Gargantua-R1-Compact
收藏Hugging Face2025-08-09 更新2025-08-10 收录
下载链接:
https://huggingface.co/datasets/prithivMLmods/Gargantua-R1-Compact
下载链接
链接失效反馈官方服务:
资源简介:
Gargantua-R1-Compact是一个大规模、高质量的推理数据集,主要设计用于数学推理和STEM教育。它包含了大约6.67百万个问题和解决方案追踪,重点放在数学(超过70%)、科学领域、算法挑战和创造性逻辑谜题上。该数据集适合用于训练和评估数学问题解决、竞技编程、科学计算和推理能力的模型。
创建时间:
2025-08-07
原始信息汇总
Gargantua-R1-Compact 数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签:
- 思考
- 代码
- 数学
- MLOps
- AI
- 科学
- 化学
- 生物
- 医学
- 数学推理
- 多样化科学领域
- 竞争性编程
- 学术科学
- 创意与分析推理
- MLOps/LLMs/diffusion/CUDA
- 图表转JSON
- 规模: 1M<n<10M
数据集简介
Gargantua-R1-Compact 是一个大规模、高质量的推理数据集,主要用于数学推理和STEM教育。包含约667万问题和解决方案,重点强调数学(超过70%),同时涵盖科学领域、算法挑战和创意逻辑谜题。
数据集组成
| 类别 | 百分比 | 描述 |
|---|---|---|
| 数学推理 | 73.93% | 核心数学问题、证明和计算挑战 |
| 多样化科学领域 | 12.11% | 物理、化学、生物和跨学科科学问题 |
| 竞争性编程 | 11.35% | 编程挑战、算法和数据结构问题 |
| 学术科学 | 1.37% | 研究级科学问题和方法论 |
| 创意与分析推理 | 0.95% | 逻辑谜题、分析思维和创意问题解决 |
| MLOps/LLMs/diffusion/CUDA | 0.25% | 机器学习操作和专业技术内容 |
| 图表数据转JSON | 0.06% | 数据可视化和结构化数据解释 |
数据集统计
- 总行数估计: 6.67M
- 完整大小估计: 144GB
- 数据集预览: 232,530行
- 预览大小: 2.23GB
数据来源
- 推理痕迹: 源自
prithivMLmods/Poseidon-Reasoning-5M - 数学推理: 源自
nvidia/open-math-reasoning - 自定义问题: 由 prithivMLmods 贡献
关键特性
数学卓越
- 全面覆盖从基础算术到高级数学概念
- 复杂数学问题的逐步推理
- 同一问题的多种解决方法
高质量推理痕迹
- 结构化解决方案
- 包含验证和检查机制
- 适合学习和理解的教育价值
多样化问题类型
- 纯数学
- 应用数学
- 科学应用
- 编码挑战
使用案例
主要应用
- 数学推理模型训练
- STEM教育
- 研究与开发
- 竞争性编程
次要应用
- 科学计算
- 学术评估
- 推理评估
数据集结构
json { "problem": "问题陈述或问题", "solution": "详细的逐步解决方案与推理痕迹", "category": "领域分类", "difficulty": "问题复杂度级别", "source": "问题来源" }
质量保证
数据管理
- 专家审查
- 解决方案验证
- 格式一致性
- 重复删除
推理质量
- 教育价值
- 多重验证
- 错误纠正
- 清晰标准
推荐使用
- 微调
- 评估
- 研究
- 教育
性能基准
- 数学问题解决准确性
- 逐步推理质量
- 多领域推理转移
- 竞争性编程性能
贡献
- 问题提交
- 解决方案审查
- 错误报告
- 领域扩展
引用
bibtex @misc{prithiv_sakthi_2025, author = { Prithiv Sakthi }, title = { Gargantua-R1-Compact (Revision 522d6fb) }, year = 2025, url = { https://huggingface.co/datasets/prithivMLmods/Gargantua-R1-Compact }, doi = { 10.57967/hf/6176 }, publisher = { Hugging Face } }
限制与考虑
已知限制
- 主要为英语内容
- 领域偏向数学推理
- 问题可能反映特定教育背景
- 类别内难度级别不同
伦理考虑
- 不应用于完成学术作业
- 应意识到问题选择中的潜在偏见
- 遵循学术和研究伦理指南
许可证
Apache 2.0 许可证,允许商业和非商业使用,需适当署名。
版本历史
- v1.0: 初始发布,667万推理痕迹
- 预览: 232K样本用于评估和测试
| 维护者 | 最后更新 |
|---|---|
| prithivMLmods | 2025年8月 |
搜集汇总
数据集介绍
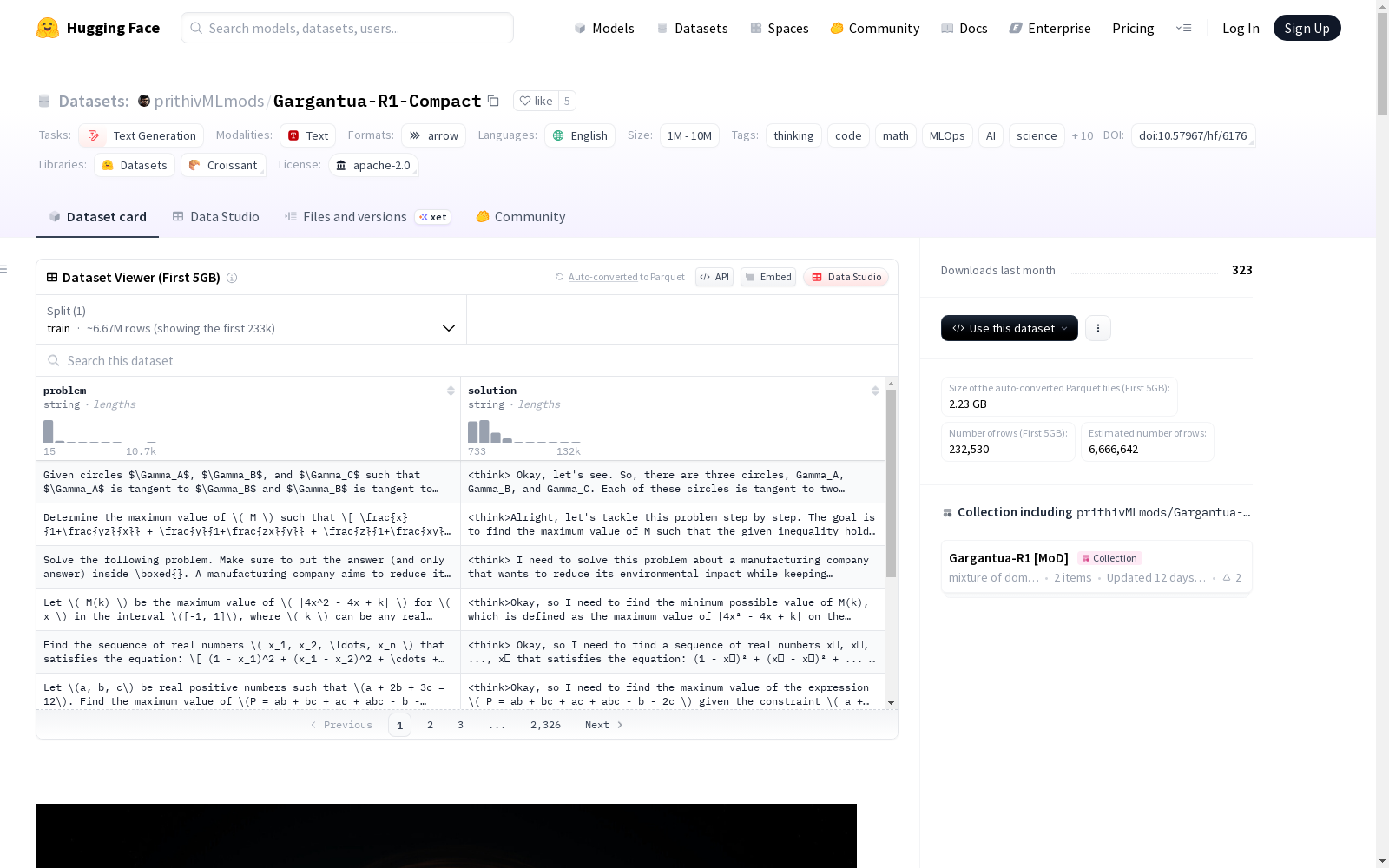
构建方式
在人工智能与科学计算领域,高质量数据集的构建对于推动模型推理能力的发展至关重要。Gargantua-R1-Compact数据集通过整合多个权威来源精心构建,主要包括来自prithivMLmods/Poseidon-Reasoning-5M的推理轨迹、nvidia/open-math-reasoning的数学推理数据以及大量自定义模块化问题。构建过程中采用了专家评审机制,所有数学解均经过严格验证,并实施了系统化的去重和格式标准化流程,确保数据的一致性与可靠性。
特点
该数据集在科学推理与教育应用领域展现出显著特色,其核心优势体现在数学推理内容占比超过73%,覆盖从基础算术到高等数学的广泛范畴。数据集提供逐步推理的详细解题轨迹,支持多种解题方法,并延伸至物理、化学、生物等科学领域及竞争性编程问题。每个条目均包含问题陈述、结构化解决方案、领域分类及难度评级,兼具教育解释性与机器可读性。
使用方法
研究人员可通过Hugging Face平台快速加载该数据集,使用datasets库中的load_dataset函数直接访问。数据集适用于数学推理模型的微调训练、STEM教育系统的开发、竞争性编程能力的评估以及科学计算任务的支持。典型应用场景包括自动化评分系统、学术研究基准测试及教育型人工智能工具的构建,使用者需遵循Apache 2.0许可协议并注意数据以英文为主的语言特性。
背景与挑战
背景概述
Gargantua-R1-Compact数据集由Prithiv Sakthi于2025年构建并发布,是一个专注于数学推理与STEM教育的大规模高质量数据集。该数据集包含约667万条问题与解答轨迹,其中数学推理内容占比超过73%,同时涵盖科学计算、算法挑战及逻辑推理等多个领域。其核心研究问题在于提升人工智能模型在复杂数学问题求解、多步骤推理及跨学科应用中的能力,对推动教育智能化与科学计算自动化具有显著影响力。
当前挑战
该数据集旨在解决数学推理与科学计算中模型泛化能力不足、多步骤逻辑链条断裂及跨领域知识融合困难等核心问题。构建过程中面临高质量推理轨迹的规模化生成、多源异构数据的标准化整合、数学解法的严格验证以及教育价值与计算效率的平衡等挑战,需通过专家审核、去重校验及结构化标注等技术手段确保数据质量与一致性。
常用场景
经典使用场景
在数学推理与STEM教育领域,Gargantua-R1-Compact数据集被广泛用于训练和评估大语言模型的复杂问题解决能力。其包含的670万条高质量推理轨迹,覆盖了从基础算术到高等数学的完整谱系,支持模型学习多步骤逻辑推演和跨学科知识整合。该数据集特别适用于数学定理证明、算法设计竞赛题解以及科学计算任务的自动化处理,为研究型模型提供了标准化的训练范式。
实际应用
实际应用中,该数据集已成为智能教育系统的核心训练资源,驱动AI助教系统实现数学题目的自动解答与步骤讲解。在工业界,其支持的模型被集成至编程竞赛平台提供实时解题辅助,亦应用于科研机构的科学计算自动化流程。医疗和工程领域则利用其生物建模与物理计算模块加速专业问题的求解效率,形成产学研联动的技术落地生态。
衍生相关工作
基于该数据集衍生的经典工作包括MathReasoner系列模型,其在MATH基准测试中刷新了数学推理准确率记录。开源项目EduGPT利用其训练教育专用大模型,实现了自适应学习路径推荐。多项国际竞赛优胜方案均采用该数据集的增强版本进行训练,相关研究论文已发表于NeurIPS、ICML等顶级会议,推动形成了机器推理研究的新范式。
以上内容由遇见数据集搜集并总结生成


