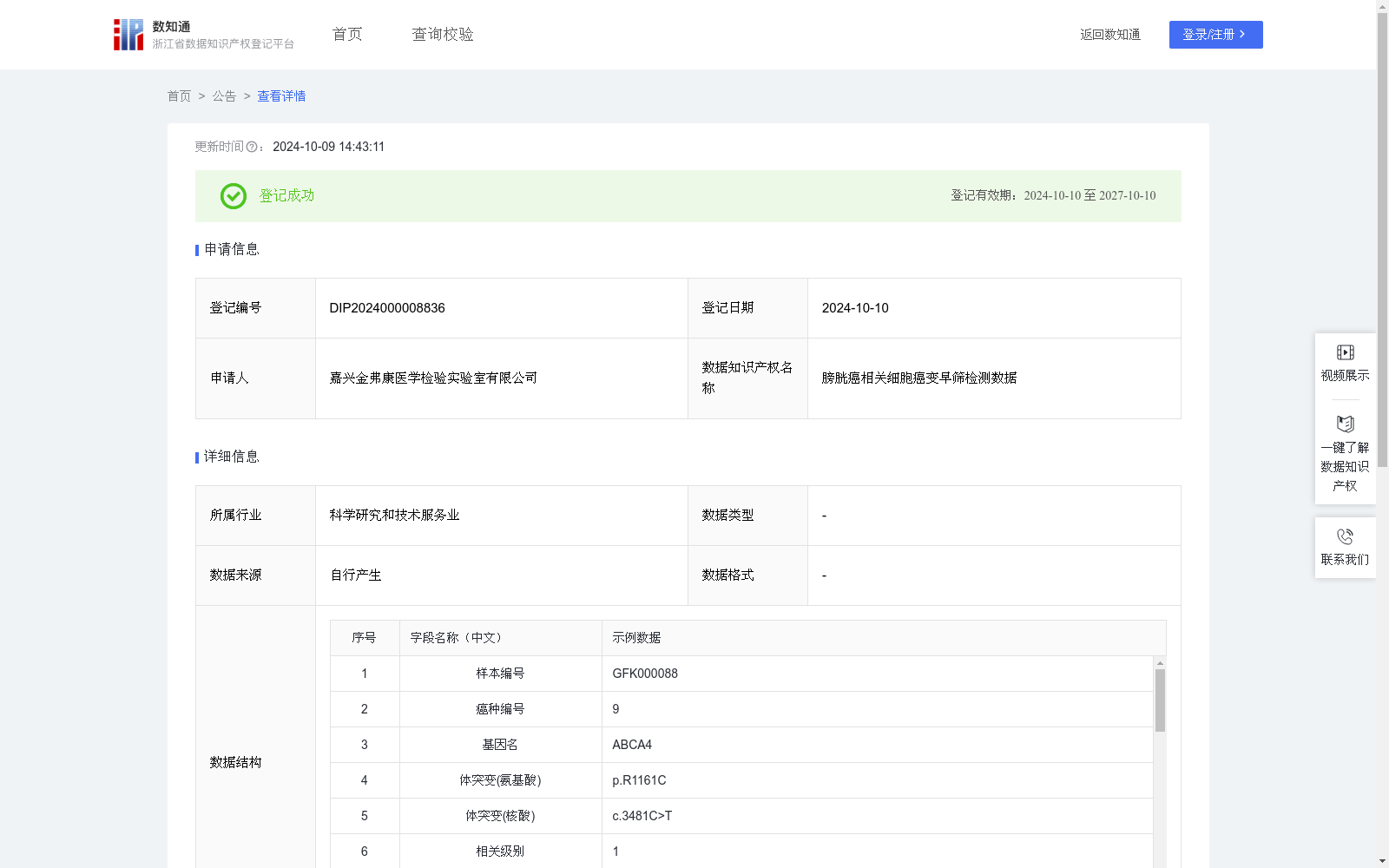
膀胱癌相关细胞癌变早筛检测数据
收藏浙江省数据知识产权登记平台2024-10-09 更新2024-10-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/68623
下载链接
链接失效反馈官方服务:
资源简介:
癌症早筛检测,通过检测15毫升血液中DNA碎片里面是否含有癌特异性突变,实现对细胞癌化信号的早期排查。采用专利分子捕获技术和高通量测序技术检测血液中来自不同组织癌化细胞的DNA小片段,覆盖关键抑癌基因中超1900种特异突变指标,对体内是否存在癌化克隆细胞(癌细胞的前体)、存在多少以及在哪里进行计算,可对正常细胞的癌化进程进行定量监控,能让预警发生在细胞癌变前,及早发现和治疗膀胱癌患者,减少因晚期治疗而带来的高昂医疗费用和医疗资源的浪费。
使用专利分子捕获技术和高通量测序技术检测血液中来自不同组织癌化细胞的DNA小片段,覆盖关键抑癌基因中超1900种特异突变指标。1、数据质量控制:对原始的FASTQ文件进行质控,检查序列数据的质量,移除污染序列,确保数据的准确性;2、去接头:去除接头序列和低质量的碱基,确保分析过程中只使用高质量的序列。3、序列比对:使用比对工具将质控后的序列映射比对。4、突变位点检测:选择特定的变异检测工具,检测比对后序列的变异性,得到显著突变位点;5、位点功能注释:结合选择的BED文件对显著突变位点进行功能注释,判断在基因组中的位置(如是否位于功能重要区域或已知的致病性位点),得到“突变区域”字段。6、癌症相关性分析:利用注释信息和临床数据库,分析显著突变位点与不同类型癌症的关联性,得到“癌种编号”,“相关级别”字段若为特异性相关记为“1”,普通相关记为“2”。7、基于蛋白质原始状态和突变后的物理化学性质构建OBCD癌症早筛模型,通过分析突变前后蛋白质性质发生的变化,判断该显著突变位点发生突变对人体的影响,结合蛋白质在细胞信号转导过程中是否发生磷酸化以及对应的净电荷,为癌症的早筛提供参考依据。
This cancer early screening detection realizes early screening of cellular carcinogenic signals by detecting the presence of cancer-specific mutations in DNA fragments extracted from 15 mL of blood sample. Adopting patented molecular capture technology and high-throughput sequencing technology, it detects small DNA fragments derived from carcinogenic cells of various tissues in peripheral blood, covering over 1900 specific mutation indicators in key tumor suppressor genes. It can quantify and calculate whether carcinogenic clone cells (precursors of cancer cells) exist in the body, their quantity and tissue distribution, conduct quantitative monitoring of the carcinogenic progression of normal cells, enable early warning prior to cellular malignant transformation, facilitate early detection and treatment of bladder cancer patients, and reduce exorbitant medical costs and waste of medical resources caused by late-stage treatment.
The analysis workflow consists of the following 7 core steps:
1. Data Quality Control: Conduct quality control on the original FASTQ files, evaluate the quality of sequence data, remove contaminated sequences, and ensure the accuracy of subsequent analysis data.
2. Adapter Trimming: Eliminate adapter sequences and low-quality base calls to ensure only high-quality sequence data is utilized in downstream analysis.
3. Sequence Alignment: Employ dedicated alignment tools to map the quality-controlled sequence reads to the reference genome.
4. Mutation Site Detection: Select specific variant calling tools to identify sequence variations in the aligned reads, and screen out statistically significant mutation sites.
5. Functional Annotation of Mutation Sites: Perform functional annotation on the significant mutation sites using the selected BED files, determine their genomic locations (e.g., whether they fall within functionally critical regions or known pathogenic loci), and generate the "mutation region" annotation field.
6. Cancer Association Analysis: Integrate annotation information and clinical databases to analyze the correlation between significant mutation sites and different cancer types, and generate the "cancer type number" field. If the mutation has specific cancer association, the "relevance level" field is marked as "1"; if it has general association, it is marked as "2".
7. OBCD Cancer Early Screening Model Construction: Build the OBCD cancer early screening model based on the native state of the target protein and the physicochemical properties of the mutated protein. By analyzing the changes in protein physicochemical properties before and after mutation, evaluate the potential impact of the significant mutation site on the human body. Combined with whether the protein undergoes phosphorylation during cell signal transduction and its corresponding net charge, this model provides a reliable reference basis for cancer early screening.
提供机构:
嘉兴金弗康医学检验实验室有限公司
创建时间:
2024-09-13
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


