MagicColor
收藏arXiv2025-03-21 更新2025-03-25 收录
下载链接:
https://yinhan-zhang.github.io/color
下载链接
链接失效反馈官方服务:
资源简介:
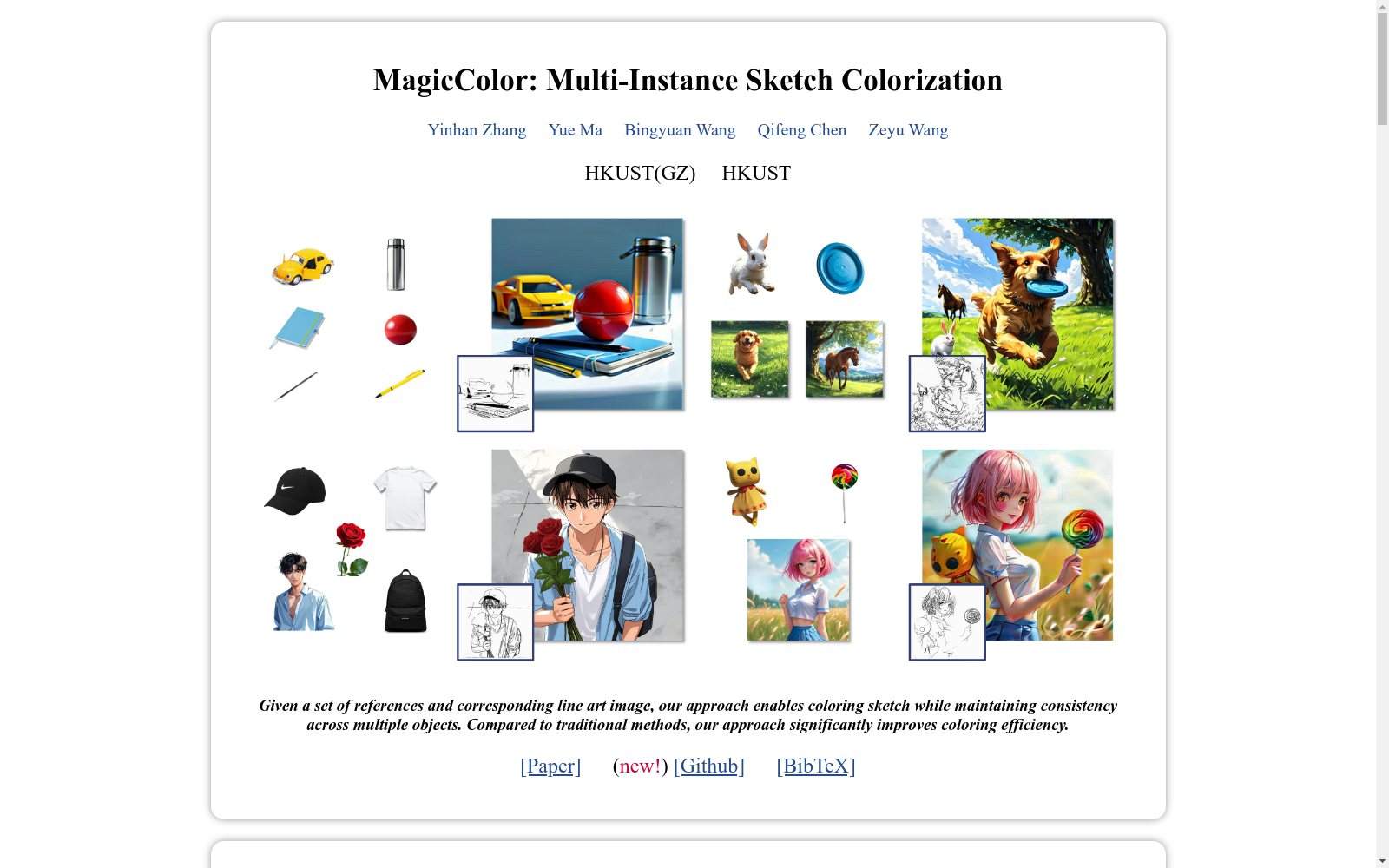
MagicColor数据集是由香港科技大学(广州)和香港科技大学的研究团队收集的,用于多实例草图着色的研究。该数据集支持将多个参考实例的颜色映射到相应的线艺术图像中,通过保持一致性来实现草图着色。数据集的创建是为了解决传统动画草图着色方法效率低下和准确性不足的问题。数据集的详细大小、数据量等信息在论文中未详细描述,其目的是支持动画内容创建的自动化流程,提高生产效率,减少劳动力需求,并满足日益增长的动画需求。
The MagicColor Dataset was collected by research teams from The Hong Kong University of Science and Technology (Guangzhou) and The Hong Kong University of Science and Technology for research on multi-instance sketch coloring. It supports mapping colors from multiple reference instances to corresponding line art images, realizing sketch coloring while preserving color consistency. This dataset was developed to tackle the shortcomings of low efficiency and inadequate accuracy in traditional animated sketch coloring approaches. Specific details including its overall size and data volume are not fully documented in the associated paper. Its intended purposes include supporting automated workflows for animated content creation, boosting production efficiency, reducing labor demands, and catering to the escalating demand for animation-related content.
提供机构:
香港科技大学(广州), 香港科技大学
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
MagicColor数据集的构建基于一种创新的自博弈训练策略,旨在解决多实例训练数据不足的问题。该数据集通过两阶段训练流程实现:首阶段采用单参考着色训练,从动画序列中随机采样帧作为风格参考,利用边缘损失函数学习基础颜色语义关系;次阶段引入多实例精炼,借助Segment Anything Model (SAM)分割实例并进行随机融合、缩放等操作,增强模型对单实例语义的感知能力。数据预处理环节从Sakuga和ATD-12K等动画资源中提取1000对测试样本,并保持原始宽高比进行512像素的标准化处理,通过水平翻转和亮度调整实现数据增强。
特点
该数据集的核心特性体现在三个方面:多实例协同控制能力通过实例引导器实现精确的逐对象着色,解决了传统方法中的颜色渗透问题;结构-内容双重监督机制结合边缘损失与颜色匹配技术,在保持线条结构完整性的同时实现亚像素级颜色对齐;跨域适应性支持从现实图像到动漫风格的参考转换,其双UNet框架配合DINOv2特征编码器,能有效处理参考图像与线稿间的几何差异。数据集的独特价值在于首次实现了单次前向传播中完成多实例线稿着色,定量评估显示其FID(28.443)和SSIM(0.805)指标显著优于现有方法。
使用方法
使用该数据集需遵循三步骤流程:输入阶段需准备线稿图像与1-N个参考实例,通过SAM模型自动生成实例掩膜;处理阶段由参考网络提取全局颜色语义,实例引导器解析局部特征,双UNet架构在潜在空间完成特征对齐;输出阶段应用像素级颜色匹配算法,基于余弦距离计算参考与目标特征的相似度,最终生成具有空间一致性的着色结果。对于复杂遮挡场景,建议采用分层输入策略,将不同深度物体分批次处理。数据集配套的推理管线支持PyTorch框架,需配置NVIDIA A800级GPU以实现最佳性能。
背景与挑战
背景概述
MagicColor是由香港科技大学(HKUST)的研究团队于2025年提出的一个基于扩散模型的多实例线稿着色框架,旨在解决传统动画产业中手动着色效率低下且一致性难以保证的问题。该数据集的核心研究问题是通过自动化流程实现多实例线稿的精准着色,同时保持跨实例的颜色一致性。MagicColor的提出标志着动画制作流程向高效化、自动化迈出了重要一步,对数字艺术和动画产业具有显著的实践意义。
当前挑战
MagicColor面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,传统线稿着色方法存在效率低下和一致性不足的问题,而现有生成方法难以处理多实例配对数据的稀缺性。构建过程中的挑战则包括多实例训练数据的缺乏、参考图像与目标线稿之间的结构对齐问题,以及如何在单次前向传播中实现精确的实例级颜色控制。这些挑战需要通过创新的技术设计,如自博弈训练策略和实例引导机制,来逐一克服。
常用场景
经典使用场景
在数字动漫产业中,MagicColor数据集被广泛应用于多实例线稿上色任务。传统方法需要艺术家逐个对每个实例进行手工上色,耗时且易出错。MagicColor通过扩散模型框架,实现了多实例线稿的自动上色,显著提升了上色效率和一致性。其经典使用场景包括动画系列中同一图像内多个相同对象的批量上色,以及复杂场景中多对象的语义一致性上色。
解决学术问题
MagicColor解决了动漫线稿上色领域的三个关键学术问题:一是通过自训练策略缓解了多实例配对数据稀缺的挑战;二是设计了实例引导机制,实现了细粒度的实例级颜色控制;三是引入边缘损失和颜色匹配技术,提升了颜色传递的精确性。这些创新使得模型在色度精度和视觉质量上超越了现有方法,为零手动调整的自动化上色流程奠定了基础。
衍生相关工作
基于MagicColor的技术路线,衍生出了多项重要工作。MangaNinja改进了参考注意力机制以实现更精确的局部上色控制;AnimeDiffusion将框架拓展至动漫人脸特定领域;ColorizeDiffusion则探索了文本标签与扩散模型的结合。这些工作共同推动了可控图像生成领域的发展,为数字艺术创作提供了新的技术范式。
以上内容由遇见数据集搜集并总结生成


