MINT-1T 文本图像对多模态数据集
收藏超神经2024-11-13 更新2024-12-14 收录
下载链接:
https://hyper.ai/cn/datasets/35739
下载链接
链接失效反馈官方服务:
资源简介:
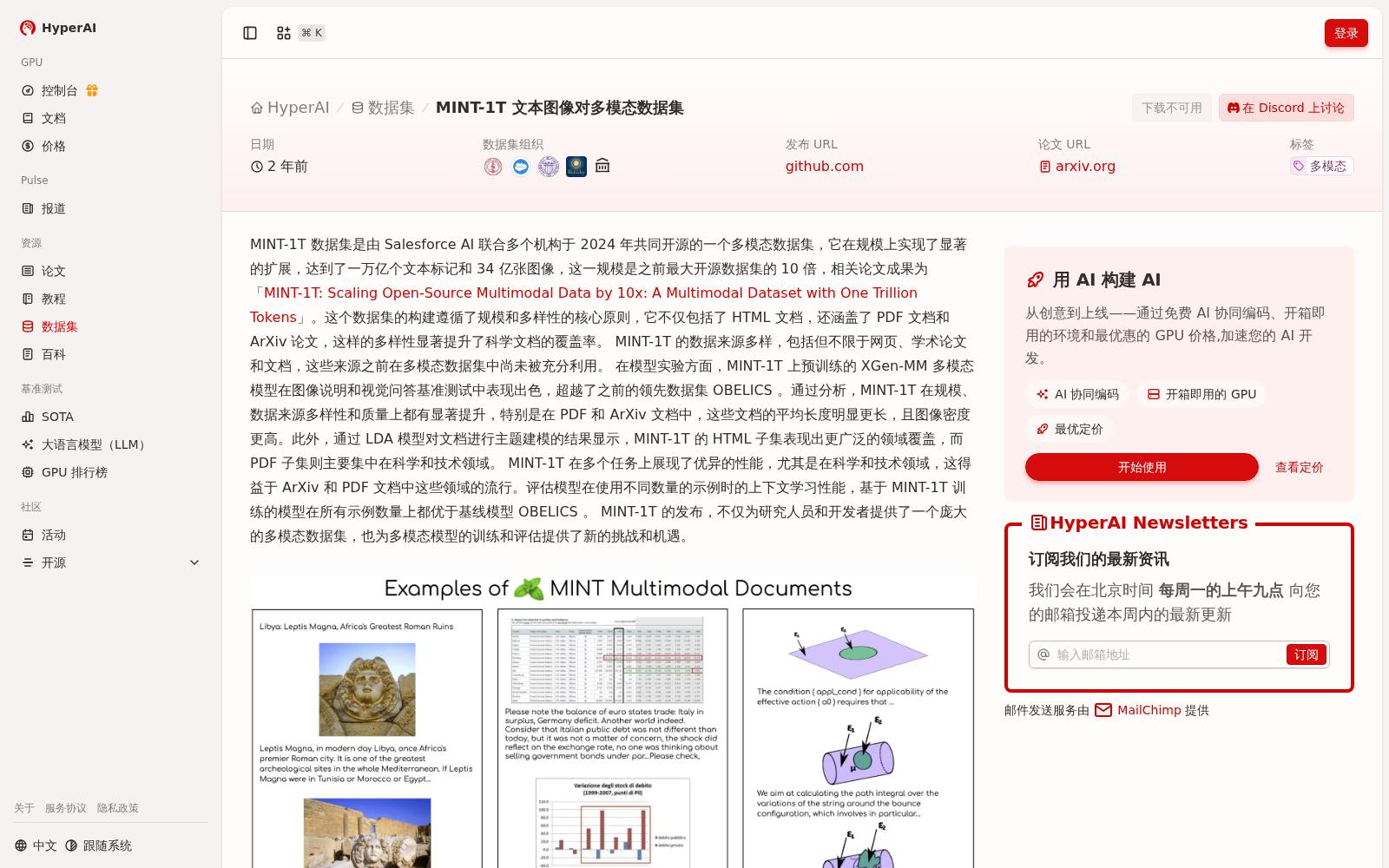
MINT-1T 数据集是由 Salesforce AI 联合多个机构于 2024 年共同开源的一个多模态数据集,它在规模上实现了显著的扩展,达到了一万亿个文本标记和 34 亿张图像,这一规模是之前最大开源数据集的 10 倍,相关论文成果为「MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens」。这个数据集的构建遵循了规模和多样性的核心原则,它不仅包括了 HTML 文档,还涵盖了 PDF 文档和 ArXiv 论文,这样的多样性显著提升了科学文档的覆盖率。 MINT-1T 的数据来源多样,包括但不限于网页、学术论文和文档,这些来源之前在多模态数据集中尚未被充分利用。
The MINT-1T dataset is an open-source multimodal dataset jointly released by Salesforce AI and multiple institutions in 2024. It has achieved substantial scaling in scale, reaching 1 trillion text tokens and 3.4 billion images, which is 10 times the size of the largest prior open-source dataset. The corresponding academic paper is titled "MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens". The construction of the MINT-1T dataset follows the core principles of scale and diversity. It covers not only HTML documents, but also PDF documents and ArXiv papers, which significantly improves the coverage of scientific documents. The data sources of MINT-1T are diverse, including but not limited to web pages, academic papers and documents, and these sources have not been fully utilized in previous multimodal datasets.
创建时间:
2024-11-13
搜集汇总
数据集介绍
背景与挑战
背景概述
MINT-1T是由Salesforce AI等机构于2024年开源的大规模多模态数据集,包含一万亿文本标记和34亿张图像,规模是之前最大开源数据集的10倍。它整合了网页、PDF和ArXiv文档等多种来源,显著提升了科学文档覆盖率,并基于此训练的模型在图像说明和视觉问答任务中超越了现有基线。
以上内容由遇见数据集搜集并总结生成


