pre_test
收藏Hugging Face2026-05-21 更新2026-05-22 收录
下载链接:
https://huggingface.co/datasets/TheFinAI/pre_test
下载链接
链接失效反馈官方服务:
资源简介:
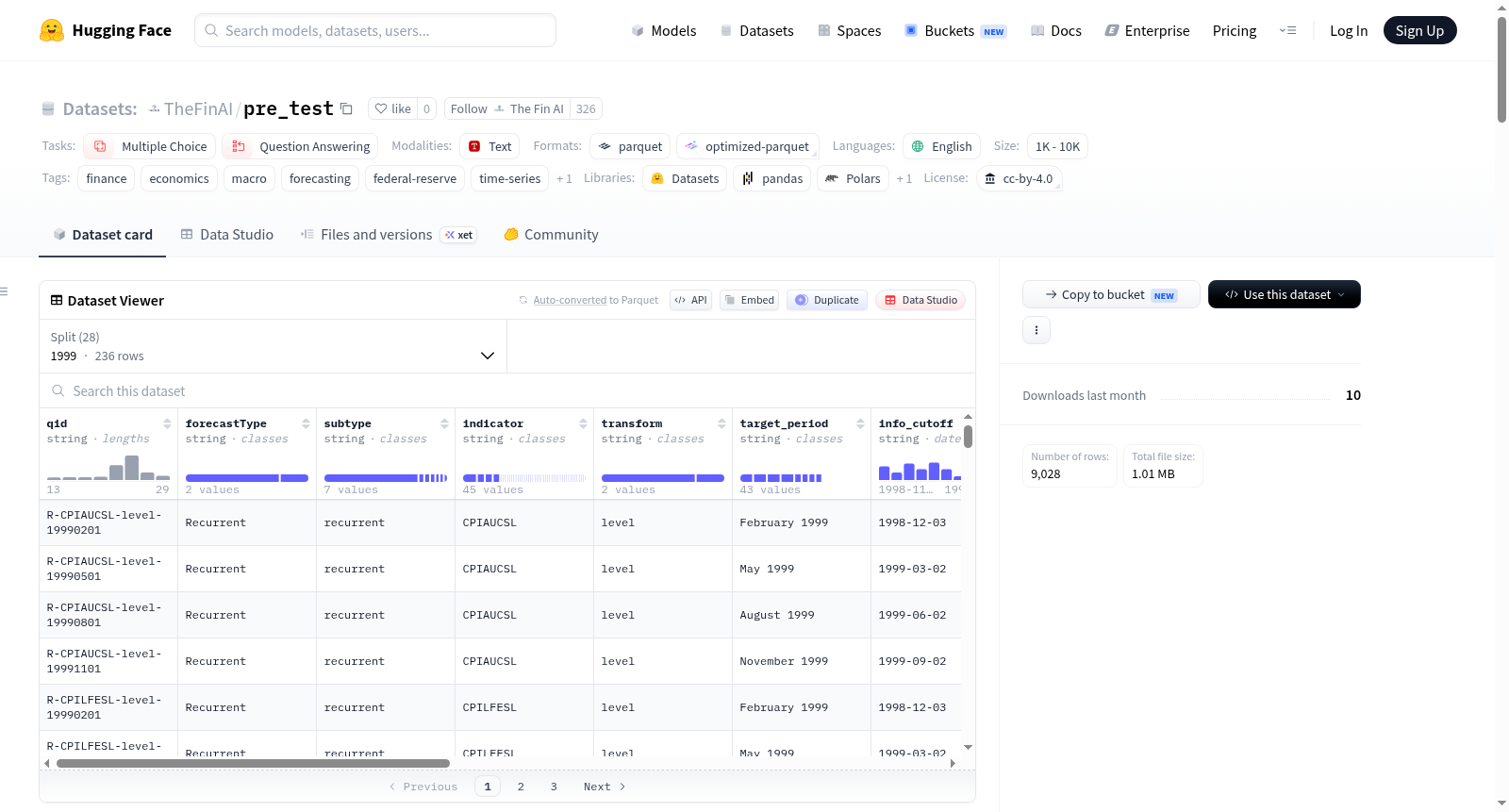
FinDeepForecast-Historical-US 是 OpenFinArena 的 FinDeepForecast 实时金融预测基准的历史版本数据集。该数据集覆盖 1999 年至 2026 年,共包含 8,437 个预测问题,其基准真值来源于真实的美国联邦储备经济数据(FRED)时间序列,专为可重复的离线评估而设计。数据集严格遵循原论文的双轨分类法:第一类是周期性预测(Recurrent),涉及对未来特定日期宏观经济指标(如CPI、GDP、国债收益率等)数值的预测,以4选项多项选择题形式呈现,共6,366题(占75.5%);第二类是非周期性预测(Non-Recurrent),针对即将发生的特定预定事件(如FOMC利率决策、CPI/NFP数据发布是否超预期、市场周度阈值等)进行二元(YES/NO)判断,共2,071题(占24.5%)。数据按年份划分为28个独立分片,每年约含300个问题。数据集共涵盖49个美国关键宏观经济与市场指标,分为通胀、劳动力、增长、利率、货币、消费、住房、制造业和市场等九大类。每个样本包含15个结构化字段,如唯一问题ID(qid)、预测类型(forecastType)、细分子类型(subtype)、FRED指标代码(indicator)、目标时期(target_period)、信息截止日期(info_cutoff)、问题文本(question)、选项列表(options)以及答案(answer_letter, answer_raw)等。该数据集适用于多项选择与问答任务,旨在为评估大语言模型及其他模型在金融时间序列预测和宏观经济事件判断方面的能力提供大规模、高质量的基准。与原始实时基准相比,本历史版本牺牲了无法记忆的实时特性,但提供了长达28年的回溯测试能力,且仅聚焦于美国宏观市场。
FinDeepForecast-Historical-US is the historical version dataset of OpenFinArenas FinDeepForecast real-time financial forecasting benchmark. It covers the period from 1999 to 2026 and contains 8,437 forecasting questions, with ground truth derived from real US Federal Reserve Economic Data (FRED) time series, designed for reproducible offline evaluation. The dataset strictly follows the original papers dual-track taxonomy: the first category is Recurrent forecasting, involving predictions of future values for specific macroeconomic indicators (e.g., CPI, GDP, Treasury yields) on specific dates, presented as 4-option multiple-choice questions, totaling 6,366 questions (75.5%); the second category is Non-Recurrent forecasting, focusing on binary (YES/NO) judgments about upcoming scheduled events (e.g., FOMC rate decisions, whether CPI/NFP data releases exceed expectations, weekly market thresholds), totaling 2,071 questions (24.5%). The data is divided into 28 independent yearly shards, with approximately 300 questions per year. The dataset encompasses 49 key US macroeconomic and market indicators, categorized into nine groups: inflation, labor, growth, interest rates, money, consumption, housing, manufacturing, and market. Each sample includes 15 structured fields, such as unique question ID (qid), forecast type (forecastType), subtype, FRED indicator code (indicator), target period (target_period), information cutoff date (info_cutoff), question text (question), options list (options), and answers (answer_letter, answer_raw). This dataset is suitable for multiple-choice and question-answering tasks, aiming to provide a large-scale, high-quality benchmark for evaluating the capabilities of large language models and other models in financial time series forecasting and macroeconomic event judgment. Compared to the original real-time benchmark, this historical version sacrifices the unmemorable real-time feature but offers 28 years of backtesting capability and focuses solely on the US macro market.
提供机构:
The Fin AI
创建时间:
2026-05-21
原始信息汇总
数据集概述:FinDeepForecast-Historical-US
该数据集是 FinDeepForecast 基准测试的历史版本,来源于 OpenFinArena。它覆盖了 1999 年至 2026 年的金融预测数据,共包含 8,437 个问题,其真实答案源自真实的 FRED 时间序列数据。
核心特性
| 特性 | 数值 |
|---|---|
| 总问题数 | 8,437 |
| 周期性预测问题 | 6,366(75.5%)— 4选1多选题 |
| 非周期性预测问题 | 2,071(24.5%)— 二分类(是/否) |
| 时间跨度 | 1999–2026(28个年度数据分片) |
| 经济指标 | 来自 FRED 的 49 个美国宏观/市场指标 |
| 年平均问题数 | 约 300 个 |
任务类型与格式
数据集严格遵循论文的“双轨”分类法:
- 周期性预测任务:关于未来日期的周期性数值预测(例如:CPI、GDP、国债收益率等)。
- 格式:4选1单选题,选项为具体数值。
- 示例:预测“美国CPI同比通胀率”在2010年6月的数值。
- 非周期性预测任务:关于特定即将发生事件的二分类(是/否)预测(例如:FOMC利率决议、CPI/NFP发布惊喜、每周市场阈值)。
- 格式:二选一(A) YES / B) NO)。
- 包含8种模板:如FOMC降息/加息/维持不变、CPI/NFP/GDP发布阈值、VIX/纳斯达克周度阈值等。
数据集字段说明
| 字段名 | 数据类型 | 描述 |
|---|---|---|
qid |
string | 唯一问题ID |
forecastType |
string | Recurrent 或 Non-Recurrent |
subtype |
string | 细分子类型 |
indicator |
string | 主要 FRED 系列 ID |
transform |
string | level / yoy_pct / yoy_pp(周期性)或 ""(非周期性) |
target_period |
string | 询问的目标时期 |
info_cutoff |
string | 信息截止日期(YYYY-MM-DD) |
forecast_end |
string | 预测期最后一天(YYYY-MM-DD) |
answer_release |
string | 非周期性任务:答案可验证的日期 |
question |
string | 问题文本 |
options |
list[string] | 选项列表(周期性问题为4项,非周期为2项) |
answer_letter |
string | 正确答案的字母标签 |
answer_raw |
string | 答案的底层值 |
unit |
string | 单位(%, index, binary 等) |
year |
int | 年份字段 |
数据划分与规模
数据集按年份分为 28 个分片(splits),从 1999 到 2026。每个分片包含约 155 至 356 个问题样例。整个数据集大小为 2,871,732 字节。
覆盖的经济指标(共49个FRED系列)
| 类别 | 示例 |
|---|---|
| 通货膨胀 (8) | CPIAUCSL, CPILFESL, PCEPI, PCEPILFE, PPIACO, PPIFIS, DCOILWTICO, DCOILBRENTEU |
| 劳动力 (6) | UNRATE, PAYEMS, CIVPART, EMRATIO, AHETPI, ICSA |
| 经济增长 (4) | GDPC1, GDP, INDPRO, TCU |
| 利率 (8) | FEDFUNDS, DGS3MO, DGS2, DGS5, DGS10, DGS30, T10Y2Y, MORTGAGE30US |
| 货币 (4) | M2SL, BOGMBASE, TOTBKCR, CCSA |
| 消费 (5) | UMCSENT, PCE, PSAVERT, RSAFS, DSPI |
| 房地产 (3) | HOUST, PERMIT, CSUSHPINSA |
| 制造业 (3) | DGORDER, BOPGSTB, NEWORDER |
| 市场 (8) | SP500, NASDAQCOM, DJIA, VIXCLS, DTWEXBGS, DEXUSEU, DEXJPUS, DEXCHUS |
许可证
该数据集使用 CC-BY-4.0 许可证。基础的 FRED 数据属于公共领域。
搜集汇总
数据集介绍
构建方式
在金融时间序列预测领域,构建一个兼具历史深度与结构严谨性的基准数据集是评估模型泛化能力的关键。pre_test数据集基于FinDeepForecast基准框架,从美国联邦储备经济数据(FRED)中提取49项宏观经济与市场指标,覆盖1999年至2026年长达28年的历史区间。其构建严格遵循两轨分类法:递归轨道针对未来数值(如CPI、GDP、国债收益率)生成四选项多选题,信息截止日期设定在目标期前约60天;非递归轨道则围绕FOMC利率决议、CPI/NFP发布、GDP季度数据及周度市场阈值等预定义事件,采用八个模板生成二元是非题。每个样本包含qid、forecastType、indicator、transform、target_period等结构化字段,确保所有问题均能通过历史实现值进行验证。
特点
该数据集的核心价值在于其双重设计:一方面,8,437道问题(递归占75.5%,非递归占24.5%)通过年度划分形成28个独立子集,为跨时期评估提供了天然的时间序列分割;另一方面,其模板化生成机制确保了问题类型的标准化与可复现性。递归轨道涵盖level、yoy_pct、yoy_pp三种变换,非递归轨道则通过八个模板(如fomc_cut、cpi_release_threshold)紧密锚定现实经济事件日历。值得注意的是,非递归问题的正负样本分布反映了真实市场规律——例如FOMC决策中按兵不动占据主流,而周度市场阈值问题则保持近乎平衡。这种基于真实事件的结构化设计,使得数据集成为连接统计预测与事件驱动型金融推理的桥梁。
使用方法
研究者可通过HuggingFace Datasets库便捷加载该数据集,采用load_dataset('TheFinAI/pre_test', split='2008')即可获取单年度样本。灵活的过滤机制允许按forecastType字段分离递归与非递归任务,或通过subtype字段聚焦特定事件类型(如vix_weekly_spike)。对于递归任务,可直接使用四选项多选题格式进行交叉熵损失训练;非递归任务则简化为二元分类。年份分割特性支持留出法评估:例如以1999-2018年数据训练,2019-2026年数据测试,从而检验模型对历史模式的记忆与泛化边界。此外,info_cutoff时间戳字段为严格的时间序列截断提供了锚点,确保评估时不会引入未来信息。
背景与挑战
背景概述
在金融时间序列预测领域,大型语言模型(LLM)的应用方兴未艾,然而缺乏一个能够长期、系统评估模型预测能力的历史基准数据集。FinDeepForecast-Historical-US(亦称pre_test)由OpenFinArena团队于2026年创建,旨在填补这一空白。该数据集严格遵循FinDeepForecast论文的双轨分类法,涵盖1999年至2026年共28个年份,包含8,437道基于真实FRED(联邦储备经济数据)时间序列的预测问题。其核心研究问题聚焦于评估LLM在宏观经济与市场指标上的周期性数值预测(Recurrent)以及针对特定事件的二元判断(Non-Recurrent)能力。通过提供大规模、长跨度的历史标注数据,该数据集为金融时间序列预测的离线评估提供了坚实基础,推动了LLM在金融决策支持中的可复现性研究。
当前挑战
该数据集所面临的挑战首先体现在领域问题的复杂性上:金融时间序列预测需应对宏观经济数据的高噪声、非平稳性以及事件驱动的不确定性,例如FOMC利率决议、CPI发布等非重复事件难以通过单纯的历史模式建模。其次,在构建过程中,数据集需要从49个FRED指标中精确生成问题,并确保Recurrent问题中信息截止日期与目标期的合理间隔(约60天),同时维持Non-Recurrent问题(如VIX周度阈值、NASDA周涨幅)的YES/NO平衡,而实际FOMC决策中“维持不变”占主导,导致标签天然不均衡。此外,覆盖长达28年的时间跨度使得数据一致性、缺失值处理(如1999年部分指标晚于起始年)以及2026年部分年份的标签可验证性成为工程挑战。
常用场景
经典使用场景
作为面向宏观金融时间序列预测的标准化基准,该数据集以1999至2026年间源自FRED的49项美国宏观经济与市场指标为基底,构建了涵盖周期性数值预测与偶发性二元判断的双轨评测体系。其经典范式在于通过选择题形式评估语言模型对CPI、GDP、失业率等核心指标的季度或月度定量推测能力,同时以FOMC利率决议、非农数据超阈值等结构化事件检验模型对政策周期与市场情绪的二元判别水平,为金融预测领域的跨时间、跨指标泛化能力提供可复现的离线验证框架。
衍生相关工作
该基准的设计理念催生了多个方向的开创性工作:基于其‘周期性预测+二元事件’双轨架构衍生出FinDeepForecast-Live实时评测集,用于检验模型在未见未来数据下的泛化能力;其结构化事件模板被进一步扩展至全球多市场与公司级财务预测任务,形成了跨资产类别的大语言模型评测体系。此外,围绕该数据集的问答模式与信息截止点设计,学界提出了面向时间敏感检索增强生成的金融上下文压缩方法,推动了预训练模型在经济时序理解与知识时效性对齐方面的交叉研究。
数据集最近研究
最新研究方向
当前,金融时间序列预测与大语言模型的交叉研究正成为热点,尤其是在宏观经济指标前瞻与美联储政策预判领域。该数据集以1999至2026年间美国49个核心宏观与市场指标为根基,严格遵循可复现的周期性数值预测与基于特定事件的二元判断双轨分类体系,为评估LLM在真实数值推演与政策事件响应方面的能力提供了跨越近三十年的历史基准。其设计紧密关联美国关键经济数据释放日程与联邦公开市场委员会决策时点,可有效支撑模型在通胀、就业、利率等敏感议题上的时序推理与情境理解能力研究,进而推动AI在经济分析与金融预测领域的可靠性与实用性提升。
以上内容由遇见数据集搜集并总结生成


