JobHop
收藏arXiv2025-05-12 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/aida-ugent/JobHop
下载链接
链接失效反馈官方服务:
资源简介:
JobHop数据集由根特大学的研究团队创建,是一个大规模的公共数据集,源自比利时弗拉芒地区公共就业服务机构VDAB提供的匿名简历。该数据集包含超过2.3百万个工作经历,来自391,000多个用户简历,并映射到标准化的ESCO职业代码。使用LLMs技术从非结构化简历数据中提取结构化职业信息,并通过多标签分类模型映射到ESCO代码。数据集支持多样化的应用,如分析劳动力市场流动性、工作稳定性以及职业中断对职业转换的影响。此外,它还支持职业路径预测和其他数据驱动决策过程。数据集通过分析弗拉芒劳动市场的关键特征,如工作分布、职业中断和工作转换,展示了其在推动劳动力市场研究方面的价值。
The JobHop dataset, created by a research team at Ghent University, is a large-scale public dataset sourced from anonymized resumes provided by VDAB, the public employment service of the Flemish region of Belgium. This dataset contains over 2.3 million work experiences from more than 391,000 user resumes, and has been mapped to standardized ESCO occupational codes. Structured occupational information is extracted from unstructured resume data using large language models (LLMs), and mapped to ESCO codes via a multi-label classification model. The dataset supports a diverse range of applications, including analyses of labor market mobility, job stability, and the impact of career interruptions on job transitions. In addition, it also supports career path prediction and other data-driven decision-making processes. By analyzing key features of the Flemish labor market such as job distribution, career interruptions and job transitions, the dataset demonstrates its value in advancing labor market research.
提供机构:
根特大学
创建时间:
2025-05-12
原始信息汇总
数据集概述:JobHop
基本信息
- 许可证: CC BY 4.0
- 语言: 英语 (en)
- 标签: labor_market, ESCO, Job_transition
- 数据规模: 1M < n < 10M
数据集描述
- 数据来源: 来自比利时弗拉芒公共就业服务机构VDAB提供的超过40万份匿名简历。
- 创建方法:
- 使用小型语言模型(LLM)从简历中提取信息。
- 使用Nobl.ai提供的专有工具将每段工作经历映射到对应的ESCO代码。
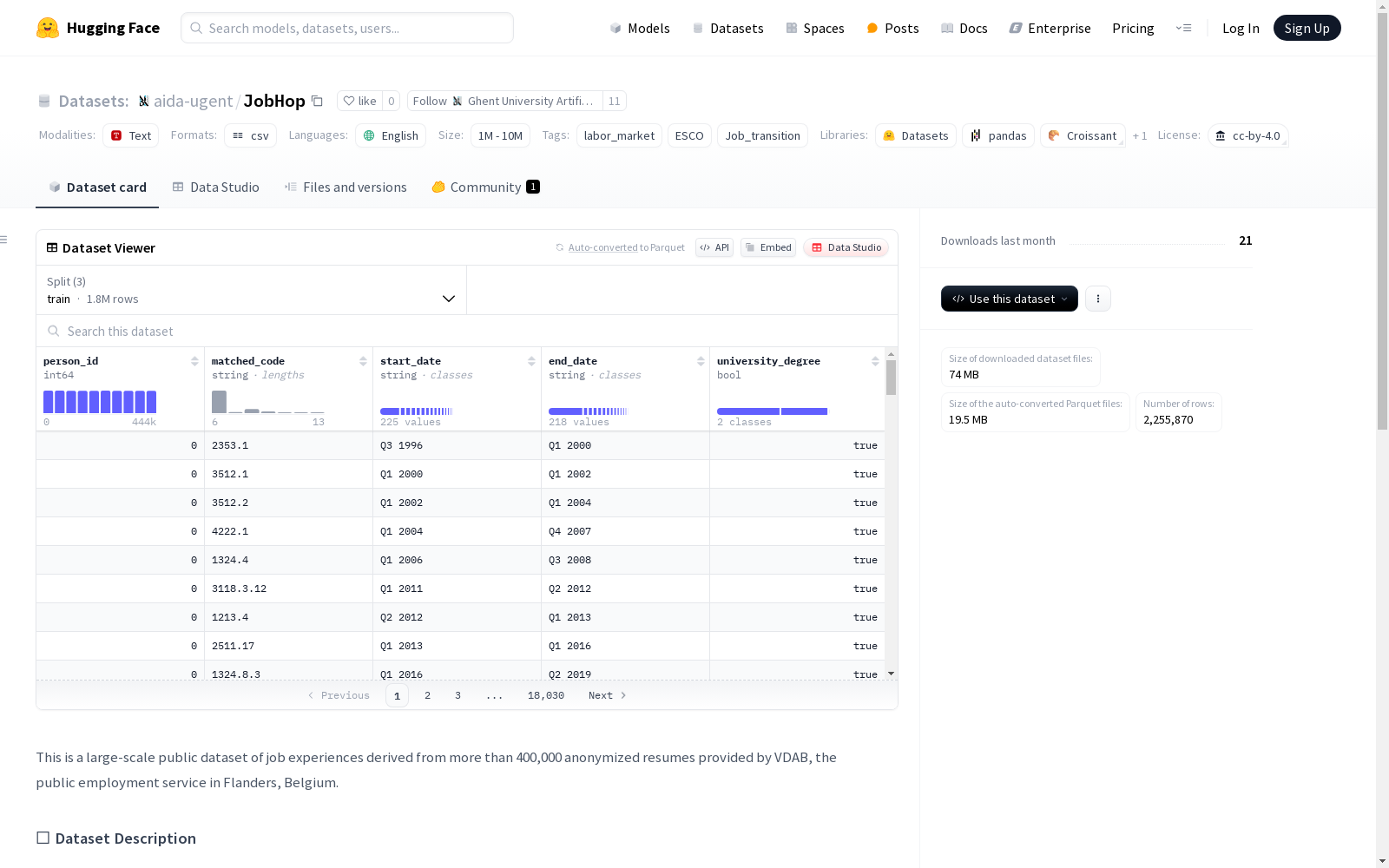
- 包含字段:
- person_id: 标识该行数据所属的简历
- esco_code: 匹配的ESCO代码
- start_date, end_date: 工作经历的起止日期
- university_degree: 个人是否拥有大学学位的标志
作者与资助信息
- 作者: Iman Johary, Raphael Romero, Alexandru-Cristian Mara, Tijl De Bie
- 资助方:
- 根特大学BOF (BOF20/IBF/117)
- 弗拉芒政府 (AI Research Program)
- FWO (11J2322N, G0F9816N, 3G042220, G073924N)
- ERC grant (VIGILIA, 101142229)
引用与许可
- 引用信息: 即将添加
- 许可证: CC BY 4.0
联系方式
- 通讯作者: iman.johary@ugent.be
搜集汇总
数据集介绍
构建方式
JobHop数据集通过处理比利时弗拉芒公共就业服务机构VDAB提供的匿名简历构建而成。利用大型语言模型(LLMs)处理非结构化的简历数据,提取结构化的职业信息,并通过多标签分类模型将其映射到标准化的ESCO职业代码。这一过程涉及从391,000多份用户简历中提取并分组超过230万条工作经历,最终形成一个丰富的职业轨迹数据集。数据集的构建还包括严格的匿名化处理,以确保个人隐私的保护。
特点
JobHop数据集的核心特点在于其大规模和标准化。数据集包含超过230万条工作经历,映射到ESCO职业代码,为研究职业流动性、工作稳定性以及职业中断对职业转换的影响提供了丰富资源。数据集的多语言特性(主要为荷兰语、英语和法语)和覆盖广泛的职业类别,使其成为劳动力市场研究的宝贵工具。此外,数据集的标准化ESCO分类便于国际比较和与其他劳动力市场数据源的整合。
使用方法
JobHop数据集适用于多种劳动力市场分析和职业路径预测应用。研究人员可以利用该数据集分析职业流动性模式、评估不同行业的工作稳定性,或研究教育和职业中断对职业轨迹的影响。数据集的结构化格式和标准化职业代码使其易于集成到机器学习模型中,用于职业路径预测或技能差距分析。此外,政策制定者可以利用该数据集进行劳动力市场趋势分析,以支持数据驱动的政策制定。
背景与挑战
背景概述
JobHop数据集由比利时根特大学的研究团队于2025年创建,旨在解决劳动力市场动态分析中真实职业轨迹数据稀缺的核心问题。该数据集基于佛兰德斯大区公共就业服务局VDAB提供的匿名简历数据,利用大语言模型技术提取了超过230万条标准化ESCO职业编码的工作经历,覆盖39.1万份简历。作为首个大规模公开的职业轨迹数据集,其创新性地将非结构化简历信息转化为可计算的职业过渡矩阵,为研究职业流动性、工作稳定性及教育背景对职业发展的影响提供了重要基础。该数据集显著推动了劳动经济学、人力资源管理和社会政策等领域的量化研究。
当前挑战
JobHop数据集面临的核心挑战存在于两个维度:在领域问题层面,劳动力市场分析长期受限于职业分类标准不统一、跨区域数据不可比、个体层面长期追踪数据缺失等问题,而该数据集通过ESCO标准化分类体系部分解决了这一难题;在构建过程层面,研究团队需要克服简历文本非结构化程度高、多语言混杂、隐私保护要求严格等技术障碍,特别是采用LLMs进行信息提取时面临语义歧义消除、时间信息标准化、跨职业分类映射等具体挑战。此外,数据匿名化处理导致部分关键信息丢失,也为后续分析带来了数据完整性方面的挑战。
常用场景
经典使用场景
JobHop数据集在劳动力市场分析领域具有广泛的应用价值。该数据集通过标准化ESCO职业编码,为研究人员提供了分析职业流动性和职业稳定性的独特视角。在学术研究中,该数据集常被用于构建职业转换网络,揭示不同职业群体之间的流动规律。例如,研究人员可以利用该数据集分析职业中断对后续就业的影响,或者探究教育背景与职业发展路径之间的关联。
解决学术问题
JobHop数据集有效解决了劳动力市场研究中数据稀缺的核心问题。传统上,研究人员只能依赖小样本调查数据或非公开的专有数据集,这严重限制了研究的广度和深度。该数据集通过提供超过230万条标准化的工作经历记录,使得研究职业转换模式、评估教育投资回报率、分析职业中断影响等关键问题成为可能。特别是其采用ESCO分类体系,为跨国比较研究提供了统一框架。
衍生相关工作
JobHop数据集已经催生了一系列相关研究。在职业路径预测领域,有研究团队基于该数据集开发了深度学习方法,用于预测个体的下一职业选择。在技能差距分析方面,研究人员结合ESCO分类体系,构建了职业技能需求变化监测模型。此外,该数据集还被用于验证新型的大型语言模型在职业信息提取任务中的性能,推动了NLP技术在劳动力市场分析中的应用。
以上内容由遇见数据集搜集并总结生成


