有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
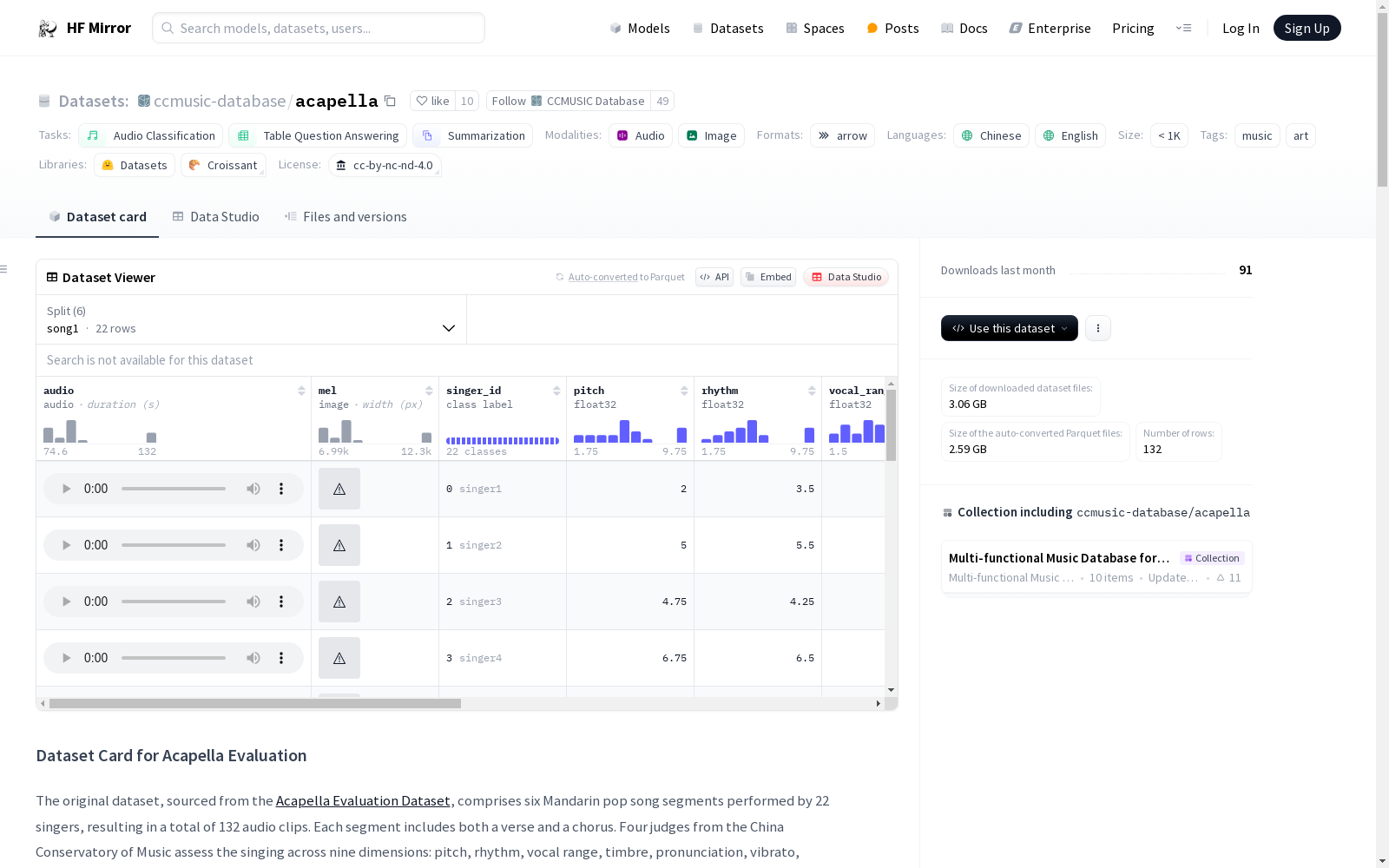
datasets库加载数据集,并按歌曲分段处理数据。bibtex @dataset{zhaorui_liu_2021_5676893, author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han}, title = {CCMusic: an Open and Diverse Database for Chinese and General Music Information Retrieval Research}, month = {mar}, year = {2024}, publisher = {HuggingFace}, version = {1.2}, url = {https://huggingface.co/ccmusic-database} }
THUCNews
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。本次比赛数据集在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。提供训练数据共832471条。
github 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录
Cultural Dimensions Dataset
该数据集包含了霍夫斯泰德文化维度理论(Hofstede's Cultural Dimensions Theory)的相关数据,涵盖了多个国家和地区的文化维度评分,如权力距离、个人主义与集体主义、男性化与女性化、不确定性规避、长期取向与短期取向等。这些数据有助于研究不同文化背景下的行为模式和价值观。
geerthofstede.com 收录
FER2013
FER2013数据集是一个广泛用于面部表情识别领域的数据集,包含28,709个训练样本和7,178个测试样本。图像属性为48x48像素,标签包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。
github 收录