987-2007年间的《纽约时报》新闻文章,这些文章通过FreeBase进行了远程关系标注。Zeng等人(2018)在此基础上进行了过滤,去除了超过100个单词的句子和没有活跃关系的句子,最终保留了66195个句子。数据集被分为训练集(56195句)、验证集(5000句)和测试集(5000句)。NYT-multi数据集包含三种实体类型和24种关系类型,数据经过StanfordCoreNLP预处理,并转换为更易读的JSON格式。
NYT-multi数据集源自Riedel等人(2010)的NYT数据集,包含1987-2007年间的《纽约时报》新闻文章,这些文章通过FreeBase进行了远程关系标注。Zeng等人(2018)在此基础上进行了过滤,去除了超过100个单词的句子和没有活跃关系的句子,最终保留了66195个句子。数据集被分为训练集(56195句)、验证集(5000句)和测试集(5000句)。NYT-multi数据集包含三种实体类型和24种关系类型,数据经过StanfordCoreNLP预处理,并转换为更易读的JSON格式。
提供机构:
DFKI-SLT
原始信息汇总
数据集概述
基本信息
- 数据集名称: NYT-multi
- 语言: 英语
- 标签: news, relation-extraction
- 大小类别: 10K<n<100K
数据集结构
配置: default
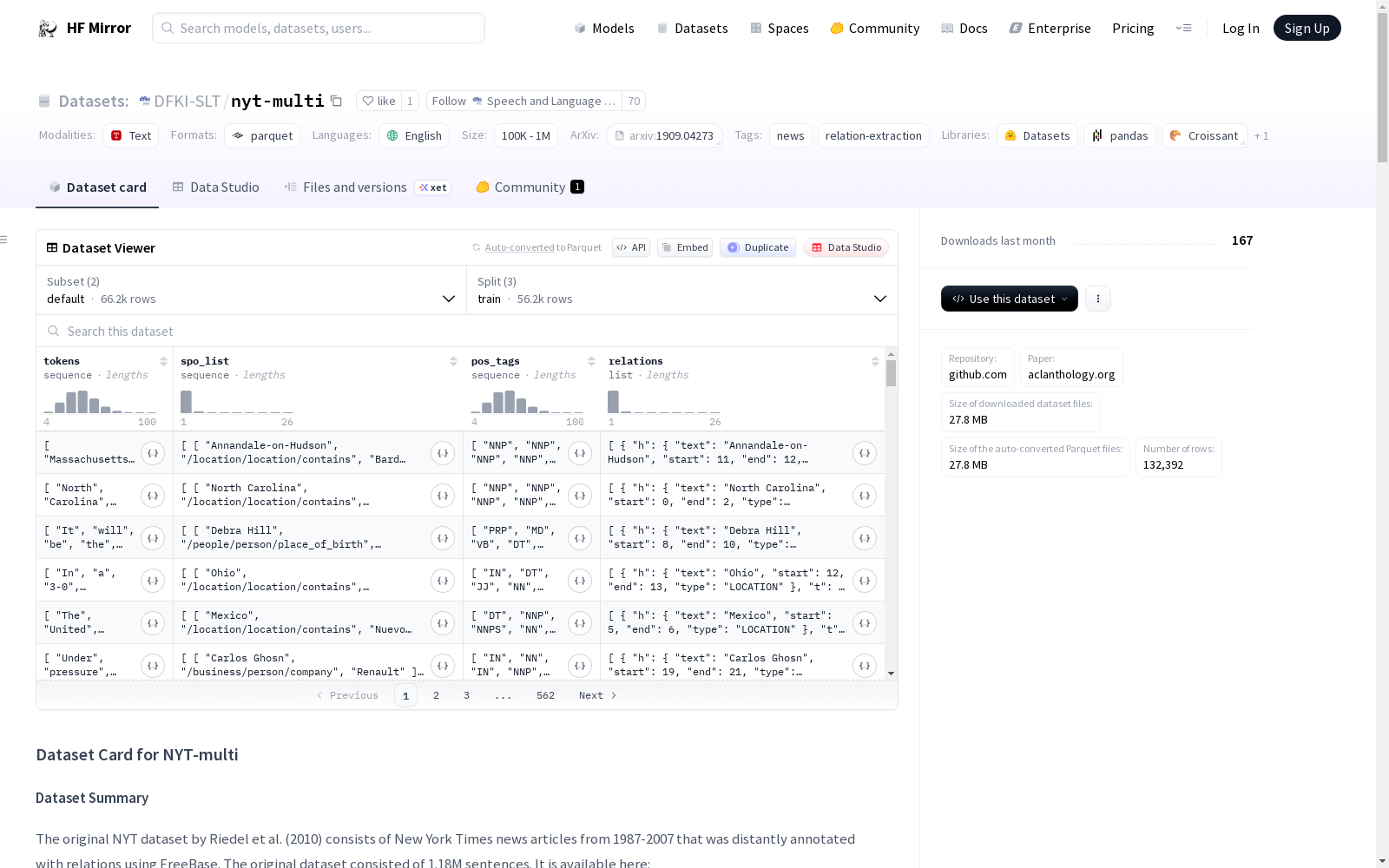
- 特征:
tokens: 分词后的文本,类型为listofstring。spo_list: 关系三元组,类型为listoflistofstring。pos_tags: 词性标签,类型为listofstring。relations: 关系列表h: 头部实体text: 实体文本,类型为string。start: 头部实体起始索引,类型为int64。end: 头部实体结束索引,类型为int64。type: 实体类型,类型为string。
t: 尾部实体text: 实体文本,类型为string。start: 尾部实体起始索引,类型为int64。end: 尾部实体结束索引,类型为int64。type: 实体类型,类型为string。
type: 关系类型,类型为string。
配置: raw
- 特征:
sentText: 文本,类型为string。articleId: 文章ID,类型为string。relationMentions: 关系提及列表em1Text: 头部实体文本,类型为string。em2Text: 尾部实体文本,类型为string。label: 关系类型,类型为string。
entityMentions: 实体提及列表start: 实体起始索引,类型为int64。label: 实体类型,类型为string。text: 实体文本,类型为string。
sentId: 句子索引,类型为string。
数据集拆分
- 训练集: 56196个样本,大小为48934795字节。
- 验证集: 5000个样本,大小为4369341字节。
- 测试集: 5000个样本,大小为4395817字节。
数据集大小
- 下载大小: 14425744字节
- 数据集大小: 57699953字节
引用信息
-
BibTeX:
@inproceedings{zeng-etal-2018-extracting, title = "Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism", author = "Zeng, Xiangrong and Zeng, Daojian and He, Shizhu and Liu, Kang and Zhao, Jun", booktitle = "Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2018", address = "Melbourne, Australia", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/P18-1047", doi = "10.18653/v1/P18-1047", pages = "506--514", }
-
APA:
- Zeng, X., Zeng, D., He, S., Liu, K., & Zhao, J. (2018, July). Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 506-514).
搜集汇总
数据集介绍
构建方式
NYT-multi数据集是在原有NYT数据集基础上,通过过滤和筛选构建而成的。原始的NYT数据集由Riedel等人于2010年构建,包含1987年至2007年间的纽约时报新闻文章,并通过FreeBase进行远程注释。Zeng等人于2018年对原始数据集进行了筛选,去除了超过100个单词的句子以及没有活跃关系的句子,最终保留了66195个句子。这些句子中随机选择了5000个作为测试集,5000个作为验证集,其余的56195个作为训练集。此外,数据集还采用了StanfordCoreNLP进行预处理,并将其转换为更易读的JSON格式。
使用方法
使用NYT-multi数据集时,可以根据具体需求选择不同的配置。默认配置提供了分词、词性标注和实体关系等信息,适合用于关系抽取任务。原始配置则提供了更详细的数据,包括句子文本、文章ID、实体提及和关系提及等信息,适合用于更深入的分析和研究。在加载数据集时,可以使用HuggingFace的datasets库进行加载。例如,使用`datasets.load_dataset('DFKI-SLT/nyt-multi', config='default')`可以加载默认配置的数据集。
背景与挑战
背景概述
关系抽取是自然语言处理领域的重要任务,旨在从文本中自动识别实体之间的关系。NYT-multi数据集是基于纽约时报新闻文章构建的关系抽取数据集,它包含三类实体和24种关系类型。该数据集由Zeng等人于2018年创建,并通过斯坦福CoreNLP工具进行预处理。NYT-multi数据集在关系抽取任务中具有重要的影响力,为相关研究提供了宝贵的资源。
当前挑战
NYT-multi数据集在构建过程中面临一些挑战。首先,数据集的构建需要从大量的文本中筛选出具有关系的句子,这是一个复杂的过程。其次,数据集的标注需要人工参与,这可能导致标注不一致和错误。此外,随着新闻文章的不断更新,数据集的时效性和覆盖范围也需要不断地更新和扩展。
常用场景
经典使用场景
在自然语言处理领域,关系抽取(Relation Extraction, RE)是一项至关重要的任务,其目标是从非结构化文本中识别实体间的关系。NYT-multi数据集作为关系抽取任务的经典数据集,广泛应用于模型训练与评估。数据集包含来自纽约时报的新闻文章,并标注了实体及其间的关系。该数据集的标注特点在于其丰富的实体类型和关系类型,使得模型能够学习到更复杂的语义关系。同时,NYT-multi数据集还包含了实体提及的位置信息,有助于模型理解实体在句子中的位置关系。这一特性使得NYT-multi数据集在关系抽取任务中具有重要的研究价值。
解决学术问题
NYT-multi数据集解决了关系抽取任务中的实体类型和关系类型识别问题。数据集的标注信息涵盖了丰富的实体类型和关系类型,使得模型能够学习到更复杂的语义关系。此外,NYT-multi数据集还包含了实体提及的位置信息,有助于模型理解实体在句子中的位置关系。这一特性使得NYT-multi数据集在关系抽取任务中具有重要的研究价值。此外,NYT-multi数据集还解决了数据集规模问题。数据集包含了大量的标注数据,使得模型能够在更广泛的数据集上进行训练和评估。
实际应用
NYT-multi数据集在实际应用中具有广泛的应用前景。在新闻媒体领域,关系抽取技术可以用于自动构建新闻知识图谱,帮助用户快速了解新闻事件之间的关系。在搜索引擎领域,关系抽取技术可以用于改进搜索引擎的检索效果,提高用户搜索体验。在问答系统领域,关系抽取技术可以用于自动构建知识库,提高问答系统的准确性和效率。此外,NYT-multi数据集还可以用于其他自然语言处理任务,如实体识别、事件抽取等。
数据集最近研究
最新研究方向
在关系抽取领域,DFKI-SLT/nyt-multi数据集被广泛用于训练和评估模型。最新的研究趋势集中在如何更好地处理跨实体类型的关系抽取,特别是在新闻文本中。这些研究不仅关注于提高抽取的准确性,还致力于探索如何通过联合实体识别和关系抽取来增强模型的鲁棒性。此外,利用端到端的神经网络模型,特别是带有复制机制的序列到序列学习模型,已成为关系抽取研究的热点。这些模型在处理复杂句子结构和实体关系重叠方面表现出色。随着新闻文本分析在信息传播和社会影响评估中的重要性日益增加,这一研究方向对于理解新闻内容中的复杂关系网络具有重要的理论和实践意义。
以上内容由遇见数据集搜集并总结生成


