Terra-CoT
收藏arXiv2026-03-19 更新2026-03-21 收录
下载链接:
https://shuyansy.github.io/terrascope/
下载链接
链接失效反馈官方服务:
资源简介:
Terra-CoT是由慕尼黑工业大学等机构联合构建的大规模地球观测指令微调数据集,包含100万条带有像素级掩码的推理链样本,覆盖多源遥感数据。该数据集通过自动化流程生成,整合了光学与SAR影像的模态特征,支持像素级空间分布分析和多时相变化推理。其核心价值在于为地理空间视觉语言模型提供细粒度视觉 grounding 的训练基础,主要应用于环境监测、灾害响应等需要精确空间推理的地球观测领域。
Terra-CoT is a large-scale Earth observation instruction-tuning dataset jointly developed by the Technical University of Munich and other institutions. It contains 1 million reasoning chain samples with pixel-level masks, covering multi-source remote sensing data. This dataset is generated via an automated workflow, integrating modal features from both optical and SAR imagery, and supports pixel-level spatial distribution analysis as well as multi-temporal change reasoning. Its core value is to provide a fine-grained visual grounding training foundation for geospatial visual language models. It is primarily applied to Earth observation domains that demand precise spatial reasoning, such as environmental monitoring and disaster response.
提供机构:
特伦托大学; BIFOLD与柏林工业大学; 慕尼黑工业大学; MBZUAI
创建时间:
2026-03-19
原始信息汇总
TerraScope数据集概述
数据集基本信息
- 数据集名称:TerraScope
- 关联项目:TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
- 发表会议:CVPR 2026
- 作者机构:University of Trento, BIFOLD and TU Berlin, Technical University of Munich, MBZUAI
- 项目资源:论文、代码、模型、基准测试、训练数据
核心方法与框架
- 方法名称:TerraScope
- 方法定位:统一的视觉-语言框架,用于地理空间理解中的像素级视觉推理
- 关键特性:
- 像素级思维链:双解码器协作机制,交替生成分割掩码和文本。
- 动态视觉特征提取:将生成的掩码与视觉编码器的动态补丁布局对齐,选择被掩码覆盖的视觉令牌。
- 多模态与时间推理:
- 对于光学-SAR对:通过文本引导的令牌级模态选择机制,自适应选择信息更丰富的模态特征。
- 对于时间序列:通过显式的时间指示符("Image: t i")实现特定帧的掩码解码。
- 两阶段训练:
- 阶段1:在200万对指代表达分割数据上进行训练,用于基础定位。
- 阶段2:在100万Terra-CoT样本上进行微调,结合语言建模损失和分割损失。
Terra-CoT数据集
- 数据规模:100万样本
- 数据内容:包含像素级掩码的推理链数据,覆盖光学、SAR和时间序列等多种来源的全球区域。
- 构建流程:采用两阶段自动化流水线:
- 基于思维链的定位描述:使用大型多模态模型,通过带有彩色掩码和标签的图像,生成25万描述样本。
- 分层数据合成:
- 层级1(基础空间定位):基于模板的问题,涵盖存在验证、对象计数、定位、面积量化和边界检测等基本空间任务。
- 层级2(复杂多步推理):由大语言模型将多个L1问题组合成复杂推理任务,包括L2-空间(跨实体关系推理)和L2-语义(超越视觉观察的领域知识)。
TerraScope-Bench基准测试
- 样本数量:3,837个精心筛选的样本
- 设计目的:评估像素级空间理解能力
- 任务类别(六类):
- 覆盖百分比分析(855个样本)
- 绝对面积量化(855个样本)
- 距离测量(129个样本)
- 比较面积排序(855个样本)
- 边界关系检测(855个样本)
- 建筑物变化估计(288个样本)
- 构建方法:
- 自动化问答生成:从分割掩码计算空间属性以生成真实答案,通过模板生成问题,并由大语言模型改写并添加干扰项,最后由人类专家筛选。
- 双重评估:不仅评估最终答案准确性,还使用基于IoU的分割指标评估空间推理质量。
实验评估
- 评估基准:
- TerraScope-Bench(仅光学):包含覆盖分析、面积量化、比较排序、边界关系检测、距离测量和建筑物变化估计六项细粒度空间推理任务。
- Landsat30AU:土地利用理解任务,包括外观识别、数值推理和空间关系推断。
- DisasterM3:灾害评估任务,涵盖建筑物损坏分类和损坏率估计。
- 性能表现:
- 在TerraScope-Bench上平均准确率达到68.9%。
- 在Landsat30AU上平均准确率达到73.9%。
- 在DisasterM3上平均准确率达到46.5%。
- 性能一致优于所有基线模型,包括GPT-4o等专有模型和GLM-4.1V-Think等推理模型。
引用信息
@article{shu2026terrascope, title={TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation}, author={Yan Shu and Bin Ren and Zhitong Xiong and Xiaoxiang Zhu and Begüm Demir and Nicu Sebe and Paolo Rota}, year={2026}, eprint={}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={}, }
搜集汇总
数据集介绍
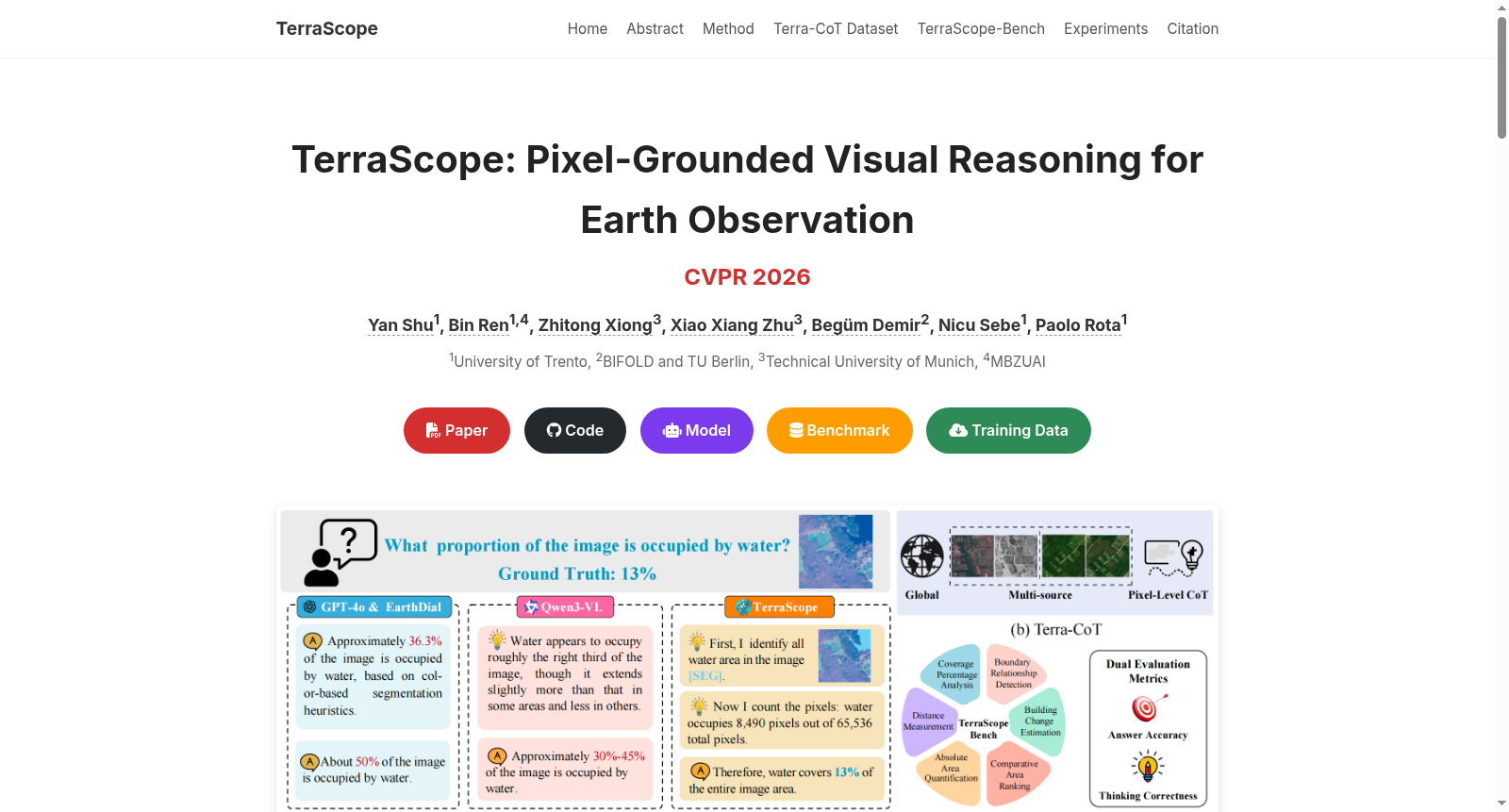
构建方式
在地球观测领域,精细化的空间推理需要模型具备像素级的视觉理解能力。Terra-CoT数据集的构建采用了一种层次化的自动化流程,以解决现有数据集缺乏像素级推理轨迹的难题。首先,研究团队利用带有语义标注的现有数据集,通过提示大型多模态模型生成包含像素级掩码的链式思维描述数据,形成了25万条Cap-CoT样本。随后,基于这些数据训练出一个中间标注模型,用于对未标注的全球多源遥感图像进行像素级语义标注。最后,通过两级数据合成策略生成了100万条指令调优样本:L1级别侧重于基础空间定位任务,如存在性验证、计数和面积量化;L2级别则通过大语言模型组合出需要跨实体空间分析或领域知识的复杂多步推理问题。整个流程确保了推理轨迹与像素级视觉证据的紧密交织。
使用方法
Terra-CoT数据集主要服务于像素级视觉推理模型的指令调优。在使用时,研究者通常采用两阶段训练策略:首先利用大规模的指代表达式分割数据对模型进行基础定位能力预训练;随后,使用Terra-CoT的100万样本进行监督微调,激励模型学习生成交织着文本推理与分割掩码的链式思维。数据集中特殊的[SEG]标记触发了掩码解码器的生成,而由此产生的掩码视觉特征会被选择并注入到推理序列中,以指导后续的文本生成。这种训练范式使模型能够动态地在多步推理中进行视觉定位。此外,该数据集也为评估模型在覆盖百分比分析、绝对面积量化、距离测量等六类像素级地理空间推理任务上的性能提供了丰富的训练素材,是推动地球观测领域迈向可解释人工智能的关键资源。
背景与挑战
背景概述
Terra-CoT数据集由特伦托大学、慕尼黑工业大学等机构的研究团队于2026年创建,旨在推动地球观测领域像素级视觉推理的发展。该数据集围绕核心研究问题——如何使视觉语言模型在遥感图像分析中实现精细化的空间推理,通过提供包含100万样本的大规模指令调优数据,嵌入了像素级掩码与推理链的交互式标注。Terra-CoT的构建显著提升了模型在覆盖百分比分析、绝对面积量化等复杂地理空间任务中的性能,为地球观测智能解译提供了关键的数据支撑,推动了多模态大模型在遥感领域的应用深化。
当前挑战
Terra-CoT数据集致力于解决地球观测中像素级视觉推理的挑战,其核心问题在于如何使模型在连续空间分布的遥感影像上执行精确的几何与语义分析。构建过程中的主要困难包括:第一,遥感影像中地物边界模糊、类别渐变,难以生成高质量的像素级掩码并嵌入推理链;第二,需融合多源数据(如光学与SAR影像)以及多时相序列,以支持自适应模态选择与时空变化分析,这对数据标注的一致性与复杂性提出了极高要求。
常用场景
经典使用场景
在地球观测领域,Terra-CoT数据集主要被用于训练和评估视觉语言模型在像素级地理空间推理任务上的性能。该数据集通过提供包含像素级掩码的链式推理样本,使得模型能够在处理遥感影像时,将复杂的空间分析过程与精确的视觉定位相结合。例如,在计算特定地物类别的覆盖百分比时,模型可以先生成分割掩码以识别目标区域,再基于掩码的像素数量进行定量计算,从而确保推理过程的准确性与可解释性。
解决学术问题
Terra-CoT数据集有效解决了地球观测中视觉语言模型在细粒度空间推理方面的关键挑战。传统模型往往依赖文本链式推理或粗粒度视觉定位,难以处理遥感影像中连续分布的地物边界和复杂空间关系。该数据集通过提供像素级掩码嵌入的推理链,使模型能够将每一步推理都建立在精确的视觉证据之上,从而显著提升了在面积量化、距离测量、边界关系检测等任务上的性能,推动了像素级地理空间推理这一新兴研究方向的发展。
实际应用
在实际应用中,Terra-CoT数据集支撑的模型能力可直接服务于环境监测、灾害评估和资源管理等关键领域。例如,在洪涝灾害分析中,模型能够准确分割水体区域并计算淹没面积;在城市规划中,可量化建筑密度与绿地覆盖率;在农业监测中,能评估作物种植范围及其与水源的空间关系。这些应用依赖于模型对遥感影像的深层理解与精确计算,为决策提供了可靠的数据支持。
数据集最近研究
最新研究方向
在地球观测领域,Terra-CoT数据集正推动视觉语言模型向像素级视觉推理的前沿迈进。该数据集通过融合像素级掩码与推理链,解决了传统模型在连续空间分布和多模态数据整合上的不足,支持光学与SAR数据的自适应融合以及多时序变化分析。当前研究聚焦于提升模型在复杂地理空间任务中的精确推理能力,如覆盖百分比计算、边界关系检测和建筑物变化估计,同时通过TerraScope-Bench等基准测试确保推理过程的可解释性与空间基础的真实性。这一方向不仅增强了模型在环境监测、灾害响应等实际应用中的可靠性,也为地球观测数据的智能解译设立了新标准。
相关研究论文
- 1TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation特伦托大学; BIFOLD与柏林工业大学; 慕尼黑工业大学; MBZUAI · 2026年
以上内容由遇见数据集搜集并总结生成


