Omni-MATH
收藏魔搭社区2026-05-23 更新2024-09-28 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/Omni-MATH
下载链接
链接失效反馈官方服务:
资源简介:

# Dataset Card for Omni-MATH
<!-- Provide a quick summary of the dataset. -->
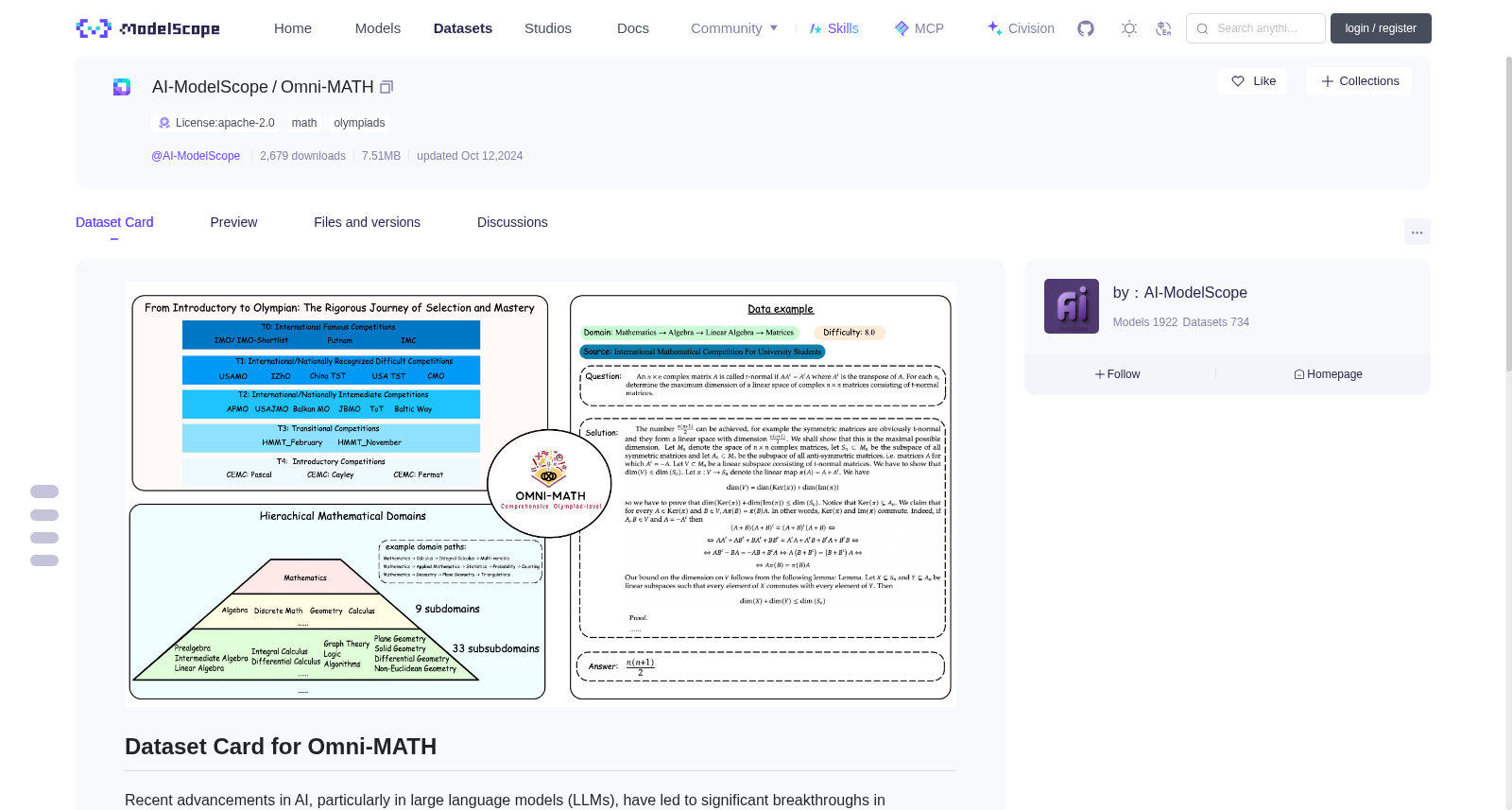
Recent advancements in AI, particularly in large language models (LLMs), have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To mitigate this limitation, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems. These problems are meticulously categorized into 33 (and potentially more) sub-domains and span across 10 distinct difficulty levels, enabling a nuanced analysis of model performance across various mathematical disciplines and levels of complexity.
* Project Page: https://omni-math.github.io/
* Github Repo: https://github.com/KbsdJames/Omni-MATH
* Omni-Judge (opensource evaluator of this dataset): https://huggingface.co/KbsdJames/Omni-Judge
## Dataset Details
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
```python
from datasets import load_dataset
dataset = load_dataset("KbsdJames/Omni-MATH")
```
For further examination of the model, please refer to our github repository: https://github.com/KbsdJames/Omni-MATH
## Citation
If you find our code and dataset helpful, welcome to cite our paper.
```
@misc{gao2024omnimathuniversalolympiadlevel,
title={Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models},
author={Bofei Gao and Feifan Song and Zhe Yang and Zefan Cai and Yibo Miao and Qingxiu Dong and Lei Li and Chenghao Ma and Liang Chen and Runxin Xu and Zhengyang Tang and Benyou Wang and Daoguang Zan and Shanghaoran Quan and Ge Zhang and Lei Sha and Yichang Zhang and Xuancheng Ren and Tianyu Liu and Baobao Chang},
year={2024},
eprint={2410.07985},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.07985},
}
```

# Omni-MATH 数据集卡片
<!-- 提供数据集的快速摘要。 -->
人工智能领域的近期进展,尤其是大语言模型(Large Language Model),在数学推理能力方面取得了显著突破。然而,诸如GSM8K、MATH这类现有基准测试如今已能被模型以高精度求解(例如OpenAI o1在MATH数据集上的准确率可达94.8%),这表明此类基准已无法对现有模型形成有效的挑战性测试。为缓解这一局限,我们构建了一款兼具全面性与挑战性的基准测试,专为评估大语言模型的奥林匹克竞赛级数学推理能力而设计。与现有奥林匹克竞赛相关的基准测试不同,本数据集仅聚焦数学领域,共收录4428道竞赛级题目。这些题目被精细划分为33个(或更多)子领域,并覆盖10个不同的难度层级,可实现对模型在不同数学学科与复杂度层级上的性能进行精细化分析。
* 项目主页:https://omni-math.github.io/
* Github 仓库:https://github.com/KbsdJames/Omni-MATH
* Omni-Judge(本数据集的开源评估工具):https://huggingface.co/KbsdJames/Omni-Judge
## 数据集详情
## 使用方法
<!-- 阐述该数据集的预期使用场景。 -->
python
from datasets import load_dataset
dataset = load_dataset("KbsdJames/Omni-MATH")
如需进一步对模型性能进行测试,请参阅我们的Github仓库:https://github.com/KbsdJames/Omni-MATH
## 引用
若您认为本代码与数据集对您的研究有所帮助,欢迎引用我们的论文。
@misc{gao2024omnimathuniversalolympiadlevel,
title={Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models},
author={Bofei Gao and Feifan Song and Zhe Yang and Zefan Cai and Yibo Miao and Qingxiu Dong and Lei Li and Chenghao Ma and Liang Chen and Runxin Xu and Zhengyang Tang and Benyou Wang and Daoguang Zan and Shanghaoran Quan and Ge Zhang and Lei Sha and Yichang Zhang and Xuancheng Ren and Tianyu Liu and Baobao Chang},
year={2024},
eprint={2410.07985},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.07985},
}
提供机构:
maas
创建时间:
2024-09-26
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


