TheFinAI/fiqa-sentiment-classification
收藏Hugging Face2024-03-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TheFinAI/fiqa-sentiment-classification
下载链接
链接失效反馈官方服务:
资源简介:
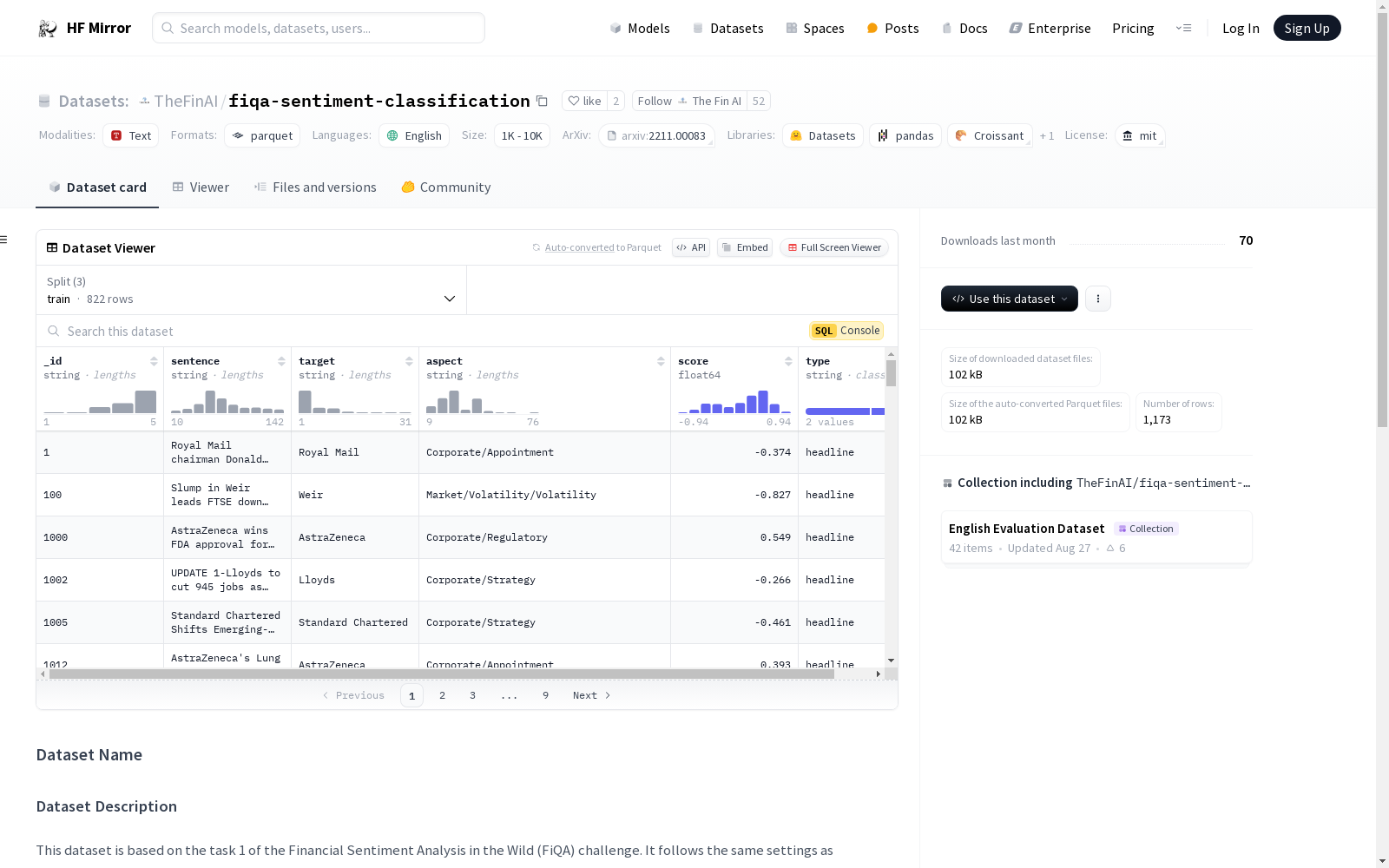
该数据集基于FiQA挑战赛的任务1,遵循了论文《A Baseline for Aspect-Based Sentiment Analysis in Financial Microblogs and News》中的设置。数据集分为三个子集:训练集、验证集和测试集,大小分别为822、117和234。数据集的特征包括ID、句子、情感目标、情感方面、情感分数和数据类型。
This dataset is based on Task 1 of the FiQA Challenge, following the experimental setup described in the paper *A Baseline for Aspect-Based Sentiment Analysis in Financial Microblogs and News*. It is divided into three subsets: training set, validation set, and test set, with sizes of 822, 117, and 234 respectively. The features of this dataset include ID, sentence, sentiment target, sentiment aspect, sentiment score, and data type.
提供机构:
TheFinAI
原始信息汇总
数据集名称
数据集描述
该数据集基于金融情感分析挑战(FiQA)中的任务1。它遵循与论文《金融微博客和新闻中基于方面的情感分析基线》相同的设置。数据集分为三个子集:训练集、验证集和测试集,大小分别为822、117和234。
数据集结构
_id: 数据点的IDsentence: 句子target: 情感的目标aspect: 情感的方面score: 情感分数type: 数据点的类型(标题或帖子)
数据集信息
- 特征:
_id: 字符串sentence: 字符串target: 字符串aspect: 字符串score: 浮点数type: 字符串
- 分割:
train: 119567字节, 822个样本valid: 17184字节, 117个样本test: 33728字节, 234个样本
- 下载大小: 102225字节
- 数据集大小: 170479字节
搜集汇总
数据集介绍
构建方式
TheFinAI/fiqa-sentiment-classification数据集源自金融情感分析领域的FiQA挑战任务1,严格遵循'A Baseline for Aspect-Based Sentiment Analysis in Financial Microblogs and News'论文中的设置。该数据集通过精心筛选和标注,涵盖了金融领域的微博客和新闻文本,旨在提供高质量的情感分析训练和测试数据。数据集被划分为训练集、验证集和测试集,分别包含822、117和234个样本,确保了模型训练和评估的全面性和准确性。
特点
该数据集的显著特点在于其专注于金融领域的情感分析,涵盖了多种金融相关文本类型,如新闻标题和社交媒体帖子。每个样本不仅包含文本内容,还详细标注了情感目标、情感方面和情感评分,为深入的情感分析提供了丰富的信息。此外,数据集的结构设计合理,便于研究人员和开发者快速上手,进行高效的模型训练和评估。
使用方法
使用TheFinAI/fiqa-sentiment-classification数据集时,用户可通过HuggingFace的datasets库进行加载,并将其保存为CSV格式以便进一步处理。具体操作包括调用load_dataset函数加载数据集,随后使用to_csv方法将各子集保存为独立的CSV文件。这种灵活的数据加载和保存方式,使得该数据集适用于各种基于情感分析的机器学习和深度学习模型训练。
背景与挑战
背景概述
在金融领域,情感分析的准确性对于理解市场情绪和预测金融趋势至关重要。TheFinAI/fiqa-sentiment-classification数据集正是基于这一需求而创建,旨在解决金融文本中的情感分类问题。该数据集源自Financial Sentiment Analysis in the Wild (FiQA)挑战的任务1,由主要研究人员或机构根据'A Baseline for Aspect-Based Sentiment Analysis in Financial Microblogs and News'论文中的设置构建。数据集包含822个训练样本、117个验证样本和234个测试样本,涵盖了金融微博客和新闻中的情感分析。通过提供详细的情感评分和目标信息,该数据集为研究人员提供了一个标准化的基准,以评估和改进金融领域的情感分析模型。
当前挑战
尽管TheFinAI/fiqa-sentiment-classification数据集在金融情感分析领域具有重要意义,但其构建和应用过程中仍面临若干挑战。首先,金融文本的复杂性和专业性要求模型具备高度的语义理解和上下文解析能力。其次,数据集的规模相对较小,可能限制了模型的泛化能力和性能。此外,金融领域的情感表达往往较为隐晦,如何准确捕捉和量化这些情感是一个持续的挑战。最后,数据集的构建过程中,如何确保样本的代表性和平衡性,以及如何处理噪声和异常值,也是需要解决的关键问题。
常用场景
经典使用场景
在金融领域,TheFinAI/fiqa-sentiment-classification数据集被广泛用于情感分类任务。该数据集通过分析金融微博客和新闻中的句子,提取出目标、方面和情感分数,为研究人员提供了一个标准化的基准。其经典使用场景包括构建和评估金融文本情感分析模型,特别是在处理多方面情感分析时,该数据集展现了其独特的优势。
解决学术问题
该数据集解决了金融领域中情感分析的学术研究问题,特别是在多方面情感分析和细粒度情感分类方面。通过提供结构化的金融文本数据,它帮助研究人员开发和验证新的情感分析算法,从而推动了金融情感分析技术的发展。此外,该数据集的引入为金融领域的情感分析研究提供了标准化的基准,促进了相关研究的深入和广泛应用。
衍生相关工作
基于TheFinAI/fiqa-sentiment-classification数据集,许多相关研究工作得以展开。例如,有研究者利用该数据集开发了新的情感分析模型,提升了金融文本情感分类的准确性。此外,该数据集还激发了关于金融情感分析的跨领域研究,如结合自然语言处理和机器学习技术,探索更复杂的情感分析方法。这些衍生工作不仅丰富了金融情感分析的理论基础,也推动了实际应用的创新。
以上内容由遇见数据集搜集并总结生成


