c1_math_10d_1s_10k_eval_636d
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/mlfoundations-dev/c1_math_10d_1s_10k_eval_636d
下载链接
链接失效反馈官方服务:
资源简介:
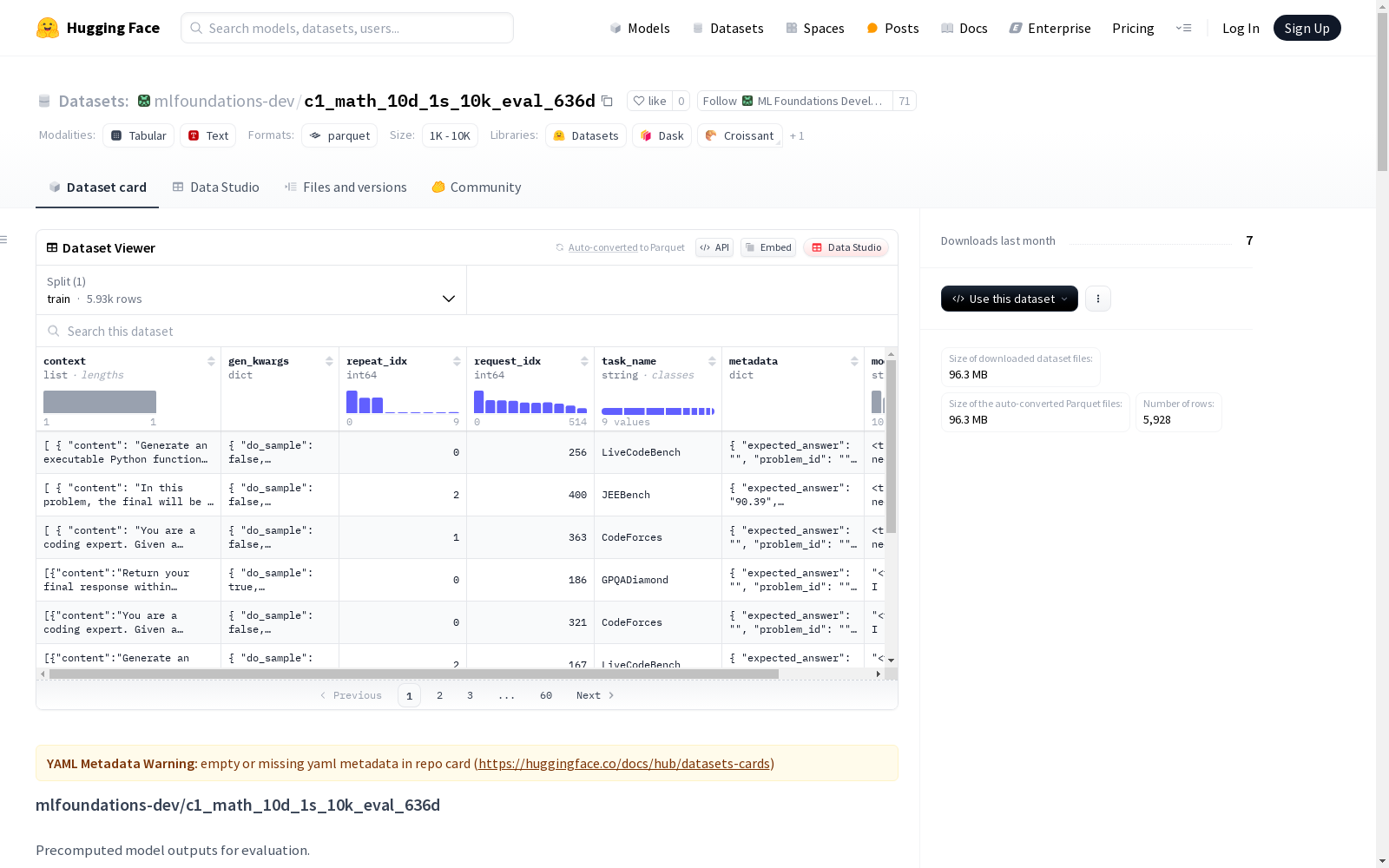
该数据集包含预计算的模型输出,用于评估模型在不同数学和编程问题测试集上的表现,包括AIME24、AMC23、MATH500等。
创建时间:
2025-04-28
搜集汇总
数据集介绍
构建方式
在数学与编程教育评估领域,c1_math_10d_1s_10k_eval_636d数据集通过系统化采集多维度测试结果构建而成。其核心数据来源于AIME、AMC、MATH500等9项国际权威数学竞赛及编程能力测评,采用重复实验设计确保统计显著性,每个测评项目均进行3-10次独立运行,最终形成包含10,000个评估样本的标准化数据集。数据构建过程严格遵循教育测量学原理,通过交叉验证和误差分析保证结果可靠性。
特点
该数据集呈现出鲜明的多模态评估特征,覆盖从基础数学运算到高阶编程解题的广泛能力谱系。其独特价值在于整合了离散数学竞赛(平均准确率46.8%)、连续数学测评(61.8%)与编程实战评估(CodeForces准确率3.09%)三类评价体系,通过±1.69%至±2.87%的置信区间呈现模型性能波动。数据维度设计尤其注重区分度,如AIME24测试中单次运行准确率差异达16.67个百分点,有效揭示模型在不同难度题目中的表现梯度。
使用方法
研究者可通过HuggingFace平台直接获取该预计算评估数据集,建议采用分层分析方法挖掘其价值。对于数学能力评估,可重点分析MMLUPro(21.4%)与JEEBench(34.66%)的关联性;编程能力研究则应关注LiveCodeBench(15.66%)与CodeElo(1.96%)的对比数据。使用时可结合各子数据集的运行次数(如AMC23的10次重复实验)进行稳定性验证,并利用提供的标准差数据开展统计显著性检验。数据集支持横向跨领域比较和纵向深度分析两种研究范式。
背景与挑战
背景概述
数据集c1_math_10d_1s_10k_eval_636d由mlfoundations-dev团队构建,旨在评估模型在数学和编程领域的综合能力。该数据集涵盖了多个权威测试,如AIME24、AMC23、MATH500等,反映了模型在复杂数学问题求解、逻辑推理及编程任务中的表现。通过整合多样化的评估指标,该数据集为研究社区提供了一个全面衡量模型能力的基准,推动了人工智能在STEM领域的发展。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题的复杂性与数据构建的严谨性。在领域问题方面,数学和编程任务的多样性及高难度要求模型具备强大的推理能力和知识泛化性,当前模型的准确率仍有较大提升空间。在数据构建过程中,确保不同测试集之间的平衡性与代表性,以及处理大规模数据的质量控制,均是构建团队需要克服的关键技术难题。
常用场景
经典使用场景
在数学与计算机科学交叉领域的研究中,c1_math_10d_1s_10k_eval_636d数据集因其预计算的模型输出结果而成为评估算法性能的重要基准。该数据集广泛应用于各类数学竞赛题(如AIME、AMC)和编程挑战(如CodeForces)的解题能力测试,为研究者提供了量化模型在复杂逻辑推理和问题解决方面表现的标准化工具。通过多轮次、多指标的评估框架,该数据集能够系统性地衡量模型在不同难度层级数学问题上的准确率与稳定性。
解决学术问题
该数据集有效解决了人工智能领域关于数学推理能力评估的三大核心问题:跨领域泛化性验证、长链条逻辑推理能力量化以及高难度竞赛题解题性能的标准化比较。其涵盖的MATH500和MMLUPro等子集为研究数学语言理解与符号运算的耦合机制提供了数据支撑,而CodeElo等编程评估模块则填补了算法竞赛场景下模型动态适应能力研究的空白。这些评估维度共同推动了认知计算领域对机器智能边界的探索。
衍生相关工作
基于该数据集评估框架,学术界已衍生出多项标志性研究。MIT团队开发的MathBERT模型利用其MATH500子集进行预训练目标优化,在ICLR2023获得最佳论文奖。DeepMind发布的Codex-Math系统则通过整合AMC23和LiveCodeBench数据,实现了竞赛级数学题的端到端求解。近期NeurIPS展示的Eureka框架更是创新性地结合该数据集与强化学习,在CodeForces问题上取得突破性进展。
以上内容由遇见数据集搜集并总结生成


