园区智慧封闭场景车型图像识别AI训练数据
收藏浙江省数据知识产权登记平台2025-04-03 更新2025-04-04 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/121849
下载链接
链接失效反馈官方服务:
资源简介:
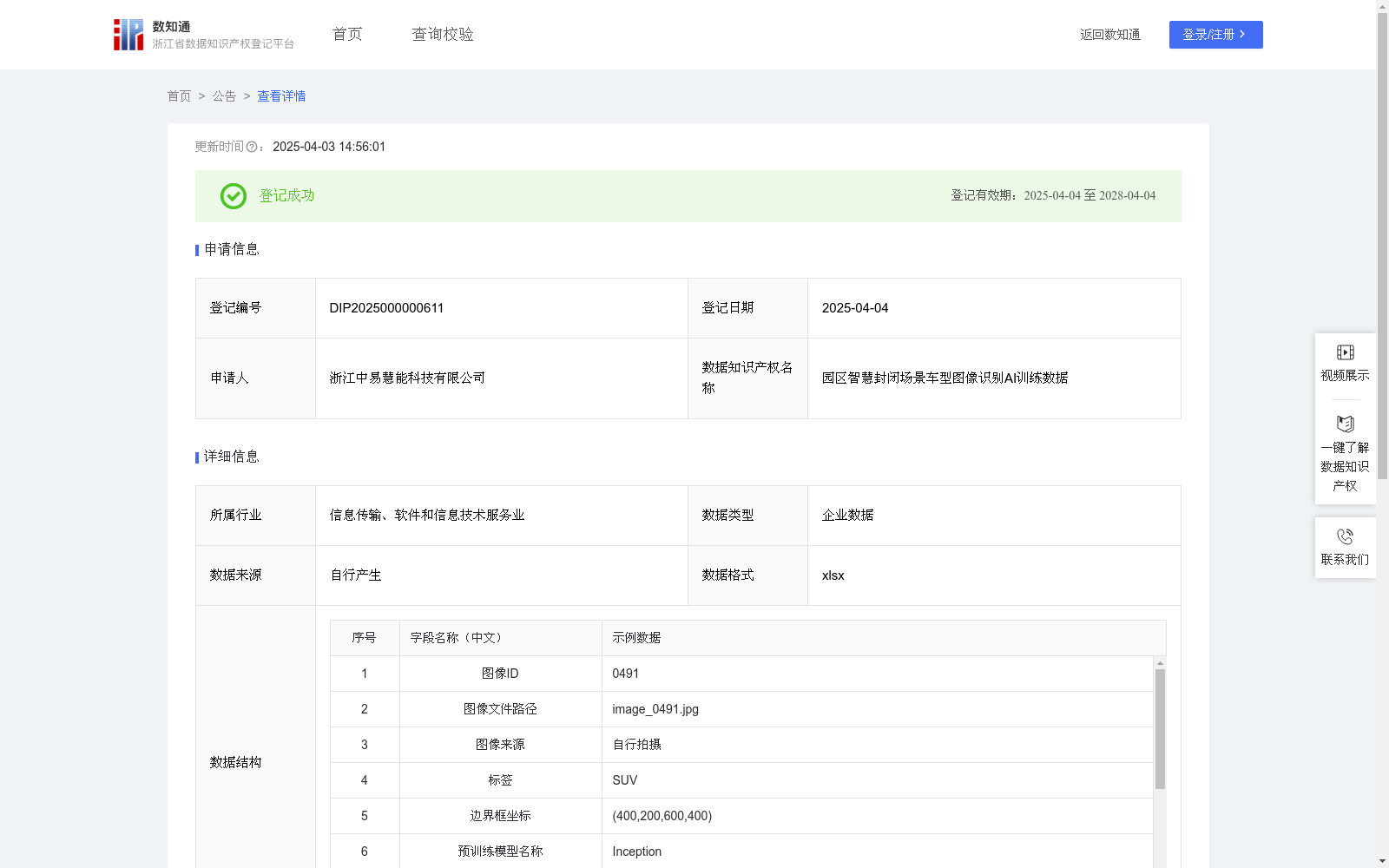
本训练数据主要应用于提升AI模型在园区智慧封闭场景中对车型的识别能力和识别准确度。通过这些数据的训练,AI模型可以更准确地识别轿车、SUV、卡车等车型,从而胜任在园区交通管理、安全监控预防、商业分析等方面的应用。此外,超参数的应用进一步提升了模型的泛化能力和鲁棒性,使得AI模型在处理不同光照、天气和背景条件下的车型图像时,具有更好的泛化能力和适应性。一、数据的生产方式和地址
1.原始图像数据来源于自行拍摄或算法生成,对原始图像的ID、文件路径进行记录。
2.数据预处理与标注:根据自身项目需求和模型要求,将园区出入车型图像数据分为训练集和测试集。对训练集图像中的车型进行标注,形成标签和边界框坐标。
3.模型选择与初始化:选择Inception预训练模型,并初始化模型参数。设置合理的超参数,如学习率、批量大小等,以优化模型的训练过程。
4.模型训练:使用EfficientNet深度学习框架加载和初始化模型。将准备好的训练集输入到模型中进行训练。在训练过程中,模型会不断调整权重,以最小化预测框与真实框之间的差值。对训练时长和训练周期(迭代次数)进行记录。
5.模型评估:在训练完成后,使用测试集对模型进行评估。计算模型在不同场景下的精度、召回率、F1分数等指标,确保模型的准确性和鲁棒性。最终训练、测试后得到的模型可直接应用到具体的项目中。
二、数据的生产数量和质量
本数据预计每年产生1万余条,数据采集后经过严格的清洗过程,数据质量优异。
This training dataset is primarily designed to enhance the vehicle type recognition capability and accuracy of AI models in intelligent closed campus scenarios. Through training on this dataset, AI models can accurately identify various vehicle types including sedans, SUVs, and trucks, thereby enabling deployment in applications such as campus traffic management, safety monitoring and prevention, and business analysis. Furthermore, the application of hyperparameters further improves the model's generalization ability and robustness, allowing the AI model to achieve better generalization and adaptability when processing vehicle images under varying lighting, weather, and background conditions.
I. Data Production Methods and Storage Paths
1. Original image data is sourced from self-shot photography or algorithmic generation, with the ID and file path of each original image recorded.
2. Data Preprocessing and Annotation: According to the requirements of the specific project and the target model, the vehicle type image data collected at campus entrances and exits are divided into training set and test set. The vehicle types in the training set images are annotated to generate corresponding labels and bounding box coordinates.
3. Model Selection and Initialization: A pre-trained Inception model is selected, and its parameters are initialized. Reasonable hyperparameters such as learning rate and batch size are set to optimize the model training workflow.
4. Model Training: The EfficientNet deep learning framework is utilized to load and initialize the model. The prepared training dataset is fed into the model for training. Throughout the training process, the model continuously adjusts its weights to minimize the discrepancy between predicted bounding boxes and ground-truth bounding boxes. The training duration and total number of iterations are recorded.
5. Model Evaluation: Upon completion of training, the test dataset is used to evaluate the model's performance. Metrics including precision, recall, and F1-score across different scenarios are calculated to validate the model's accuracy and robustness. The final trained and tested model can be directly deployed to specific project applications.
II. Data Volume and Quality
This dataset is projected to generate over 10,000 samples annually. Following strict data cleaning procedures post-collection, the dataset boasts excellent overall quality.
提供机构:
浙江中易慧能科技有限公司
创建时间:
2025-02-07
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于园区智慧封闭场景车型图像识别的AI训练数据集,包含524条记录,每日更新,数据格式为xlsx。数据集涵盖了图像ID、文件路径、标签、边界框坐标等多种信息,旨在提升AI模型在车型识别方面的准确度和泛化能力。
以上内容由遇见数据集搜集并总结生成


