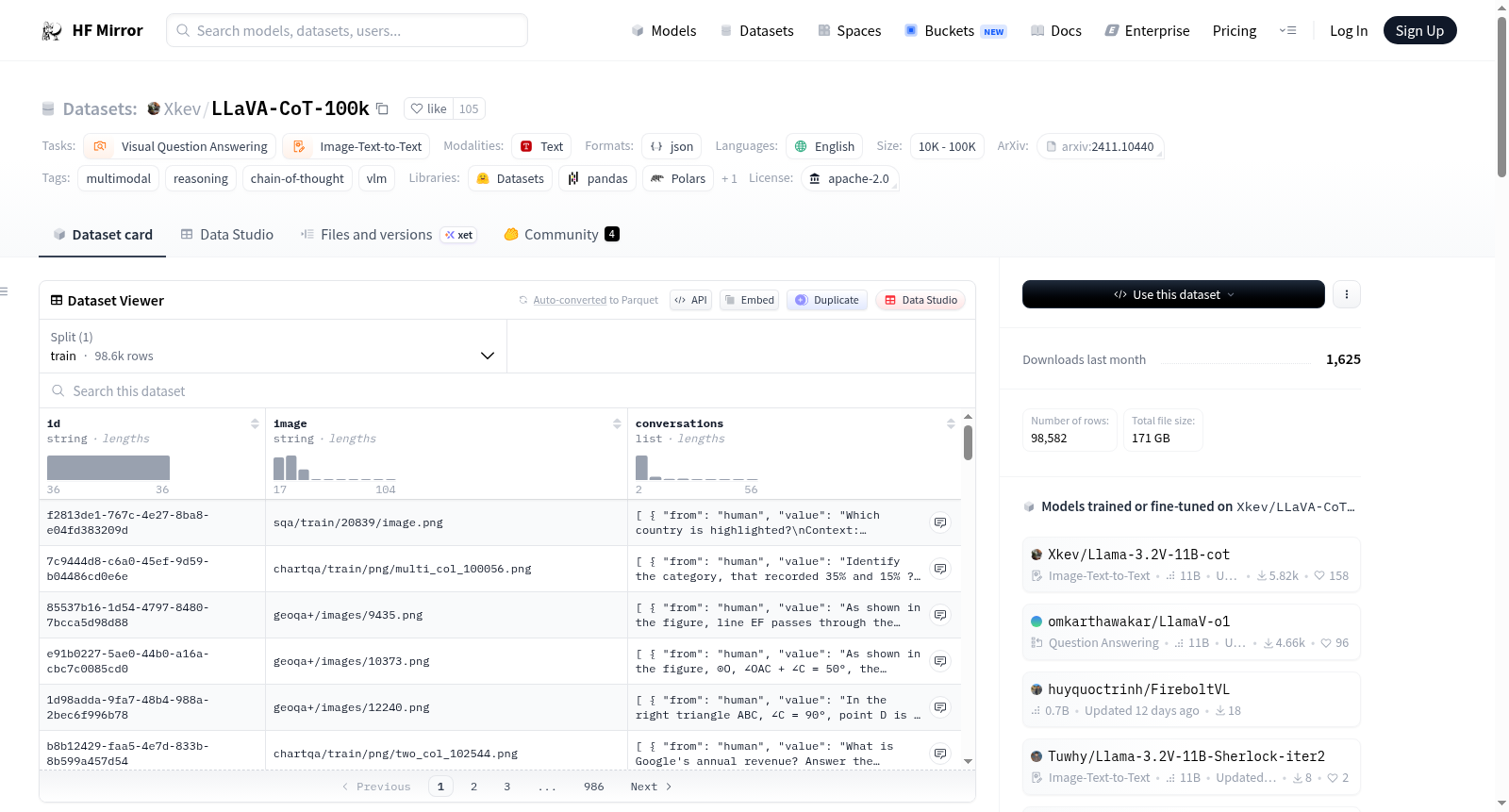
Xkev/LLaVA-CoT-100k
收藏Hugging Face2024-11-27 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/Xkev/LLaVA-CoT-100k
下载链接
链接失效反馈官方服务:
资源简介:
LLaVA-CoT数据集是一个用于视觉问答任务的数据集,包含来自多个开源数据集的图像和问题,并使用GPT-4o生成结构化答案。数据集的结构包括需要手动合并的图像文件和包含问答数据的train.jsonl文件。数据集的创建过程涉及从ShareGPT4V、ChartQA、A-OKVQA、AI2D、GeoQA+、ScienceQA、DocVQA、PISC、CLEVR和CLEVR-Math等数据集中提取图像和问题,并使用GPT-4o生成答案。尽管努力确保多样性,但仍可能存在一些偏见。
LLaVA-CoT is a dataset for the Visual Question Answering (VQA) task, containing approximately 10K to 100K samples. The dataset includes image files and corresponding question-answering data, with the image files needing to be manually merged and then unzipped. The question-answering data is stored in JSONL format, containing questions and answers generated by GPT-4o. The creation of the dataset utilized images and questions from multiple open-source datasets and used GPT-4o to generate structured answers.
提供机构:
Xkev
搜集汇总
数据集介绍
构建方式
LLaVA-CoT-100k数据集源自多源视觉问答数据,融合了ShareGPT4V、ChartQA、A-OKVQA等通用VQA数据集以及AI2D、GeoQA+、ScienceQA等科学导向VQA数据集,共计约10万样本。为赋予视觉语言模型自主多阶段推理能力,研究团队利用GPT-4o对原始问答对进行结构化推理标注,生成包含逐步思考链的答案。数据构建流程通过开源脚本实现,确保答案的推理逻辑清晰且可复现,最终以JSON格式存储,每条记录包含唯一标识、图像路径及多轮对话内容。
特点
该数据集的核心特点在于其结构化推理标注,每个问答对中的答案并非直接输出,而是包含从问题分析到最终结论的完整推理链条,涵盖观察、分析、推理等多个阶段。数据来源兼具通用性与专业性,既有日常视觉问答样本,也有科学图表与数学推理任务,覆盖广泛场景。此外,数据集规模适中(约10万条),兼顾了训练效率与推理多样性,为视觉语言模型在复杂多模态任务中的系统性思考提供了高质量训练资源。
使用方法
用户可通过Hugging Face Datasets库直接加载数据集,使用`load_dataset("Xkev/LLaVA-CoT-100k")`获取训练集。图像文件需手动合并压缩包并解压至本地。模型推理可沿用Llama-3.2-11B-Vision-Instruct的标准加载流程,并参考GitHub仓库中的SWIRES搜索策略进行测试。微调时需使用提供的`llama-recipes`脚本,修改`cot_dataset.py`中的数据和图像路径,通过`torchrun`启动分布式训练,设置学习率、批次大小等超参数以复现论文结果。
背景与挑战
背景概述
在视觉语言模型(VLM)领域,尽管多模态理解取得了显著进展,但模型在面对复杂视觉问答任务时,往往缺乏系统化、结构化的推理能力,难以实现类似人类思维的逐步分析过程。为弥补这一短板,北京大学袁粒团队联合多位研究者于2024年推出了LLaVA-CoT-100k数据集。该数据集旨在赋予VLM自主多阶段推理的能力,通过整合来自ShareGPT4V、ChartQA、ScienceQA等多个公开数据源的视觉问答样本,并引入GPT-4o生成的结构化推理标注,构建了一个规模逾十万条的高质量训练集。LLaVA-CoT-100k的发布,为提升多模态模型在科学、图表及一般视觉场景中的逻辑推理水平提供了关键数据支撑,推动了VLM从简单感知向深度认知的跨越。
当前挑战
当前视觉语言模型在复杂视觉问答中面临的核心挑战在于,它们难以自发地分解问题并进行多步逻辑推导,常因跳跃式回答而忽略关键中间证据。LLaVA-CoT-100k数据集致力于解决这一领域难题,通过提供包含逐步推理链的标注,引导模型学习从观察到结论的完整推理路径。在数据集构建过程中,挑战同样显著:首先,需从多个异构数据源(如通用VQA与科学类VQA)中统一格式并保证样本质量;其次,依赖GPT-4o自动生成结构化答案时,需平衡自动化效率与推理正确性,避免引入偏见或逻辑漏洞;此外,图像与文本的跨模态对齐以及大规模数据清洗,也对构建流程的鲁棒性提出了较高要求。
常用场景
经典使用场景
LLaVA-CoT-100k数据集最经典的使用场景在于为视觉语言模型(VLM)提供结构化、多阶段的推理训练数据。该数据集整合了来自ShareGPT4V、ChartQA、AI2D等多个开源视觉问答源的样本,并利用GPT-4o生成包含逐步推理链的答案,从而引导模型学习从感知到认知的完整推理过程。研究者通常将其作为微调基座模型(如Llama-3.2-11B-Vision-Instruct)的核心数据,使VLM能够自主执行分阶段推理,显著提升在复杂视觉问答任务中的表现。
实际应用
在实际应用中,LLaVA-CoT-100k微调后的模型可部署于需要精确视觉理解的场景,例如教育领域的自动解题系统(如科学试题解析)、智能文档分析工具(如财务报告表格理解)、医疗影像辅助诊断(如X光片问答)以及工业质检中的缺陷识别。由于其具备分步推理能力,模型能够给出可解释的推理过程,在需要透明决策的领域(如法律证据分析或科研数据验证)具有独特价值。此外,该数据集还可用于开发面向视障人士的智能助手,通过逐步描述视觉内容来提供更安全的导航或操作指导。
衍生相关工作
该数据集衍生了一系列重要的后续研究,包括基于逐步推理的视觉问答模型优化(如SWIRES搜索策略)、多模态链式思维蒸馏方法,以及面向特定领域(如医学或工程图纸)的推理数据集构建。相关经典工作包括LLaVA系列模型的迭代改进、将CoT推理与视觉编码器联合训练的研究,以及利用对比学习增强推理步骤一致性的方法。此外,该数据集还催生了关于VLM推理可解释性评估基准的讨论,推动了如VLM-ReasonBench等评测体系的建立,为衡量模型在结构化推理任务上的真实能力提供了标准化工具。
以上内容由遇见数据集搜集并总结生成


