DRIVELHUB
收藏arXiv2025-09-04 更新2025-11-24 收录
下载链接:
https://hf-mirror.com/datasets/extraordinarylab/drivel-hub
下载链接
链接失效反馈官方服务:
资源简介:
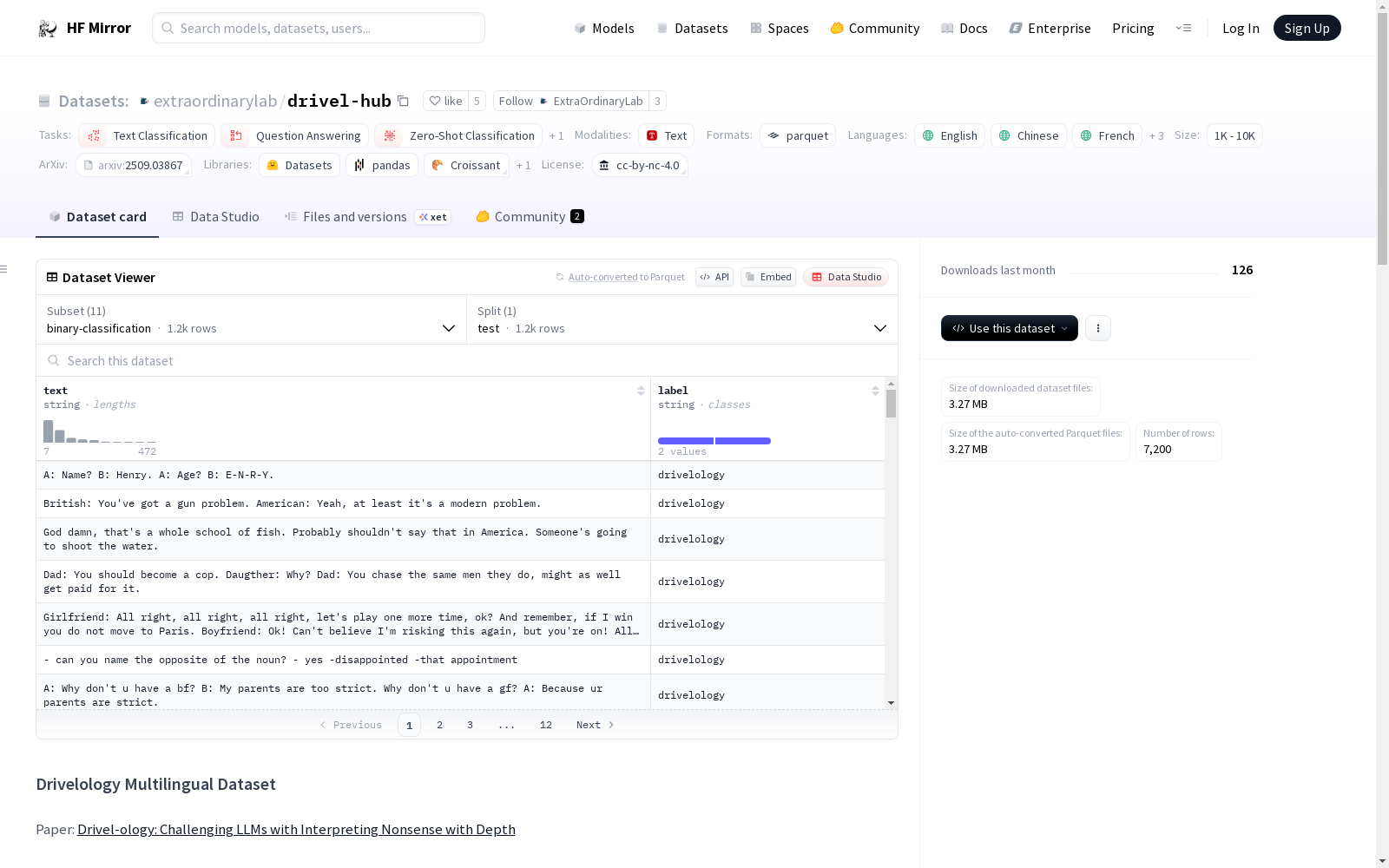
DRIVELHUB是一个评估大型语言模型(LLM)理解“深度无意义”语言现象的基准数据集。数据集包含超过1200个经过精心挑选的例子,涵盖了英语、普通话、西班牙语、法语、日语和韩语。每个样本都标注了其试图传达的潜在信息。数据集的创建过程非常严格,每个候选示例都经过多轮独立审查和深入讨论。该数据集旨在评估LLM在理解和推理不同层面的“深度无意义”语言方面的能力,为开发具有更高社会和语义理解能力的智能系统提供重要参考。
DRIVELHUB is a benchmark dataset developed to evaluate the ability of Large Language Models (LLMs) to understand "deeply nonsensical" linguistic phenomena. The dataset contains over 1,200 carefully curated examples spanning six languages: English, Mandarin, Spanish, French, Japanese, and Korean. Each sample is annotated with the underlying implicit information it aims to convey. The dataset was constructed through a rigorous workflow, where every candidate example has undergone multiple rounds of independent reviews and in-depth discussions. This benchmark aims to assess LLMs’ capacities for understanding and reasoning across various levels of "deeply nonsensical" language, serving as a vital reference for developing intelligent systems with improved social and semantic comprehension abilities.
提供机构:
The University of Manchester, Durham University, The University of Sheffield
创建时间:
2025-09-04
搜集汇总
数据集介绍
构建方式
在自然语言处理领域探索大语言模型深层语义理解能力的背景下,DRIVELHUB数据集通过多语言社交媒体平台手工采集与专家标注构建而成。研究团队从Instagram、TikTok等年轻用户主导平台随机浏览获取语料,采用四阶段标注流程:首先由具备多语言能力的硕士以上学历标注者进行样本筛选,随后通过多轮独立评审与群体讨论确定分类标签,再结合GPT-4辅助生成隐含叙事并人工校验,最后由语言学与心理学专家进行质量把控,确保1200个样本在语义深度与文化语境上的标注精确性。
使用方法
研究者可通过四阶段任务框架系统评估模型性能:在胡言检测任务中执行二分类判断,标签标注任务进行多标签分类,隐含叙事写作考察深层语义生成能力,叙事选择任务则通过单选与‘以上皆非’选项设置不同难度层级。实验建议采用零样本提示策略,通过多轮提示验证降低方差,并运用BERTScore与LLM-as-a-judge双指标评估生成质量。数据集支持跨语言对比分析,可通过调整提示语言探究模型的文化认知差异,为语义理解研究提供标准化评估范式。
背景与挑战
背景概述
DRIVELHUB数据集由曼彻斯特大学、杜伦大学和谢菲尔德大学的研究团队于2025年创建,旨在探索语言模型对‘废话学’现象的理解能力。废话学是一种独特的语言现象,表现为表层句法连贯但蕴含深层语用悖论、情感负载或修辞颠覆的文本,要求模型具备语境推理、道德判断和情感解读能力。该数据集包含超过1200个精心标注的多语言样本,覆盖英语、汉语、西班牙语等六种语言,为评估语言模型的语义深度理解提供了重要基准,推动了自然语言处理领域对非线性和创造性语言理解的研究。
当前挑战
DRIVELHUB数据集面临的挑战主要体现在领域问题和构建过程两方面。在领域层面,该数据集旨在解决语言模型对具有多层隐含意义的废话学文本的深度理解问题,但现有模型常将废话学与浅层无意义文本混淆,难以捕捉其隐含的修辞功能和情感张力,暴露出模型在语用理解和认知共情方面的表征缺陷。构建过程中,由于废话学的主观性和模糊性,标注工作极具挑战性,每个样本需经过多轮专家评审和集体讨论以确保其符合废话学特征,同时需平衡多语言样本的分布差异,避免文化语境偏差影响数据集的泛化能力。
常用场景
经典使用场景
在自然语言处理领域,DRIVELHUB数据集作为评估大语言模型理解复杂语言现象能力的重要基准,其经典应用场景集中于测试模型对表层荒谬与深层语义结合的文本解析。该数据集通过精心设计的分类、生成和推理任务,系统检验模型在识别反讽、矛盾修辞及文化隐喻等方面的表现,为揭示语言模型在语用理解层面的局限性提供了标准化评估框架。
解决学术问题
该数据集有效解决了当前大语言模型在语用推理与深层语义理解方面的核心学术难题。通过构建具有多重修辞层次的语料,它揭示了模型在处理需要文化背景知识、情感推断和逻辑悖论解析任务时的表征缺陷,挑战了统计流畅性等同于认知理解的假设,为构建具有社会智能的AI系统提供了关键理论依据。
实际应用
在实际应用层面,DRIVELHUB数据集对提升人工智能系统的社会交互能力具有显著价值。其在内容审核系统中能增强对语境模糊文本的辨识精度,在创意写作辅助工具中可促进更具深度的语言生成,同时为跨文化交际平台提供对隐含语义的解析支持,推动人机交互向更自然、更具文化敏感性的方向发展。
数据集最近研究
最新研究方向
在自然语言处理领域,DRIVELHUB数据集聚焦于探索大语言模型对'废话学'现象的理解能力,即表层无意义但蕴含深层语义的文本。前沿研究揭示,当前模型在分类、生成和推理任务中普遍存在局限性,难以捕捉文本中的反讽、悖论和语境反转等复杂修辞结构。这一挑战推动了模型在跨语言文化理解、非线性和情感推理方面的创新,尤其关注多语言环境下模型对隐含叙事和语用矛盾的解析能力,为构建更具社会智能的AI系统提供了关键基准。
相关研究论文
- 1通过The University of Manchester, Durham University, The University of Sheffield · 2025年
以上内容由遇见数据集搜集并总结生成


