entheogen-updates
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/chaosste/entheogen-updates
下载链接
链接失效反馈官方服务:
资源简介:
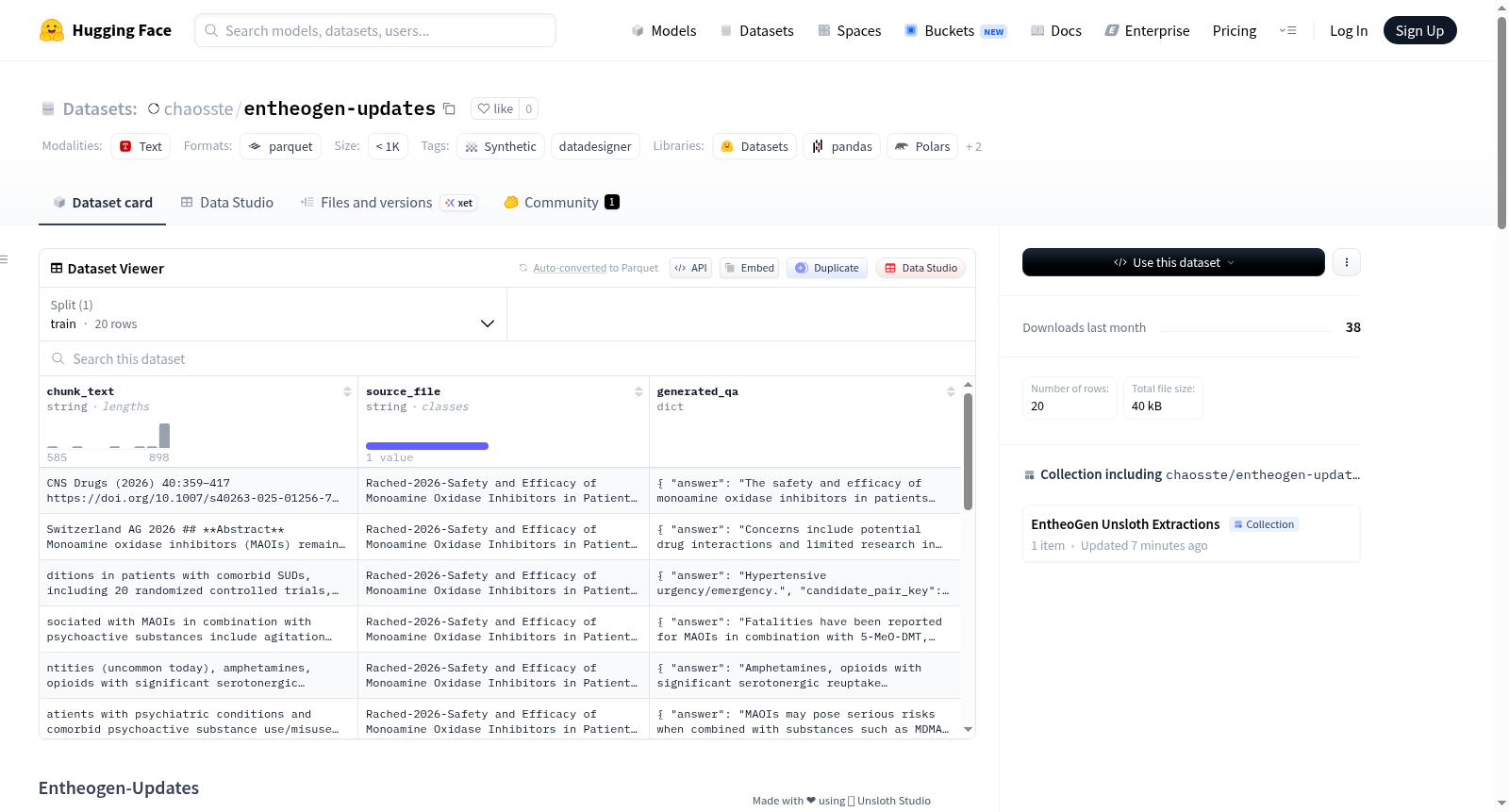
Entheogen-Updates数据集是通过Unsloth Recipe Studio生成的合成数据集,包含20条记录和3个字段。核心字段为generated_qa,其类型为字典(dict),具有80%的唯一值和0%的空值率,输入输出令牌数分别为623和154。该数据集采用NeMo Data Designer框架生成,该框架支持通过统计采样器、LLMs或现有种子数据集生成多样化数据,并提供字段间关系控制、质量验证(包括Python、SQL和自定义验证器)以及LLM评分评估等功能。数据集适用于需要高质量合成数据的场景,特别是药代动力学和药效学药物相互作用研究领域。使用示例展示了如何通过HuggingFace datasets库加载数据并转换为pandas DataFrame。
The Entheogen-Updates dataset is a synthetic dataset generated via Unsloth Recipe Studio, containing 20 records and 3 fields. The core field is generated_qa, which is of dictionary (dict) type, with 80% uniqueness and 0% null value rate, and input/output token counts of 623 and 154 respectively. The dataset is generated using the NeMo Data Designer framework, which supports diverse data generation through statistical samplers, LLMs, or existing seed datasets, and provides control over field relationships, quality validation (including Python, SQL, and custom validators), and LLM scoring evaluation. It is suitable for scenarios requiring high-quality synthetic data, particularly in the fields of pharmacokinetics and pharmacodynamics drug interaction studies. Usage examples demonstrate how to load the data via the HuggingFace datasets library and convert it into a pandas DataFrame.
创建时间:
2026-05-06
原始信息汇总
数据集概述
- 数据集名称: Entheogen-Updates
- 数据集地址: https://huggingface.co/datasets/chaosste/entheogen-updates
- 数据规模: 少于1000条记录(n<1K),实际包含20条记录
- 数据格式: Parquet 文件(位于
data/*.parquet) - 配置: 默认配置名为
data
数据集内容
- 记录数: 20
- 列数: 3
- 主要字段:
generated_qa(字典类型,LLM结构化字段):唯一值占比80%,无缺失值,输入令牌数623,输出令牌数154
数据生成详情
- 生成工具: 使用 Unsloth Recipe Studio 生成
- 生成配置: 包含3列配置
- 1列 LLM结构化字段
- 2列种子数据集字段
- 完整配置及元数据: 可在
builder_config.json和metadata.json中查看
引用信息
若使用本数据集,请引用:
bibtex @misc{nemo-data-designer, author = {The NeMo Data Designer Team, NVIDIA}, title = {NeMo Data Designer: A framework for generating synthetic data from scratch or based on your own seed data}, howpublished = {url{https://github.com/NVIDIA-NeMo/DataDesigner}}, year = 2026, note = {GitHub Repository}, }
搜集汇总
数据集介绍
构建方式
Entheogen-Updates数据集由NVIDIA NeMo Data Designer框架生成,重点聚焦于药代动力学与药效学药物相互作用的洞察及临床管理。该数据集基于一篇以Ken-2024为标识的学术文献作为种子数据,通过同步采用llm-structured配置与seed-dataset配置,最终生成了20条高度结构化的记录。每条记录包含一个由大语言模型生成的问答对,共设3个数据列,整体数据以Parquet格式存储,便于高效加载与处理。
特点
该数据集以简洁精炼著称,仅包含20条记录和3个数据列,但其核心列generated_qa属于llm-structured类型,大模型在此构建了结构化的问答内容。80%的条目具备唯一性,且无缺失值,体现了生成过程的高质量与多样性。数据集由3种配置协同生成,其中llm-structured占1列,seed-dataset占2列,确保了内容既源自真实文献背景,又通过合成技术实现领域知识的扩展与深化。
使用方法
便捷高效的加载方式是其使用的核心优势。用户可以通过HuggingFace的datasets库,使用load_dataset函数直接调用chaosste/entheogen-updates数据集,并指定data配置项和train分割即可获取完整数据。随后可借助to_pandas方法将数据集转换为Pandas DataFrame格式,便于后续的数据分析、模型训练或临床研究中的知识检索与问答系统开发。
背景与挑战
背景概述
Entheogen-Updates是一个由NVIDIA NeMo数据设计师团队于2026年运用Unsloth Recipe Studio框架生成的合成数据集,专注于药代动力学与药效学(PK/PD)药物相互作用领域,旨在探索临床管理中的关键见解。该数据集由研究者“Ken-2024”主导构建,核心研究问题聚焦于系统化梳理药物相互作用的复杂机制,为临床决策提供结构化知识库。虽然仅包含20条记录,但其采用先进的合成数据生成技术,体现了从零或种子数据出发构建高质量医学数据的可行性。作为NVIDIA生态系统的产物,该数据集推动了合成数据在生物医学领域的应用,为数据稀缺场景下的模型训练和知识发现提供了新范式。
当前挑战
该数据集面临的首要挑战在于解决药代动力学与药效学相互作用这一高度复杂的领域问题,涉及多药物间非线性动力学、遗传多态性及个体差异等因素,传统临床研究难以穷尽所有交互场景。构建过程中,合成数据需精准模拟真实世界的药理学关系,确保生成问答对(generated_qa)的医学准确性,避免引入偏差或虚假关联。此外,仅20条记录的极小规模限制了统计效度和泛化能力,且依赖llm-structured列架构的单一生成方式,可能难以覆盖药物相互作用的多样性。如何验证合成数据的临床相关性,并在有限样本下平衡真实性与可用性,成为核心挑战。
常用场景
经典使用场景
在药物相互作用研究的广阔领域中,精确模拟与探索致幻类化合物的药代动力学与药效学交互机制始终是前沿课题。entheogen-updates数据集凭借其结构化的生成式问答记录,为研究者提供了一个微型的知识推理与检索基准。其经典使用方式在于,研究人员可将该数据集作为小样本学习或少样本提示的语料库,用于训练或微调大型语言模型,使其能够准确理解并回答关于致幻剂药物相互作用的临床管理、代谢途径及调控策略等专业问题。该数据集在验证合成数据在狭窄生物医学主题上对模型推理能力的提升效果方面扮演了关键角色。
解决学术问题
该数据集针对生物医学自然语言处理领域中长期存在的领域知识稀疏与高质量标注语料匮乏的困境,提供了解决方案。通过聚焦于致幻剂这一高度专业化且研究资料相对分散的亚领域,entheogen-updates有效缓解了通用语料在回答精准药理交互问题时的知识盲区。它使得学术界能够探索如何利用合成数据来弥合从药理学文献到临床决策支持之间的语义鸿沟,推动了面向小众医学领域的问答系统与知识图谱构建技术的发展,为评估生成数据在专业约束下的可靠性与效能设立了参照。
衍生相关工作
围绕该数据集催生了一系列探索性研究,其中最具代表性的工作包括基于其生成框架对更广义药代动力学交互语料的扩展,利用NeMo Data Designer的依赖感知生成机制创建了覆盖不同给药方案与代谢类型的多版本衍生集。相关学者据此开展了关于合成数据质量验证方法的对比实验,提出了利用LLM-as-a-judge与内置Python验证器对生成文本药理一致性的双重评分范式。这些工作进一步启发了将小规模高专业度种子数据集与结构化采样器相结合的混合生成策略,为未来在麻醉学、毒理学等紧密关联领域构建类似数据集奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


