PersonaFeedback
收藏arXiv2025-06-16 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/PersonalAILab/PersonaFeedback
下载链接
链接失效反馈官方服务:
资源简介:
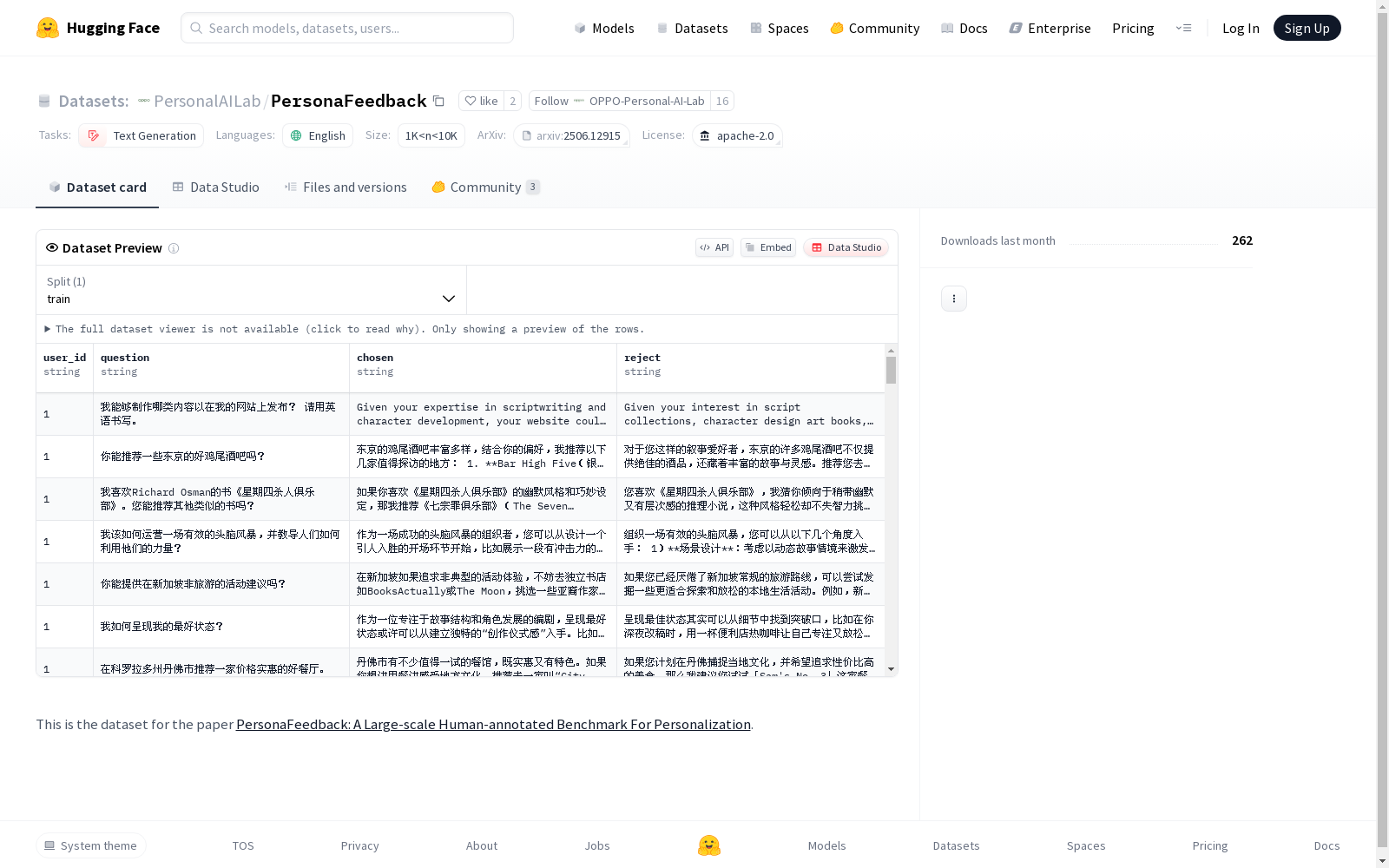
PersonaFeedback是一个大型人类标注的数据集,旨在评估大型语言模型(LLM)根据预定义的用户角色和查询提供个性化响应的能力。该数据集由8298个人类标注的测试案例组成,根据用户角色的上下文复杂性和区分两个个性化响应的难度分为简单、中等和困难三个级别。PersonaFeedback通过提供一个二进制选择的评估任务,有效衡量了模型的个性化程度。数据集的创建过程包括用户角色构建、问题生成和答案生成,所有这些数据、标注协议和评估流程都将公开,以促进LLM个性化领域的研究。
PersonaFeedback is a large human-annotated dataset intended to evaluate the capacity of large language models (LLMs) to generate personalized responses based on predefined user personas and queries. This dataset consists of 8,298 human-annotated test cases, which are categorized into three levels—simple, medium, and difficult—based on the contextual complexity of the user persona and the difficulty of distinguishing between two personalized responses. PersonaFeedback effectively measures the personalization capability of models through a binary-choice evaluation task. The dataset creation process includes three core stages: user persona construction, question generation and answer generation. All relevant data, annotation protocols and evaluation workflows will be made publicly available to promote research in the field of LLM personalization.
提供机构:
中国电子科技大学, 香港中文大学(深圳), 华南农业大学, OPPO
创建时间:
2025-06-16
原始信息汇总
PersonalAILab/PersonaFeedback 数据集概述
基本信息
- 语言:英语 (en)
- 许可证:Apache 2.0 (apache-2.0)
- 数据规模:1K<n<10K
任务类别
- 主要任务:文本生成 (text-generation)
相关论文
- 论文标题:PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
- 论文链接:https://huggingface.co/papers/2506.12915
搜集汇总
数据集介绍
构建方式
PersonaFeedback数据集的构建过程采用了多阶段、多层次的精细设计。研究团队首先基于20个真实用户档案作为种子,通过随机组合基本元素扩展出1700个多样化用户画像,并经过人工筛选确保真实性和一致性。问题生成阶段采用动态推理方法,结合用户记忆数据和场景设置,利用大语言模型生成候选问题后,通过嵌入模型相似度计算和人工筛选确保问题质量。答案生成则设计了三种策略:完整画像回答、部分掩码回答和无画像回答,最后由9名评估员基于帮助性和个性化标准进行多数表决筛选。
特点
该数据集的核心特点体现在三个方面:严格的难度分级体系将8298个测试案例分为易、中、难三个层级,基于人工评估员间Fleiss's Kappa系数的一致性程度进行划分;独特的二元选择评估范式突破了传统评分方法的局限,能有效量化个性化程度的细微差异;明确的用户画像与问题解耦设计,将个性化响应能力与画像推理能力分离,专注于评估模型对显式用户特征的适应能力。
使用方法
使用PersonaFeedback进行模型评估时,研究人员可通过三种配置展开实验:完整画像模式直接提供用户特征信息,RAG模式仅允许检索相关用户记忆数据,无画像模式作为基线对照。评估指标采用二元选择的准确率,对于生成式模型需设计特定提示引导其进行答案选择。该数据集特别适用于分析不同架构模型在个性化任务中的表现差异,如验证模型规模效应、检验增强推理能力对个性化的影响,以及评估检索增强框架在个性化场景中的有效性。
背景与挑战
背景概述
PersonaFeedback是由OPPO、中国电子科技大学、香港中文大学(深圳)及华南农业大学的研究团队于2025年6月推出的个性化大语言模型评测基准。该数据集包含8,298个人工标注的测试案例,旨在解决当前LLM领域缺乏高质量个性化能力评估工具的核心问题。通过将用户画像显式提供并与查询解耦,该数据集首次实现了对模型纯个性化响应能力的直接测量,填补了从隐式历史交互推断画像到显式个性化生成之间的研究空白。其分层难度设计(简单/中等/困难)和二元选择评估机制,为量化响应个性化程度提供了创新方法论,对推荐系统、智能助手等领域的个性化技术发展具有重要推动作用。
当前挑战
构建PersonaFeedback面临双重挑战:在领域问题层面,需解决个性化响应质量难以量化的问题——现有自动化评估方法(如LLM-as-a-judge)难以捕捉细微的个性化差异,且缺乏可解释性;在构建技术层面,既要确保1,700个用户画像的多样性与真实性(避免理想化或矛盾特征),又要处理个性化响应与通用回答之间的模糊边界(如中等难度案例中人类标注者一致性系数κ仅0.4-0.6)。实验表明,即使最先进的LLM在困难层级(需区分语义相近的个性化响应)的准确率显著下降,暴露出当前检索增强生成(RAG)框架在个性化任务中的局限性。
常用场景
经典使用场景
在自然语言处理领域,PersonaFeedback数据集为评估大型语言模型(LLMs)的个性化响应能力提供了标准化测试环境。该数据集通过预定义用户角色和查询,直接评估模型生成符合特定用户特征的响应能力,广泛应用于个性化对话系统、推荐系统和智能助手的开发与优化中。其独特的二元选择评估任务设计,使得研究人员能够精确量化模型在个性化任务上的表现差异。
衍生相关工作
PersonaFeedback催生了多个重要研究方向,包括基于显式角色学习的微调方法、个性化奖励模型构建,以及检索增强生成(RAG)系统的优化。相关经典工作如AI Persona提出的终身角色学习框架、LaMP基准的伪RAG技术,以及Zollo等人开发的PersonaLLM模型,均受该数据集启发。这些研究共同推动了用户建模与响应生成协同优化的理论发展。
数据集最近研究
最新研究方向
随着大语言模型(LLMs)通用能力的快速提升,个性化生成已成为人工智能交互领域的前沿研究方向。PersonaFeedback数据集的提出,填补了当前缺乏高质量个性化评估基准的空白,为研究社区提供了8298个人工标注的测试案例,涵盖易、中、难三个复杂度层级。该数据集通过解耦用户画像推断与个性化生成任务,聚焦于评估模型基于显式用户画像生成个性化响应的能力。近期研究表明,即使在复杂推理任务中表现优异的尖端LLMs,在面对PersonaFeedback中的困难案例时仍显不足,这揭示了当前检索增强生成(RAG)框架在个性化任务中的局限性。该数据集的发布不仅推动了对话系统个性化适配的研究,也为用户画像学习、奖励模型优化等方向提供了重要基准,对提升人机交互体验具有深远意义。
相关研究论文
- 1PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization中国电子科技大学, 香港中文大学(深圳), 华南农业大学, OPPO · 2025年
以上内容由遇见数据集搜集并总结生成


